
25 лет спустя: краткий анализ эффективности GPU
Первые 3D-видеокарты появились 25 лет назад, и с тех пор их мощность и сложность выросли в таком масштабе, как ни один другой чип компьютера. В те времена графические процессоры были меньше 100 мм2 размером, имели около 1 миллиона транзисторов и потребляли всего несколько ватт энергии.
Сегодня же типичная видеокарта может иметь 14 миллиардов транзисторов на кристалле размером 500 мм2 и потреблять более 200 Вт энергии. Возможности этих бегемотов будут неизмеримо больше, чем у их древних предшественников, но стали ли они эффективнее со всеми этими транзисторами и ваттами энергии?
Сказка о Двух Числах
В этой статье мы рассмотрим, насколько хорошо разработчики GPU смогли воспользоваться увеличением размеров кристалла и энергопотребления, чтобы предложить нам больше вычислительной мощности. Прежде чем идти дальше, вы можете освежить в памяти устройство видеокарты или пройтись по истории современного GPU. С этой информацией вам будет легче ориентироваться.
Чтобы понять, как менялась эффективность графического процессора, и менялась ли вообще, мы использовали отличную базу данных TechPowerUp, выбрав образцы процессоров за период последних 14 лет. Такой период обусловлен тем, что именно 14 лет назад GPU перешли на унифицированную структуру шейдеров.
Вместо того чтобы выделять отдельные вычислительные блоки процессора для обработки треугольников и пикселей, унифицированные шейдеры являются арифметическими логическими единицами, предназначенными для любых вычислений, связанных с трехмерной графикой. Благодаря этому, мы можем последовательно замерить относительную производительность каждого GPU по параметру количества его операций с плавающей точкой в секунду (FLOPS – FLoating-point Operations Per Second).
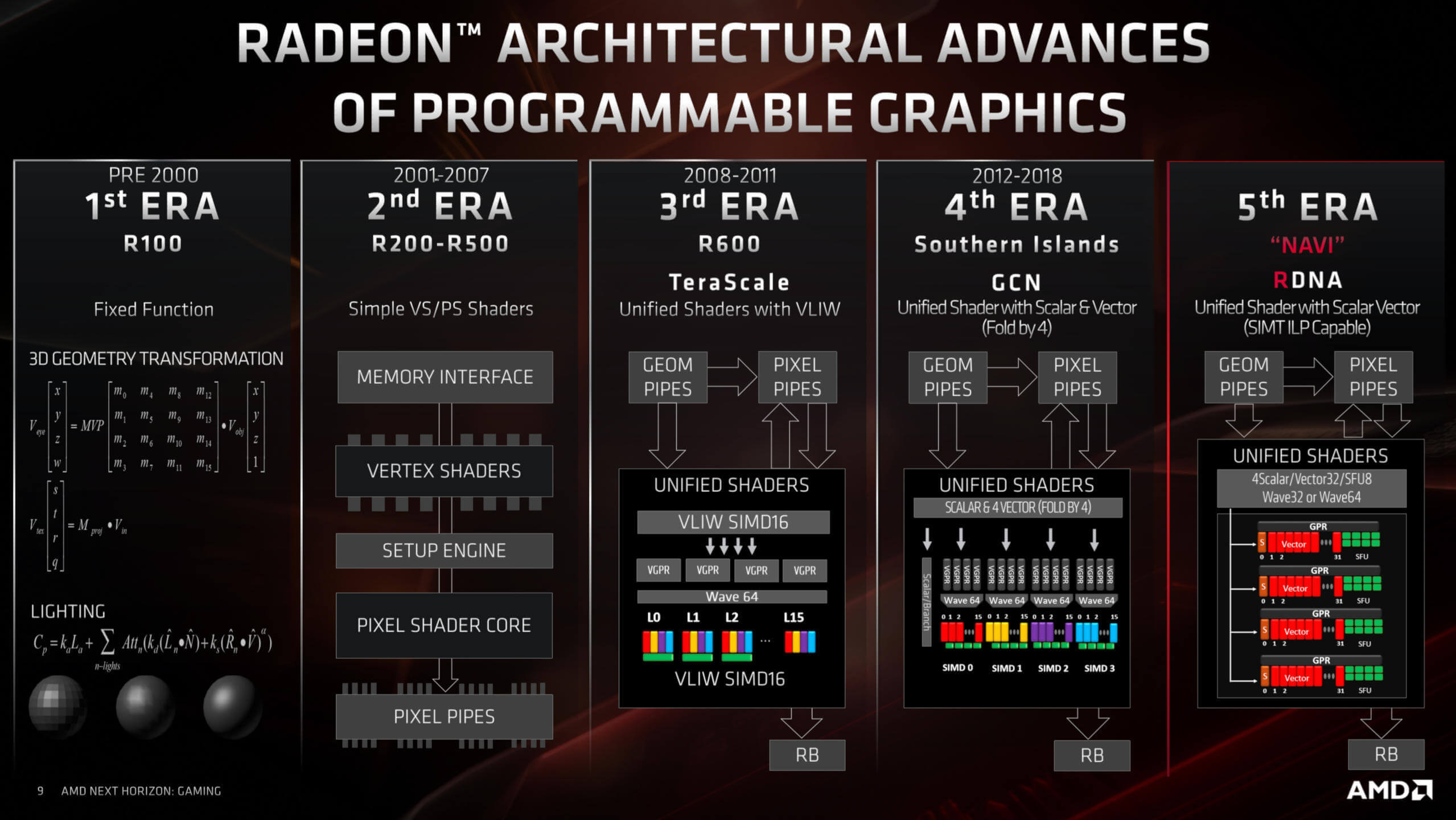
AMD использует унифицированную шейдерную архитектуру почти 12 лет
Вендоры часто стараются указывать значения FLOPS в качестве показателя максимальной производительности GPU. И хотя на самом деле это далеко не единственный показатель, определяющий скорость работы графического процессора, FLOPS дает нам цифры, с которыми мы можем работать.
То же касается и размеров кристалла, означающего рабочую площадь чипа. Однако чипы могут быть одинаковы по размеру, но сильно отличаться по количеству транзисторов.
Например, процессор Nvidia G71 (GeForce 7900 GT) 2005 года имеет размер 196 мм2 и имеет 278 миллионов транзисторов, а TU117, выпущенный в начале прошлого года (GeForce GTX 1650), всего лишь на 4 мм2 больше, но в нём 4,7 миллиарда этих маленьких переключателей.
Диаграмма основных GPU Nvidia, показывающая изменения в плотности транзисторов за последние годы

Источник изображения:
techspot.com
Естественно, из этого следует, что современные транзисторы намного меньше, чем в старых чипах, и это очень важно. Так называемый технологический процесс – общая разрешающая способность при изготовлении процессора, – используемый производителями оборудования, с годами менялся и постепенно становился все меньше и меньше. Поэтому мы проанализируем эффективность с точки зрения плотности кристалла, которая является мерой того, сколько миллионов транзисторов приходится на один мм2 площади кристалла.
Пожалуй, самым спорным показателем, который мы будем использовать, является показатель энергопотребления GPU. Многие читатели отнесутся скептически, ведь мы используем значение теплопакета (TDP), заявленное производителем. На самом деле это значение отражает (или, по крайней мере, должно отражать) количество тепла, выделяемого в среднем всей видеокартой при высокой нагрузке.
Потребляемая кремниевыми чипами энергия действительно в основном превращается в тепло, но проблема использования TDP не в этом. Дело в том, что разные вендоры указывают это число при разных условиях, не обязательно во время пиковых FLOPS. Кроме того, это значение мощности для всей видеокарты в целом, включая встроенную память, а не только для основного её потребителя – собственно GPU. Можно измерить энергопотребление видеокарты напрямую, как это делали, например, TechPowerUp для своих обзоров GPU. Когда они тестировали GeForce RTX 2080 Super с заявленным производителем TDP 250 Вт, они обнаружили, что энергопотребление в среднем составило 243 Вт, и достигло максимума в 275 Вт во время тестирования.
Но всё-же мы решили учитывать показатель TDP в нашем анализе ради простоты и удобства, условившись весьма осторожно делать любые выводы касаемо производительности, основанные исключительно на её зависимости от номинальной тепловой мощности.
Сейчас мы проведем прямое сравнение по двум показателям: GFLOPS и плотность кристалла. Один GFLOPS равен 1000 миллионам операций с плавающей точкой в секунду, и мы имеем дело со значением для вычислений одинарной точности (FP32), выполняемых исключительно унифицированными шейдерами. Наше сравнение примет форму графика:

Источник изображения: techspot.com
Ось X отображает GFLOPS на единицу TDP – чем больше, тем лучше. Чем меньше, тем нерациональней используется энергопотребление. То же справедливо для оси Y, где у нас GFLOPS на единицу плотности кристалла. Чем больше транзисторов удастся поместить на один квадратный мм, тем выше получится производительность. Таким образом, общая эффективность работы GPU (учитывая количество транзисторов, размер кристалла и TDP) возрастает по мере приближения к правому верхнему углу графика.
Все значения в районе верхнего левого угла в основном говорят о том, что «благодаря вычислительной мощности кристалла, этот GPU обеспечивает хорошую производительность, но за
счет использования относительно большого количества энергии». Идем к правому нижнему углу, и там у нас будут GPU, которые «очень энергоэффективные, но сравнительно слабенькие».
Короче говоря, мы оцениваем эффективность работы GPU исходя из его потребляемой мощности пропорционально количеству транзисторов.
Эффективность GPU: TDP vs количество транзисторов
Церемониться мы не будем, вот результаты:
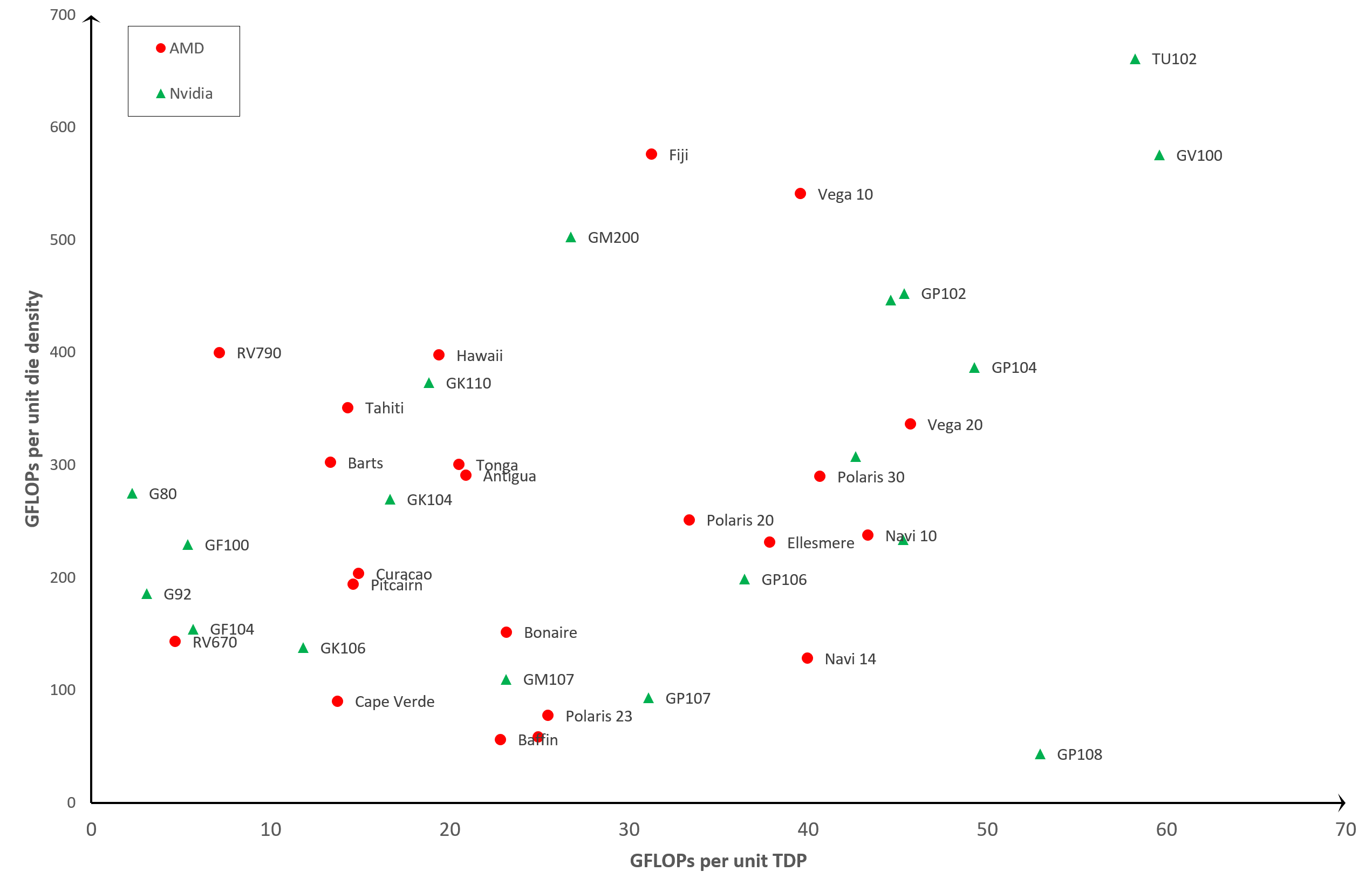
Источник изображения: techspot.com
Мы видим, что результаты довольно разбросанные, но имеют базовую закономерность: старые графические процессоры, такие как G80 или RV670, гораздо менее эффективны по сравнению с более современными решениями, такими как Vega 20 или GP102. Оно и понятно. В конце концов, чего бы стоили команды инженеров-электронщиков, изо всех сил старающихся постоянно создавать новые продукты, которые становились бы всё менее эффективными с каждым выпуском.
Но некоторые результаты представляют особый интерес. Прежде всего, это TU102 и GV100. Оба чипа сделаны Nvidia и используются в видеокартах GeForce RTX 2080 Ti и Titan V, соответственно.

Можно возразить, что ни один из них не был разработан для общепотребительского рынка. Особенно это касается GV100, поскольку он действительно предназначен для рабочих станций и вычислительных серверов. Поэтому, хотя они и являются самыми эффективными из всех процессоров, но они предназначены для специализированных рынков и стоят намного дороже стандартных.
Еще один GPU, который выделяется как белая ворона – это GP108. Этот чип от Nvidia чаще всего встречается в GeForce GT 1030 – недорогом продукте, выпущенном в 2017 году, и имеющем очень маленький размер. Процессор размером всего 74 мм2 с TDP всего 30 Вт. Однако его относительная производительность с плавающей точкой на самом деле не лучше, чем у Nvidia G80 – первого GPU с унифицированной шейдерной архитектурой (2006).

Графический процессор Nvidia G80. Источник
По другую сторону от GP108 находится чип AMD Fiji, который использовался в серии Radeon R9 Fury. Это получилось не слишком энергоэффективное решение, особенно учитывая, что использование HBM-памяти должно было помочь в этом отношении. Фиджи сильно греется, что плохо сказывается на экономичности полупроводников из-за возросшей утечки. Именно здесь потребляется электрическая энергия, а не в схеме как таковой. Все чипы имеют токи утечки, но с температурой скорость потерь увеличивается.
Но самым интересным моментом является, пожалуй, Navi 10. Это новейший GPU от AMD, производимый TSMC на их передовом 7-нм техпроцессе. В то же время, Vega 20 произведён на том же техпроцессе почти два года назад, но выглядит более эффективным. В чём же дело?

Под этими вентиляторами стоит GPU Vega 20.
Источник
Vega 20 (AMD использовала его только в одной потребительской видеокарте – Radeon VII) был последним процессором, созданным AMD в архитектуре GCN (Graphics Core Next). Она объединяет огромное количество унифицированных шейдерных ядер в единый узел, в котором основное внимание уделено формату FP32. Однако программирование устройства для достижения этой производительности было нелегким делом, и ему не хватало гибкости.
Navi 10 использует новейшую архитектуру RDNA, которая решает эту проблему. Решение новое, созданное на относительно новом техпроцессе, поэтому можно ожидать повышения эффективности по мере того, как TSMC развивает свой техпроцесс, а AMD обновляет архитектуру.
Если брать во внимание только массовые продукты, то наиболее эффективные GPU на нашем графике – это GP102 и GP104. Это чипы Nvidia на архитектуре Pascal и мы найдём их в таких видеокартах как GeForce GTX 1080 Ti, GTX 1070 и GTX 1060. Рядом с GP102, не обозначенный меткой, расположился TU104. Это новейший Turing-чип от Nvidia, устанавливаемый в линейку GeForce RTX: 2060, 2070 Super, 2080, 2080 Super и многие другие.

Обзор и тестирование видеокарты MSI GeForce GTX 1080 Ti GAMING X TRIO
Они также изготовлены TSMC, но с использованием техпроцесса, специально разработанного для продуктов Nvidia, называемого 12FFN, который сам по себе является усовершенствованной версией 16FF.
Улучшения направлены на увеличение плотности кристалла при одновременном уменьшении утечек. Этим, возможно, объясняется то, что процессоры Nvidia выглядят более эффективными.
Эффективность GPU: TDP vs площадь кристалла
Если не учитывать техпроцесс, и вместо количества транзисторов на кристалле использовать в анализе лишь площадь кристалла, то мы увидим совершенно иную картину...
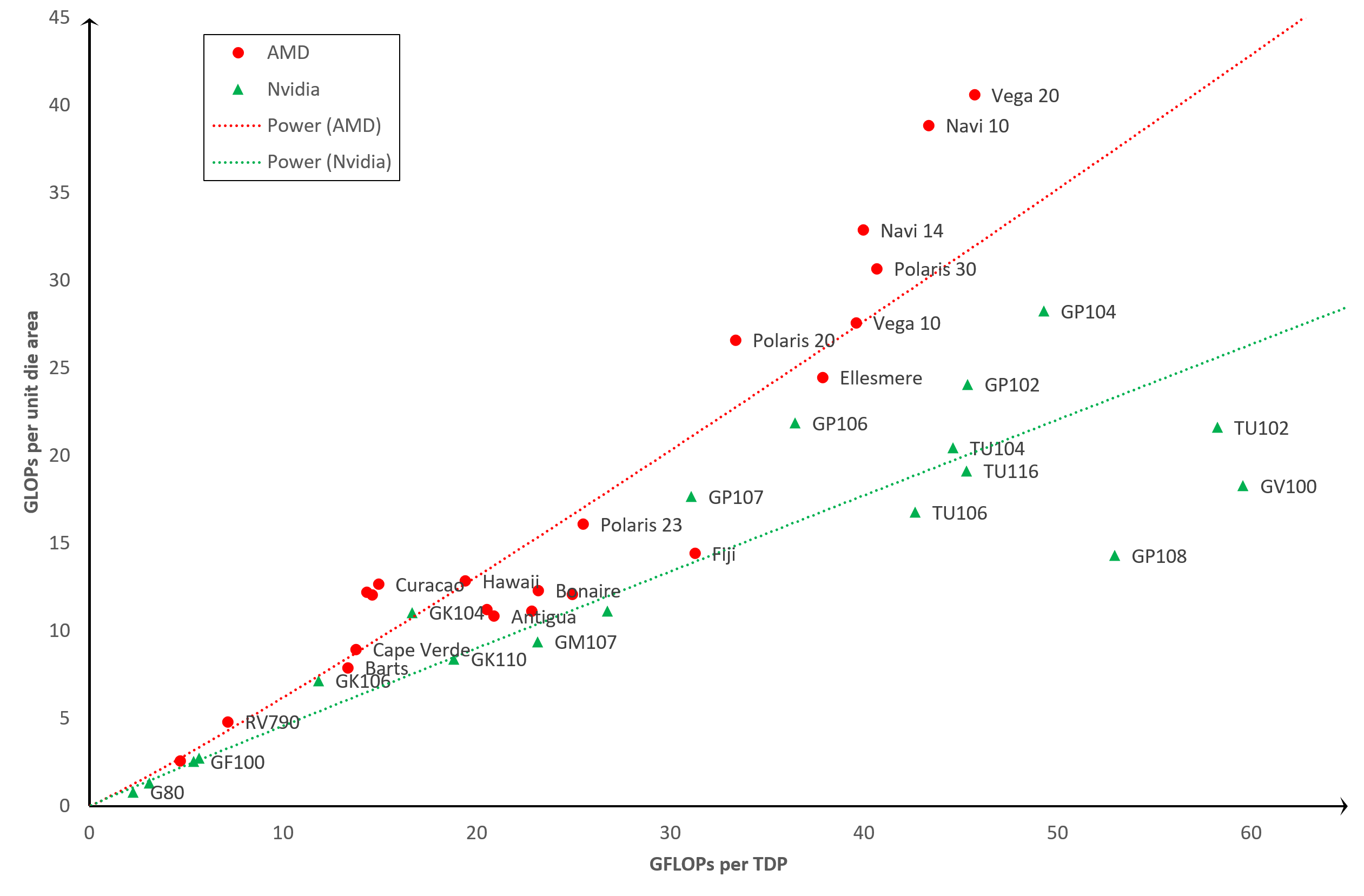
На этом графике эффективность увеличивается так же, но теперь мы видим, что некоторые ключевые позиции поменялись местами. TU102 и GV100 «осыпались», тогда как Navi 10 и Vega 20 подпрыгнули. Это связано с тем, что первые два процессора представляют собой огромные чипы (754 мм2 и 815 мм2), тогда как последние два от AMD намного меньше (251 мм2 и 331 мм2).
Оставим на графике только самые последние разработки, чтобы подчеркнуть различия:

Становится очевидным, что AMD пренебрегает энергоэффективностью в пользу уменьшения размеров кристалла.
Другими словами, AMD хотят получить больше GPU чипов с каждой произведённой кремниевой пластины, в то время как Nvidia, похоже, придерживается стратегии увеличения энергоэффективности каждого чипа в ущерб его размеру и, соответственно, стоимости изготовления (чем больше чип, тем меньше их можно разместить на одной пластине).
Продолжат ли AMD и Nvidia впредь следовать выбранным стратегиям? Первые уже заявили, что в RDNA 2.0 они намерены на 50% улучшить соотношение «производительность на ватт», поэтому мы ждём их новые GPU дальше справа, по нашему графику. А что насчет Nvidia?
А они, к сожалению, печально известны своей молчаливостью относительно своих планов. Но известно, что их новые процессоры будут производить TSMC и Samsung на том же техпроцессе, который использовался для Navi. Были некоторые заявления о том, что мы увидим значительное снижение энергопотребления, и в то же время большое увеличение количества унифицированных шейдеров. Поэтому, судя по всему, Nvidia также не нарушит тенденций на нашем графике.
Так как же повышалась эффективность GPU?
Вышесказанное довольно убедительно показало, что за прошедшие годы AMD и Nvidia повысили производительность на единицу плотности кристалла и на единицу TDP. Иногда рывки в производительности были впечатляющими...
Взять к примеру Nvidia G92 и TU102. Первый из них это сердце GeForce 8800 GT и 9800 GTX, на его кристалле площадью 324 мм2 размещено 754 миллиона транзисторов. Когда он появился в октябре 2007 года, он был высоко оценен за свою производительность и экономичность.
Через одиннадцать лет Nvidia предложила нам TU102 в виде GeForce RTX 2080 Ti. Этот процессор имеет почти 19 миллиардов транзисторов на площади 754 мм2 – то есть, в 25 раз больше микроскопических компонентов на поверхности, которая лишь в 2,3 раза больше.
Всё это не было бы возможным без усилий TSMC по совершенствованию своей производственной технологии. G92 в 8800 GT был построен на 65-нм техпроцессе, тогда как для производства новейшего TU102 используется специальный масштаб 12FFN. Названия этих методов производства на самом деле ничего не говорят нам о разнице между ними, но зато говорят показатели GPU. Плотность кристалла у нового процессора –24,67 миллиона транзисторов на мм2, тогда как у старого – 2,33 млн.
Более чем десятикратное увеличение плотности кристалла в основном и обуславливает огромную разницу в эффективности двух GPU. Меньшие логические блоки требуют меньше энергии для работы, а сокращение длины проводников между ними увеличивает и скорость обмена данными. Наряду с улучшением производства кремниевых чипов (уменьшение количества дефектов и совершенствование изоляции), всё это приводит к возможности работать на более высоких тактовых частотах при той же мощности, или наоборот – использовать меньшее энергопотребление при той же тактовой частоте.

Процессор AMD Vega 10 с двумя чипами HBM-памяти по 4 Гб слева.
Кстати о частотах. Давайте сравним RV670 от ноября 2007 года в Radeon HD 3870 с Vega 10 в Radeon RX Vega 64, выпущенной в августе 2017 года.
Первый имеет фиксированную тактовую частоту около 775 МГц, тогда как последний имеет как минимум три доступные частоты:
- 850 МГц – при обычной работе на компьютере, 2D-обработка.
- 1250 МГц – для сложных 3D-задач (базовая частота, «base clock»)
- 1550 МГц – для переменных легких/средних 3D-нагрузок («boost clock»)
Мы говорим «как минимум», потому что видеокарта динамически изменяет свою тактовую частоту и потребляемую мощность, между вышеуказанными значениями, в зависимости от текущей рабочей нагрузки и рабочей температуры. Это сегодня мы воспринимаем это как само собой разумеющееся, но 13 лет назад такого управления частотами просто не существовало. Оно, правда, никак не влияет на результаты наших анализов эффективности, поскольку мы брали только пиковую производительность обработки (т.е. на максимальных частотах), но оно влияет на оценку работы карты в глазах потребителя.
Но самым главным поводом постоянного повышения эффективности GPU в течение многих лет послужили изменения в использовании процессора как такового. В июне 2008 года лучшие суперкомпьютеры в мире были оснащены центральными процессорами от AMD, IBM и Intel; спустя одиннадцать лет к этой компании присоединился ещё один производитель: Nvidia.

Nvidia Tesla P100 с процессором GP100
Их процессоры GV100 и GP100 были разработаны почти исключительно для вычислительного сегмента рынка, в них заложено множество ключевых архитектурных функций, и многие из них очень похожи на CPU. Например, их внутренняя память (кэш) напоминает типичный серверный CPU:
- Регистровый файл (register file) на 1 SM = 256 кБ
- L0 кэш на 1 SM = 12 кБ инструкции
- L1 кэш на 1 SM = 128 кБ инструкции/данные
- L2 кэш на GPU = 6 МБ
Для сравнения: Intel Xeon E5-2692 v2, который использовался во многих вычислительных серверах:
- L1 кэш на ядро = 32 кБ инструкции/данные
- L2 кэш на ядро = 256 кБ
- L3 кэш на CPU = 30 МБ
Логические блоки внутри современного GPU поддерживают ряд форматов данных; некоторые имеют специализированные блоки для целочисленных вычислений, вычислений с плавающей точкой и матриц, в то время как другие имеют сложные структуры сразу для всех видов вычислений. Блоки соединены с кэшем и внутренней памятью широкими высокоскоростными интерконнектами. Безусловно, все эти нововведения положительно сказываются на обработке 3D-графики, но для большинства игр они избыточны. Но такие GPU разрабатывались не только для графики, а для более широкого спектра рабочих нагрузок, и для них есть специальное название: GPU общего назначения (GPGPU).
Machine Learning и Data Mining – это те две области, которые извлекли наибольшую выгоду из разработки GPGPU и поддерживаемых пакетов программного обеспечения и API (например, CUDA от Nvidia, FireStream от AMD, а также OpenCL), поскольку они объединяют в себе множество сложных массивно-параллельных вычислений.
Большие GPU, с тысячами унифицированных шейдерных блоков, идеально подходят для таких задач, и AMD с Nvidia (а теперь ещё и Intel присоединяется к их веселью) вкладывают миллиарды
долларов в разработку чипов, обеспечивающих все более высокую вычислительную производительность.

Первая дискретная видеокарта Intel за последние 20 лет. Превью видеокарт Intel Xe, часть 2
На данный момент обе компании разрабатывают универсальные архитектуры для своих GPU, которые могут использоваться в различных секторах рынка, как правило избегая создания полностью специфичных решений отдельно для графики и отдельно для вычислений. Это связано с тем, что основная часть прибыли от производства GPU по-прежнему поступает от продажи 3D-видеокарт, но уже неясно, сохранится ли такое положение дел в дальнейшем. Поскольку спрос на compute-мощности продолжает расти, вполне возможно, что AMD или Nvidia начнут выделять больше своих ресурсов на повышение эффективности чипов для этих рынков и меньше – на рендеринг.
Но что бы ни случилось дальше, мы знаем одно: на следующем этапе высокопроизводительные GPU с миллиардами транзисторов по-прежнему будут чуточку эффективнее своих предшественников. И это хорошая новость, независимо от того, кто это делает и для чего.
По материалам Techspot.com