Превью видеокарт Intel Xe, часть 2

Intel сейчас занимается разработкой дискретных видеокарт для геймеров и профессионалов, а также серверов. Их выпуск намечен на этот или на следующий, 2021, год. Явят ли они собой спасение стагнирующего рынка или нет – для большинства из нас одинаково радостно: у нас будут либо хорошие видеокарты, либо хороший повод посмеяться.

Это уже второй наш разбор Xe, поскольку появилось ещё немного информации за последние несколько месяцев. Кратко напомним хронологию важнейших событий и заявлений, сделанных Intel с момента обнародования информации о разработке Xe:
- 8 ноября 2017 года. Раджа Кодури (Raja Koduri) уходит с поста директора отдела графической архитектуры AMD и присоединяется к Intel, став старшим вице-президентом по графическому ядру и графическим вычислениям. И первое, что он сделал на новом посту – переманил к себе из AMD полдюжины старых приятелей.
- 12 июня 2018 года. Тогдашний CEO Intel Брайан Крзанич (Brian Krzanich) сообщает инвесторам, что компания на протяжении нескольких лет разрабатывают архитектуру «Arctic Sound» для дискретных GPU, планируя представить ее миру в 2020 году.
- 8 января 2019 года. Старший вице-президент по работе с клиентами Грегори Брайант (Gregory Bryant) подтверждает на CES, что первое поколение новых графических процессоров Intel будет реализовано на 10-нм техпроцессе.
- 1 мая 2019 года. В ходе конференции FMX19, Джим Джефферс (Jim Jeffers), главный инженер и директор группы рендеринга и визуализации, объявляет о возможности трассировки лучей в Xe.
- 17 ноября 2019 года. Раджа Кодури проинформировал, что Xe намерен охватить три сектора рынка, удовлетворив потребности мощных рабочих станций (Xe-HP, high-performance), энергоэффективных систем (Xe-LP, low-power) и высокопроизводительных вычислений (Xe-HPC, high-performance compute). Первым GPU в категории HPC будет Ponte Vecchio (читается: Понте-Веккьо), который появится в 2021 году на 7-нм.
- 9 января 2019 года. Опубликованы первые изображения компактной карты с подсветкой DG1 SDV (Discrete Graphics One Software Development Vehicle) – прототипа для разработчиков программного обеспечения, позволяющего им оптимизировать свои проекты для новой архитектуры.

И в ближайшее время...
- 17 марта 2020 года. Старший инженер по связям с разработчиками Антуан Кохаде (Antoine Cohade) «подробно расскажет об аппаратной архитектуре» и «влиянии на производительность» Xe в ходе предстоящей Конференции Разработчиков Игр в Сан-Франциско (GDC).
Из официальных источников мы узнаём, как Intel усердно работает над созданием таинственных графических процессоров с множеством полезных функций, как модернизируются техпроцессы, как внедряются технологии трассировки лучей и разрабатываются новые методы корпусировки. Но нас с вами прежде всего интересует итоговая мощность и цена. Именно об этом и будет наша статья.
Архитектура
Хорошая архитектура начинается с одного кирпичика, что справедливо и для всех GPU… кроме интеловских. Ядра AMD и Nvidia выполняют одну операцию за такт, а исполнительные модули Intel (EU, «execution units») выполняют восемь. Чтобы нам легче было сравнивать, мы пренебрежем некоторыми техническими неточностями и приравняем восемь ядер к одному EU.
Работая сразу с восемью кирпичиками, Intel добиваются простоты и прямолинейности построения. Несколько таких кирпичиков – и готова стена. Несколько таких стен – готова комната. Пара таких комнат – и вот вам квартира.
Такой наибольший автономный модуль («квартира») называется слайс (slice) и содержит 512 или 768 ядер для HP и LP вариантов соответственно. Одна квартира – это всё, что вам нужно, так что энергоэффективные Xe-LP карты используют только один слайс. Но если вам в такой квартирке тесновато, Intel строит многоэтажные коттеджи – продвинутые GPU, состоящие из множества слайсов.
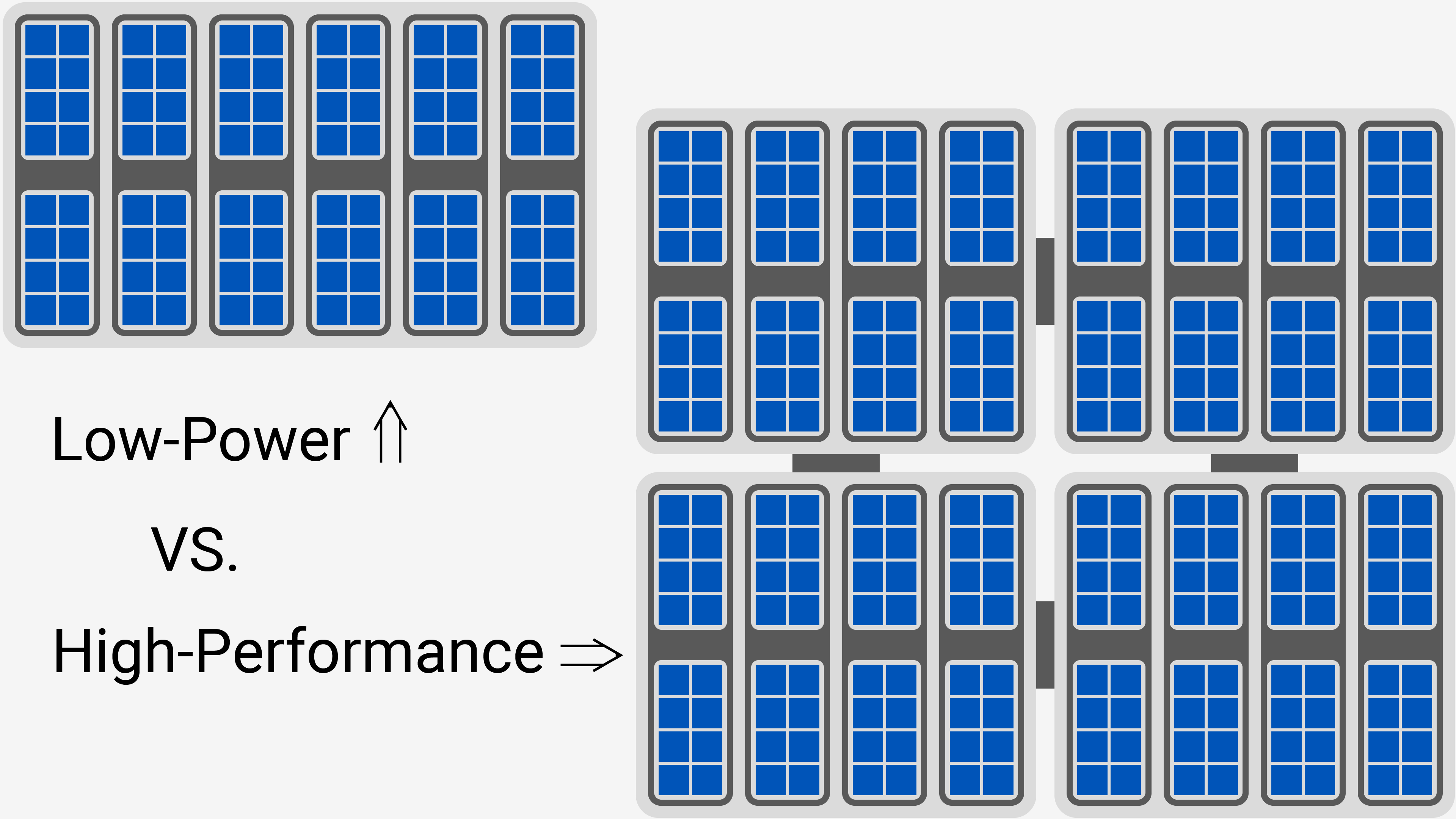
1-слайсовый LP GPU vs. 4-слайсовый HP GPU. Синие квадратики – исполнительные модули. Схема основана на архитектурных схемах Intel и презентации Supercomputing 2019, а также на базе данных EEC и актуальном драйвере. Может содержать неточности. Источник: techspot.com
Этого достаточно, чтобы в общем виде понимать ситуацию с Xe архитектурой, но, если вам нравятся цифры и технический язык, вам будут интересны и следующие несколько строк.
В Gen11 встроенные графические процессоры Intel имели один слайс, состоящий из восьми полуслайсов, которые в свою очередь имели по восемь исполнительных модулей. Немного модифицировав эту архитектуру, добавив вычислительные модули (CU, compute units) и оптимизировав рендер-бэкенд, Intel получила архитектуру Gen12 для первого поколения Xe.
В сентябре через GitHub произошла утечка кодов конфигураций DG1, Ponte Vecchio и частично DG2. Достоверность этих данных сомнения не вызывает: как и предсказывалось, Ponte Vecchio имеет два слайса. А предположение, что DG1 будет иметь 6 полуслайсов на слайс, и соответственно 96 исполнительных модулей, более-менее подтверждается базой данных EEC, показывающей аналогичные значения.
Из утечки следует, что во всех своих Gen12 моделях Intel использует 16 EU на полуслайс, и что в Ponte Vecchio, в частности, слайс составлен из четырёх полуслайсов. Кодури позже добавил, что Ponte Vecchio построен на двух слайсах и имеет 16 CU (вычислительных модулей).
На основе этой информации мы можем предположить, что Ponte Vecchio работает примерно так: 8 исполнительных модулей (EU) объединены в 1 CU – вычислительный модуль (итого 64 ядра), которые в паре составляют 1 полуслайс (128 ядер/16 EU), и из четырёх таких полуслайсов получается 1 слайс (512 ядер/64 EU). Таким образом, 2-слайсовый Ponte Vecchio имеет 128 EU, то есть 1024 ядра. И следует иметь в виду, что 2-слайсовая конфигурация – это, возможно, лишь конфигурация прототипа.
Ожидается, что базовая слайс-конфигурация Ponte Vecchio будет использоваться и в HP, и в LP моделях.
DG2: High-Performance (HP)
Высокопроизводительная микроархитектура с кодовым названием Discrete Graphics Two (DG2) охватывает рынки среднего и продвинутого класса GPU. Именно эти карты будут иметь трассировку лучей и RGB, но что самое интересное, это возможность для Intel потягаться с Nvidia в премиум-сегменте (600+ долларов).
В июле прошлого года Intel случайно опубликовала драйвер (спасибо!), содержащий три кодовых имени DG2: iDG2HP128, iDG2HP256 и iDG2HP512. Логично предположить, что последние три цифры указывают на количество EU в карте, а стало быть, и ядер – 1024, 2048 и 4096 ядер соответственно. Это два, четыре и восемь слайсов.«Xe HP… имеет все шансы стать крупнейшим кристаллом, разработанным в Индии, и одним из крупнейших в мире», – Раджа Кодури.
Однако вскоре после этого мы увидели убедительные доказательства того, что разрабатывается ещё и 3-слайсовый GPU с 1536 ядрами. Учитывая, что для Intel было бы нелогично разрабатывать четвертую карту, аналогичную существующим, можно предположить, что это iDG2HP256 с одним отключенным слайсом. Это подтверждает распространенные подозрения, что Intel собирается манипулировать тремя основными моделями, добавляя в свою линейку четвертую, пятую, шестую и даже седьмую модели, просто отключая один или несколько слайсов.
|
слайсы |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
Кол-во ядер |
768* |
1024 |
1536 |
2048 |
2560 |
3072 |
3584 |
4096 |
|
Кодовое название |
iDG1LPDEV |
iDG2HP128 |
|
iDG2HP256 |
|
|
|
iDG2HP512 |
* DG1 имеет шесть полуслайсов, а DG2 – четыре, отсюда разница в количестве ядер на слайс.
DG2 – больше, чем просто игровые видеокарты. Может, они и не справятся с такими объёмными научными вычислениями, на которые рассчитана Ponte Vecchio, но при удачном исходе релиза, они могут полностью рассчитывать на почетное место оборудования для видеоредактирования и 3D, не хуже Nvidia Quadro.
DG1: Low-Power (LP)
Сегмент маломощных GPU – это GPU мощностью от 5 до 50 Вт. От 5 до 20 Вт – для встроенных, и от 20 до 50 Вт – для дискретных.
Intel уже познакомила нас с первым членом семейства LP. DG1 SDV был широко представлен на CES 2020, показав себя в работе с Destiny 2 и Warframe, с RGB и прочим. Но то была лишь ее демонстрация как игровой карты. DG1 SDV – это версия для разработчиков ПО, предназначенная для адаптации программного обеспечения и драйверов к платформе Xe.
Это не означает, что вы не сможете купить нечто подобное в итоге – Intel уже показала ее, работающей в ноутбуке.
(Это не ноутбук, просто оставляю это здесь)

Сообщается, что встроенные LP GPU имеют от 64 до 768 ядер, в то время как дискретные – исключительно 768. Это сопоставимо с лучшими встроенными GPU от AMD и дискретными GPU Nvidia lowest-end уровня. Но вот где Xe LP может переплюнуть их – так это тактовые частоты.
Тест Geekbench, запущенный на мобильном процессоре, показал интегрированный 768-ядерный LP GPU на частоте 1,5 ГГц с результатом 2,3 TFLOP. Это тот же уровень производительности, что и у GTX 1650. Даже если предположить худшее, что 1,5 ГГц – это на максимальном TDP 20 Вт, и Intel не сможет увеличить скорость ни на мегагерц до релиза, это всё равно впечатляет.
Только представьте, каким эффективным должен быть этот процессор. У GTX 1650 немного меньше TFLOP, но TDP 75 Вт, что почти в четыре раза больше. 50-ваттный LP GPU на более высоких частотах может перейти на тот же уровень производительности, что и GTX 1660.
Но хорошие новости на этом не заканчиваются. Обновления ядра Linux показывают, что Intel намерены добавить возможность одновременной и, возможно, совместной работы встроенной и дискретной графики. Если это удастся, то полная мощность встроенного GPU будет объединена с мощностью дискретного, создав компактный и экономичный комбинированный графический процессор с 1536 ядрами. Это отличный способ выжать максимум производительности из кристаллов.
Ponte Vecchio: Data Compute (HPC)
Когда я сказал в начале, что значение имеет лишь чистая мощь GPU, я солгал поймал на кликбейте. Ни к одному GPU для дата-центров это не относится, в том числе и к Ponte Vecchio. Ponte Vecchio максимизирует свою эффективность лишь за счёт всяких хитростей и технологической оптимизации.
Забавный факт: Кодури дал своему GPU название Ponte Vecchio в честь моста во Флоренции, потому что ему там очень нравится местное мороженое.
Ponte Vecchio создавался в расчете на работу с суперкомпьютером Aurora, что даёт нам представление о типе рабочих нагрузок, к которым оптимизируется GPU.
Если это ни о чем вам не говорит, я поясню: речь идёт о double precision, числе двойной точности. По сути, это первое в списке для любого GPU для дата-центров, и Кодури посвятил очень много времени обсуждению этого вопроса на презентации. Однако, к сожалению, единственная цифра, которую он озвучил – это теоретическая FP64-производительность одного EU в Ponte Vecchio: примерно в 40 раз выше, чем у Gen11.
Сделав некоторые подсчеты, мы получили значение FP64 производительности около 20 TFLOP на 1024 ядрах карты. Но точных исходных цифр нет, поэтому это лишь приблизительный результат.
Второе место после рабочих нагрузок с данными высокой точности – это, естественно, работа с данными низкой точности. Ponte Vecchio поддерживает INT8, BF16 и обычные FP8 и FP16 для вычислений в нейросетях. Каждый EU имеет инструмент матричной обработки (наподобие тензорного ядра Nvidia), который выполняет матричные вычисления в 32 раза быстрее стандартного EU.
Тем не менее, особо нового ничего в этом нет. Революционность Ponte Vecchio заключается в её подсистеме памяти, которая позволяет решать проблемы по-новому.
Для этого Ponte Vecchio использует новейшие технологии интерконнекта Intel: Foveros и EMIB (Embedded Multi-die Interconnect Bridge – встроенный многокристальный соединительный мост). Foveros использует сквозные переходы для укладки нескольких чипов поверх активного кристалла-переходника (Foveros interposer die), обеспечивая им скорости кристалла вне его самого. Для сравнения: EMIB представляет собой «глухое» соединение между двумя чипами, которое использует неактивный кристалл, но предлагает высокую пропускную способность при более низкой стоимости.
EMIB и Foveros

Схема основана на архитектурных схемах Intel, их презентациях в рамках Дня архитектуры 2018 года и Supercomputing 2019, а также информации из WikiChip. Схема не демонстрирует в точности реальную имплементацию. Источник: techspot.com
EMIB используется для подключения вычислительного ядра GPU непосредственно к HBM-памяти, что обеспечивает впечатляющую пропускную способность памяти Ponte Vecchio. Foveros, в свою очередь, применяется для подключения двух CU на полуслайсе к одному чиплету кэша RAMBO, нового суперкэша Intel. Благодаря Foveros, RAMBO не стеснен ограничениями, накладываемыми его объемом или размером, и он может обходить CU при обмене данными с HBM-памятью или другими полуслайсами.
Наличие гигантского кэша (и под гигантским я имею в виду реально гигантский, на схемах Intel чиплеты RAMBO такого же размера, что и CU), очевидно существенно поднимает цену, но зато открывает кое-какие интересные перспективы. Например, при работе с нейросетями RAMBO может хранить на порядок больше матриц, чем другие кэши GPU. Все другие графические процессоры теряют производительность по мере увеличения матриц и повышения уровня точности данных, но Ponte Vecchio способна поддерживать максимальную производительность.
Ponte Vecchio
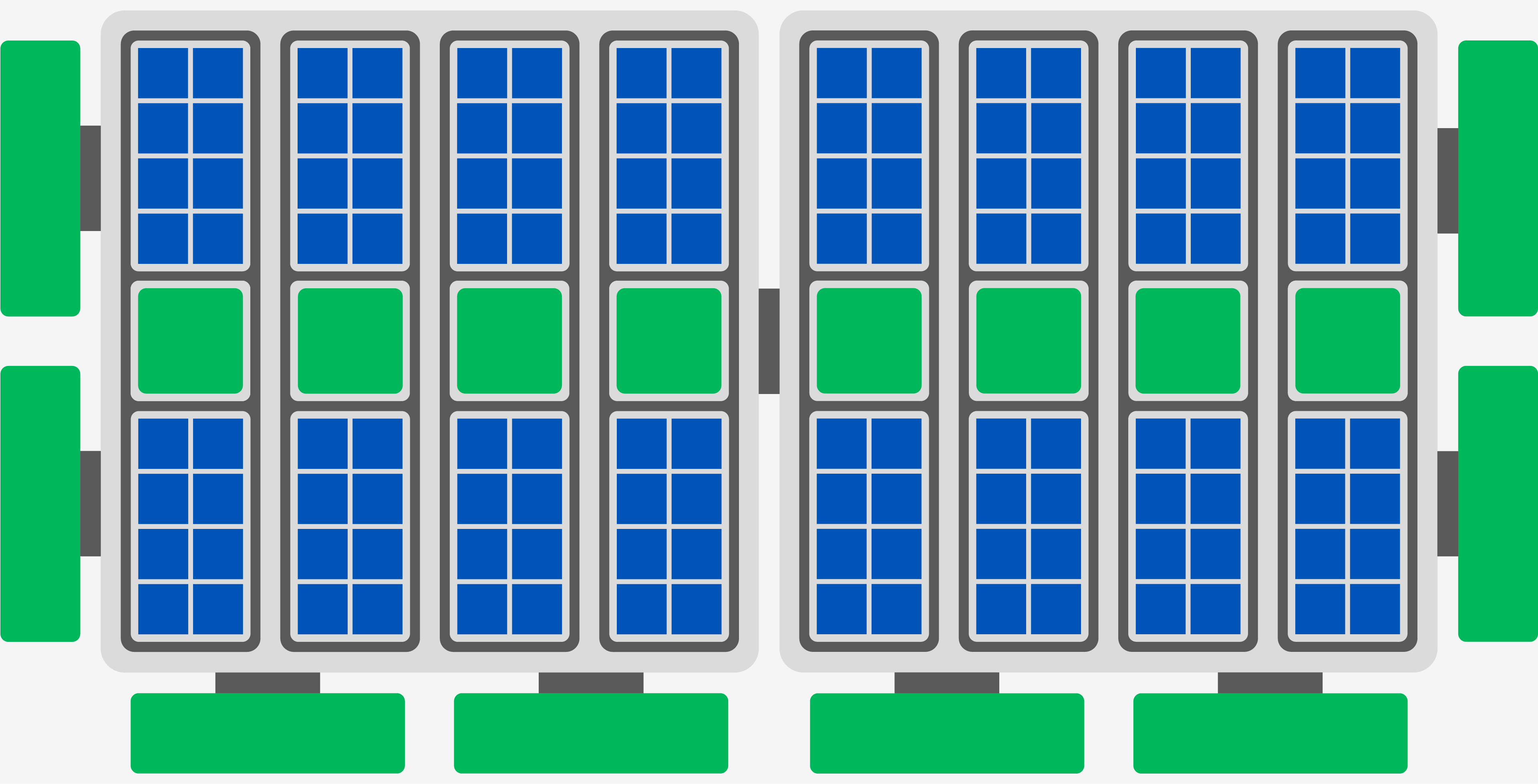
Синие квадраты – EU, исполнительные модули, а зеленые – RAMBO кэш и HBM-память. Схема основана на архитектурных схемах Intel и презентации Supercomputing 2019. Может содержать неточности. Источник: techspot.com
Кэш RAMBO также поддерживает Xe Memory Fabric, паутину соединений и технологий, которая объединяет ресурсы всех GPU и CPU в узел сервера. RAMBO-кэш каждого графического процессора объединен с единым банком, доступным для всех, причем самое медленное соединение – это 63 Гб/с по PCIe 5.0.
Отчитываясь по доходам на своей недавней ежегодной встрече с инвесторами, Intel подтвердила, что продажи Ponte Vecchio начнутся в четвертом квартале 2021 года. Неясно, идёт ли речь о полноценном публичном релизе, или о предварительном релизе специальной версии для суперкомпьютера Aurora.
Программное обеспечение
Железки – железками, но они совершенно бесполезны без адекватной программной поддержки. И планка довольно высока: даже одним процентом геймеров пренебречь нельзя, так как этот 1% будет означать миллионы проигнорированных пользователей. Хорошо, что Intel это прекрасно понимает, и делает всё возможное.
Intel переписывает свой самый низкоуровневый софт – архитектуру набора команд (ISA), оптимизируя его под современные высокопроизводительные приложения. «С внедрением Gen12 планируется провести одну из самых глубоких редакций Intel EU ISA со времен оригинального i965. Необходимо обновить чуть ли не все команды, аппаратные коды и регистры».
С драйверами у Intel не всегда было всё гладко, но прогресс виден. Их встроенные драйверы GPU обновляются не так часто, как у конкурентов – в среднем 26 дней между последними десятью обновлениями против 14 дней у Nvidia и 12 у AMD. Но их стабильность и поддержка значительно улучшились в течение 2019 года, и 275 новых игр были успешно оптимизированы для архитектуры Intel.
С другой стороны, пользовательское ПО Intel превосходно. Недавно выпущенный Intel Graphics Command Center обеспечивает значительно больший контроль, чем, например, Nvidia GeForce Experience, и проще в использовании. Как и у GeForce Experience, у GCC есть оптимизация игр для конкретных аппаратных конфигураций, но Intel вдобавок объясняет, что делает каждый параметр и какое влияние он оказывает на производительность. Управление драйвером простое и приятное.
В Graphics Command Center имеются и уникальные расширенные настройки. Он предлагает «мягкую» настройку нескольких дисплеев и частоты обновления, а также управление синхронизацией и широкие возможности настройки цветовой стилизации. Лично я использую его в своей системе, хоть у меня и видеокарта Nvidia.
Наконец, Intel также поддерживает переменную частоту обновления, так что продукты Xe будут совместимы с мониторами FreeSync и G-Sync.
Релиз
Хотя Intel немного скупится относительно информации о том, что они собираются объявить в марте на GDC в марте, мы скорее всего узнаем всё именно там. Если так и произойдёт, то в ближайшие месяцы можно будет ожидать старта продаж. Наиболее вероятный кандидат – июнь.
В октябре прошлого года Кодури опубликовал в своём твиттере довольный жирный намёк в виде изображения своего нового автомобильного номера. На нем написано «Think Xe» и дата: июнь 2020 года. Он отказывается комментировать, имеет ли дата какое-либо значение или нет, что говорит о том, что, вероятно, имеет.

Одним из преимуществ анонсирования даты подобным манером является то, что оно информирует, но ничего не обещает, тем самым предупреждая чрезмерное негодование «обманутых» фанатов в случае, если релиз состоится не в июне, а в июле. Так что считайте эту дату лишь ориентировочной; вероятно, Intel планирует выпуск на июнь (вовремя для Computex), но планы могут быть скорректированы в зависимости от того, как идут дела.
Довольно интересные вещи прячет в карманах Intel, и мы надеемся, что у нас появится третий крупный игрок на арене графики. И пока час истины не настал, мы можем быть не более чем осторожными оптимистами.