
NVIDIA Ampere vs. AMD RDNA 2 — Битва архитектур
Те, кто постоянно следит за рынком GPU, наконец дождались этого дня. Nvidia развивала архитектуру Turing в течение двух лет, прежде чем заменить ее на Ampere в сентябре 2020 года. AMD была несколько более услужливой, предложив свою новую разработку уже через 15 месяцев после анонса предыдущей, но для большинства людей такая доброта мало что значила.
Они хотели, чтобы AMD выпустила топовую модель, на равных конкурирующую с лучшими из Nvidia, и AMD в точности исполнила их желания. И теперь, когда мы увидели результаты, ПК-геймеры выглядят несколько избалованными, когда дело доходит до выбора, на какую из самых производительных видеокарт потратить свои денежки.
Так, что там насчет чипов, на которых построены эти карты? Они как-то принципиально отличаются друг от друга? Из этой статьи вы узнаете, как разворачивается битва титанов Ampere и RDNA 2!
Nvidia стареет, AMD растет
Техпроцесс и размер кристалла
В течение ряда лет топовые GPU превосходили размерами CPU, и неуклонно увеличивались в размерах. Площадь последнего продукта AMD составляет примерно 520 мм2, что более чем вдвое больше их предыдущего чипа Navi. И это ещё не самый большой чип – корона достается GPU их нового акселератора Instinct MI100 с площадью около 750 мм2.
В последний раз AMD производила игровой процессор размером, сопоставимым с Navi 21, было во времена чипа Fiji на архитектуре GCN 3.0 для видеокарт Radeon R9 Fury и Nano. Площадь кристалла Fiji составляла 596 мм2, но он был изготовлен на технологическом процессе TSMC 28HP.
Более мелкомасштабный техпроцесс TSMC N7 AMD начала использовать с 2018 года, и самым большим чипом из этой производственной линии был Vega 20 (в Radeon VII) с площадью 331 мм2. Все GPU серии Navi созданы на основе слегка обновленной версии этого процесса, которая называется N7P, поэтому эти продукты имеет смысл сравнить.

Radeon R9 Nano: массивный GPU на крохотной карте
Но когда дело доходит до чистого размера кристалла, корона переходит к Nvidia, хотя нет такого правила: «чем больше кристалл, тем лучше». Последний чип на базе Ampere, GA102, имеет площадь 628 мм2. Это фактически на 17% меньше, чем у его предка TU102 с кристаллом, площадью аж 754 мм2.
Оба меркнут в сравнении с гигантским кристаллом чипа Nvidia GA100, используемым в AI и дата-центрах. Этот графический процессор имеет площадь 826 мм2, и это на техпроцессе TSMC N7. Он совершенно не предназначен для пользовательских ПК, но на его примере мы видим, какие масштабы производства GPU возможны.
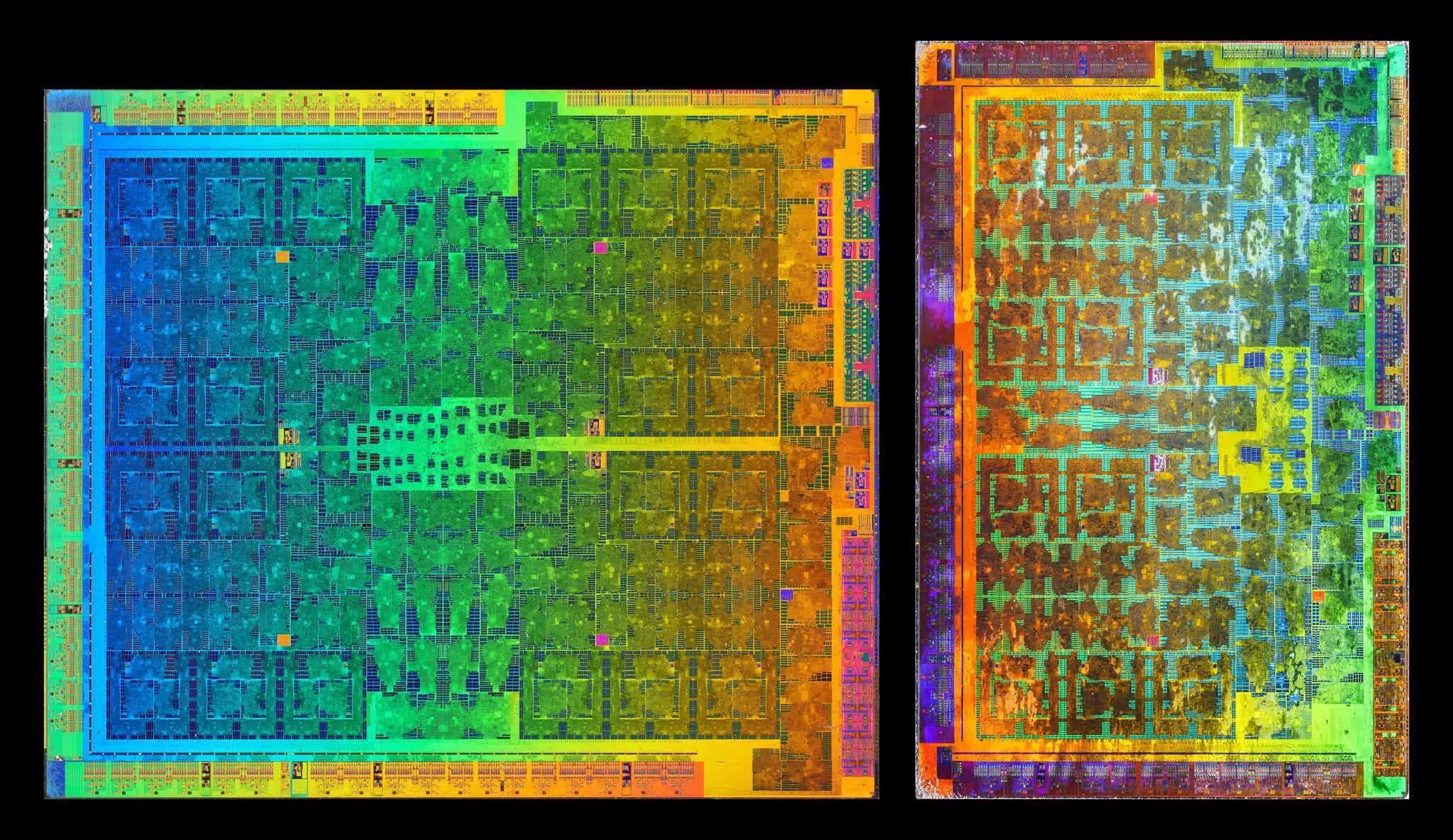
Разложив их бок-о-бок, видим, насколько массивны самые большие GPU Nvidia. Navi 21 выглядит стройняшкой, хотя площадь кристалла – это ещё не весь процессор. GA102 содержит около 28,3 миллиарда транзисторов, тогда как новый чип AMD имеет на 5% меньше – 26,8 миллиарда.

Мы не располагаем информацией о количестве слоев процессоров, поэтому все, что мы можем сравнивать – это соотношение транзисторов к площади кристалла, обычно называемое плотностью кристалла (die density). У Navi 21 эта величина составляет примерно 51,5 миллиона транзисторов на квадратный мм, а у GA102 заметно меньше – 41,1 миллион. Возможно, это связано с вертикальным позиционированием кристалла, которое у Nvidia чуть выше, чем у AMD. Но скорее всего, это показатель отличий техпроцесса.
Как мы уже сказали, Navi 21 производится TSMC по технологии N7P, несколько более производительной по сравнению с N7. А Nvidia для производства своего нового детища GA102 обратилась к мощностям Samsung. Южнокорейский полупроводниковый гигант применяет специально разработанную для Nvidia модификацию своего 8-нм техпроцесса (обозначаемого как 8N или 8NN).
Эти значения – 7 и 8 нм – на самом деле мало что говорят о фактическом размере компонентов на чипе, это лишь маркетинговые термины, используемые для различения производственных технологий. Тем не менее, даже если у GA102 больше слоев, чем у Navi 21, размер кристалла имеет одно особое значение.

Проверка качества 12-дюймовой (300 мм) кремниевой пластины. Завод TSMC.
Микропроцессоры, как и прочие микросхемы, изготавливаются из больших круглых дисков высокочистого кремния со специальными добавками, называемых пластинами или «вафлями» (wafer). TSMC и Samsung используют 300-миллиметровые пластины для AMD и Nvidia, и чем меньше матрица кристалла, тем больше таких матриц можно получить с одной большой пластины-вафли.
Разница кажется незначительной, но учитывая, что производство каждой пластины обходится в тысячи долларов и речь идёт о снижении производственных затрат, AMD оказывается в несколько более выигрышном положении. При условии, конечно, если между Samsung или TSMC нет каких-либо дополнительных финансовых договоренностей с AMD/Nvidia.
Но все эти заморочки с размерами кристалла и количеством транзисторов смысла бы не имели, если бы сами чипы не выполняли безупречно своих функций. Итак, давайте углубимся в компоновку каждого нового графического процессора и посмотрим, что находится у них «под капотом».
Препарирование кристаллов
Общее строение Ampere GA102 и RDNA 2 Navi 21
Мы начнем изучение архитектур с рассмотрения общей структуры двух наших GPU – Ampere GA102 и RDNA 2 Navi 21. Предложенные схемы не обязательно отражают всё, как есть на самом деле, но они дают четкое представление обо всех компонентах процессоров.
В обоих случаях схемы нам весьма знакомы, поскольку они по сути являются расширенными версиями своих предшественников. Добавление большего количества вычислительных блоков всегда идёт на пользу производительности GPU, поскольку рабочие нагрузки рендеринга должны отвечать всем требованиям современных 3D-блокбастеров.
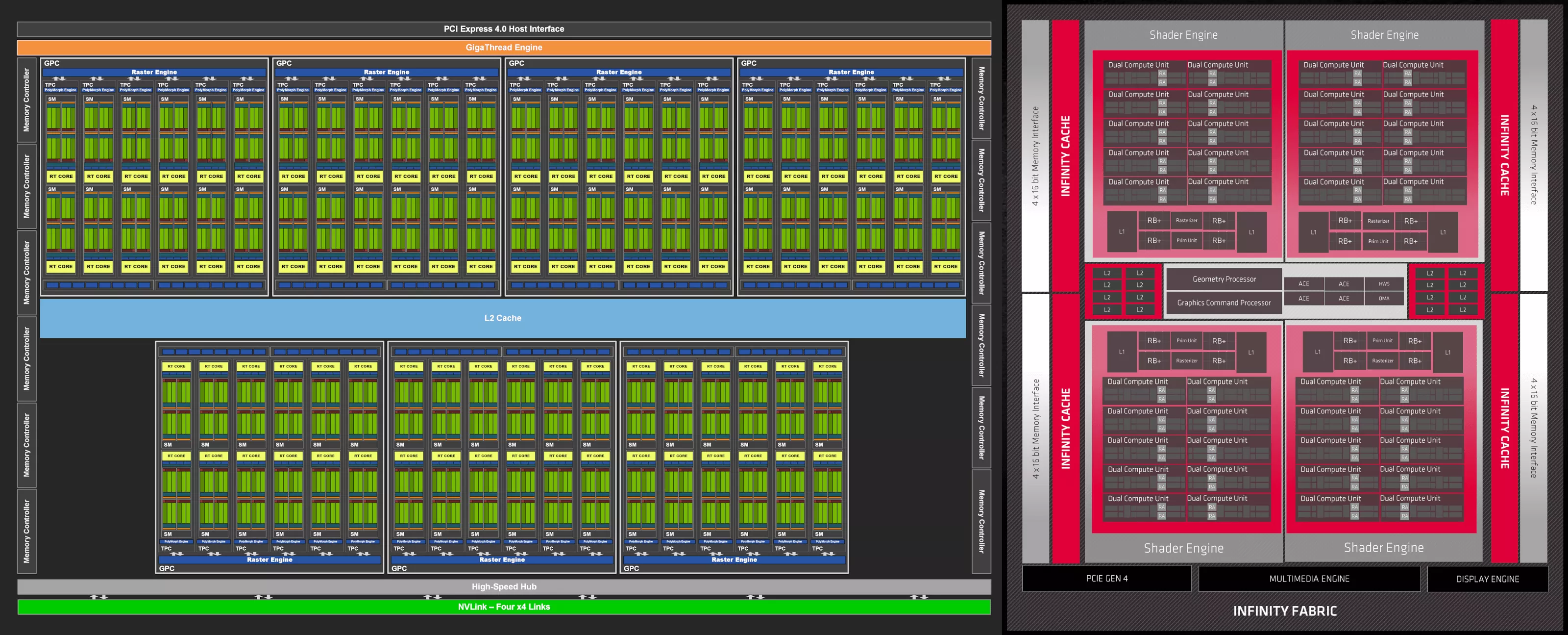
Такие схемы полезны, но для нашего анализа более интересно было бы посмотреть, как именно расположены компоненты на кристаллах GPU. При проектировании крупномасштабного процессора обычно требуется, чтобы общие ресурсы, такие как контроллеры и кэш, находились в центре, чтобы каждый компонент гарантированно имел равный путь к ним.
Интерфейсы, такие как контроллеры локальной памяти или видеовыходы, должны располагаться по краям, чтобы упростить их подключение к тысячам выводов, связывающих GPU с остальными элементами видеокарты.
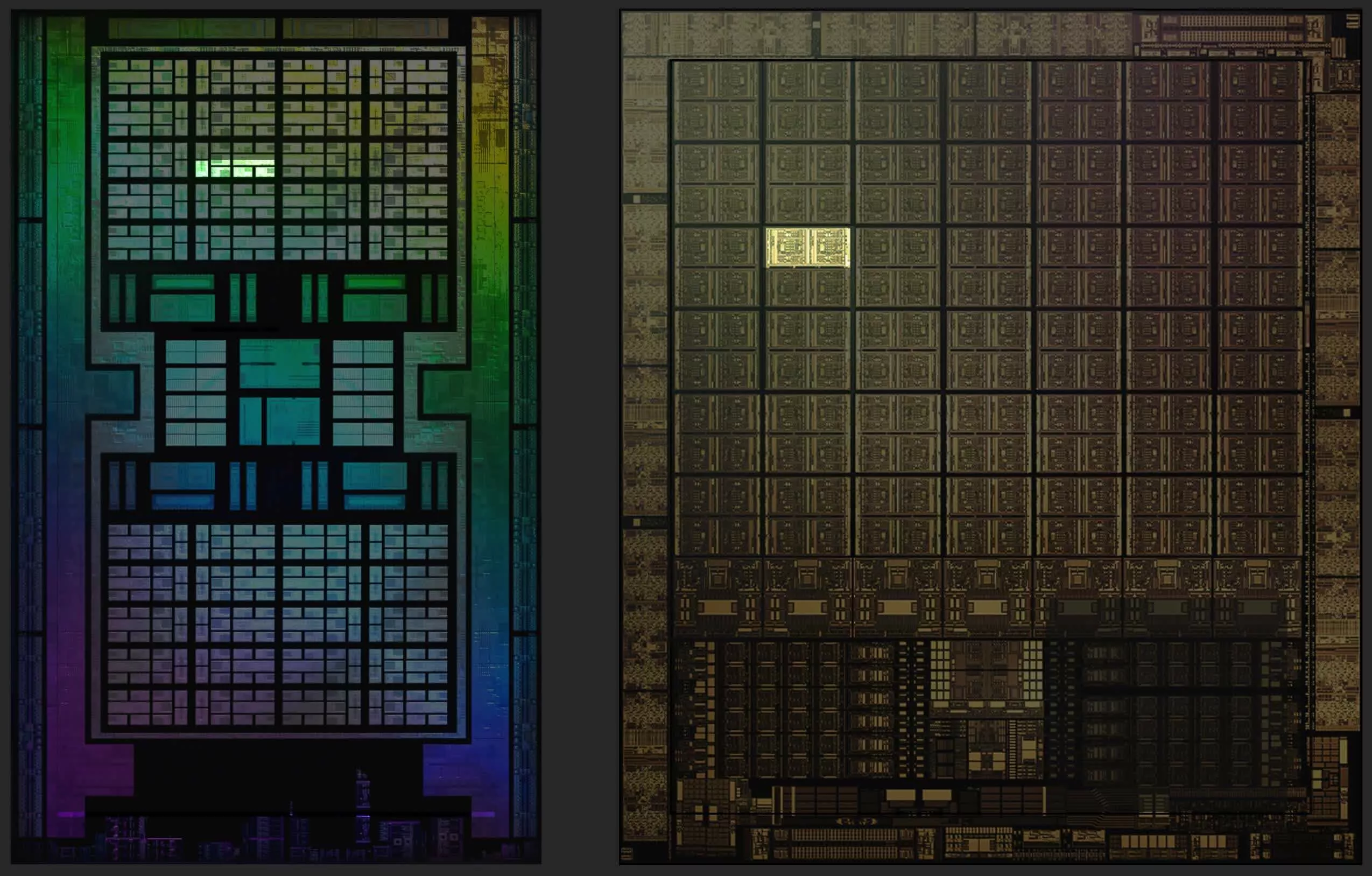
Ниже приведены изображения кристаллов AMD Navi 21 и Nvidia GA102. Оба снимка подкрашены и подчищены в графических редакторах, и оба показывают нам лишь один слой, но они дают великолепное представление о внутренностях современного GPU.
Самое очевидное различие между конструкциями заключается в том, что Nvidia не стала следовать централизованному подходу к компоновке – все системные контроллеры и основной кэш находятся внизу, а логические блоки размещены в длинных столбцах. Они уже делали так раньше, но только в моделях среднего/нижнего ценового сегмента.
К примеру, Pascal GP106 (в GeForce GTX 1060) был буквально вдвое меньше GP104 (GeForce GTX 1070). Последний был более крупным чипом с кэш-памятью и контроллерами посередине. У собрата же они смещены в сторону.
Pascal GP104 vs GP106.
Испокон веков для всех своих топовых схем GPU Nvidia использовала классическую централизованную организацию. Так почему же вдруг решила теперь отказаться от неё? Это не может быть связано с интерфейсами, так как контроллеры памяти и система PCI Express работают по краю кристалла.
Это также не имеет отношения к теплоконтролю, поскольку даже если кэш/контроллер будут греться сильнее, чем логические секции, всё равно целесообразней размещать их в центре, чтобы имелась максимальная площадь кремния вокруг для отвода и рассеивания тепла. Мы не уверены, но подозреваем, что причиной такого нетривиального решения стали нововведения, которые Nvidia реализовала в модулях ROP (Render Output Pipeline – конвейер вывода рендеринга).
Позже мы рассмотрим их более подробно, а пока просто скажем, что, несмотря на кажущуюся странность компоновки, существенного влияния на производительность это не оказывает. Это обусловлено тем, что для 3D-рендеринга характерно большое количество длительных задержек, обычно из-за необходимости ждать данных. Таким образом, дополнительные наносекунды, возникающие на пути к более отдаленным логическим блокам, особой роли не играют.
Прежде чем продолжить, стоит отметить инженерные изменения, реализованные AMD в компоновке Navi 21 в сравнении с Navi 10 (Radeon RX 5700 XT). Несмотря на то, что новый чип вдвое больше предыдущего, как с точки зрения площади, так и по количеству транзисторов, разработчикам также удалось улучшить тактовые частоты без значительного увеличения энергопотребления.
К примеру, Radeon RX 6800 XT имеет базовую тактовую частоту и частоту разгона 1825 и 2250 МГц соответственно при TDP 300 Вт, а те же показатели для Radeon RX 5700 XT были 1605 МГц, 1905 МГц и 225 Вт. Nvidia тоже повысила тактовые частоты в Ampere, но частично за счет использования меньшего и более эффективного техпроцесса.
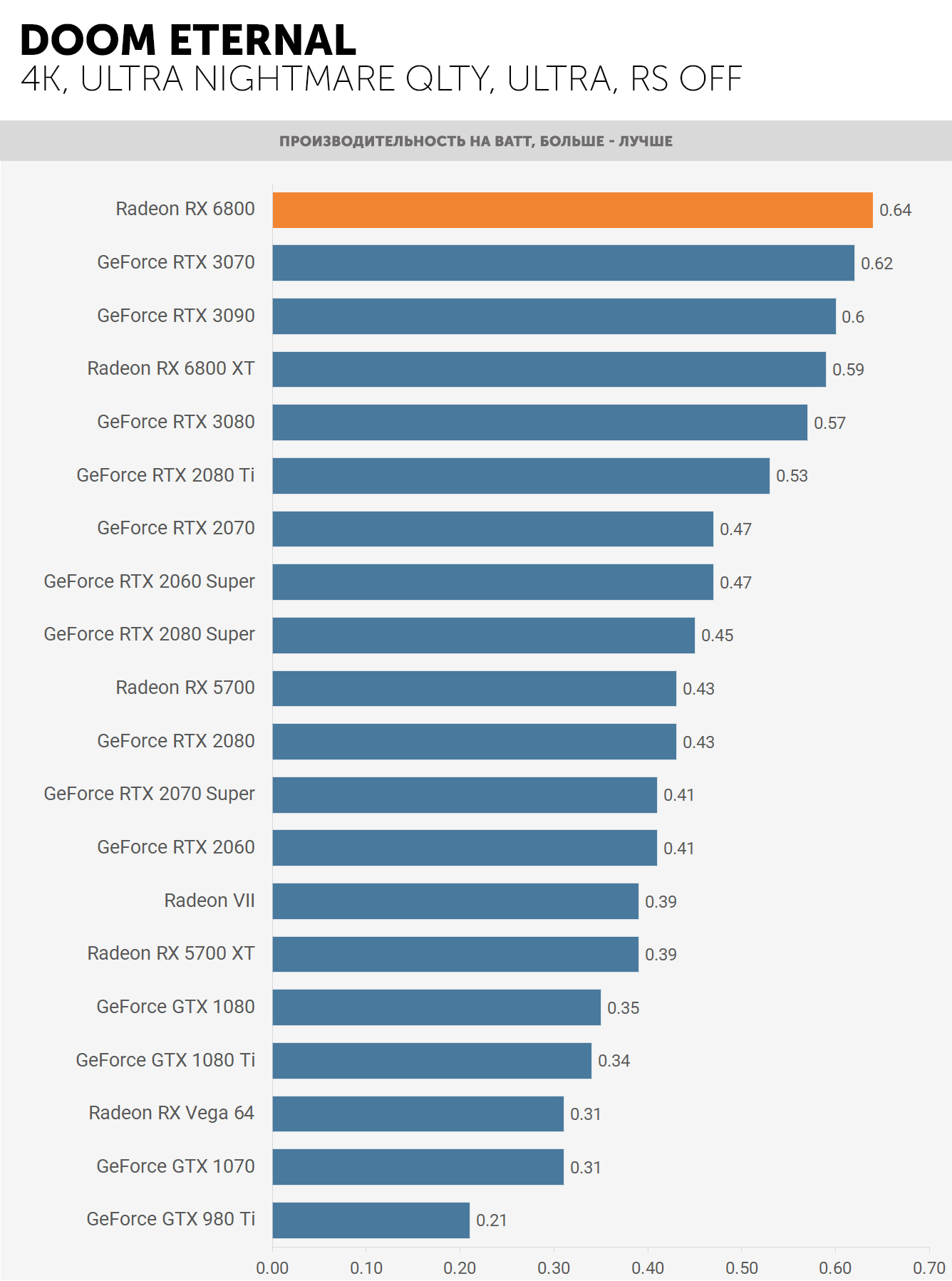
Тест эффективности (производительность на ватт) карт Ampere и RDNA 2 показал, что оба производителя добились значительных успехов в этой области, однако AMD с TSMC достигли чего-то весьма примечательного – сравните разницу между Radeon RX 6800 и Radeon VII на диаграмме теста.
Radeon VII был их первым проектом с использованием техпроцесса N7, и менее чем за два года они увеличили производительность на ватт на 64%. Возникает вопрос, насколько лучше могла бы быть Ampere GA102, останься бы Nvidia сотрудничать с TSMC.
Заводские цеха GPU
Как все устроено внутри чипов
В части всего, что касается обработки команд и управления передачей данных, и Ampere, и RDNA 2 следуют одному и тому же принципу внутренней компоновки чипа. Разработчики игр используют в своей работе графические интерфейсы API, такие как Direct3D, OpenGL или Vulkan. По сути, это программные библиотеки, напичканные всевозможными правилами, структурами и инструкциями.
Драйверы, которые AMD и Nvidia пишут для своих чипов, фактически являются конвертерами: преобразуют процедуры, поступающие от API, в последовательность операций, понятную их графическим процессорам. Дальнейшее управление находится под контролем аппаратного обеспечения: определение приоритета команд, их адресация соответствующему узлу чипа, и так далее.
Эта первичная обработка команд осуществляется набором модулей, резонно размещаемым в центре чипа. В RDNA 2 графические и вычислительные шейдеры маршрутизируются через отдельные конвейеры, которые контролируют последовательность отправляемых команд остальной части чипа. Первый из них – это GCP (Graphics Command Processor), графический командный процессор, а второй – ACE (Asynchronous Compute Engines), асинхронный вычислительный конвейер.

Nvidia же просто использует одно имя для описания всего набора таких блоков управления – движок GigaThread Engine. В Ampere он выполняет ту же задачу, что и RDNA 2, хотя Nvidia не
слишком много информирует нас о подробностях работы этого модуля. В целом, эти командные процессоры работают как диспетчеры или как руководители производства на заводе.
Производительность GPU определяется их многозадачностью, поэтому следующий уровень организации – дублирование блоков на чипе. Если придерживаться аналогии с заводом, это будет похоже на бизнес, в котором есть центральный офис и несколько производственных площадей.
AMD называет эти блоки Shader Engine (SE), тогда как Nvidia зовёт их Graphics Processing Clusters (GPC) – слова разные, суть одна.

Причина такой организации проста: блоки обработки команд просто не могут эффективно выполнять всё сразу. Поэтому резонно распределить задачи между разными блоками. Каждый отдельный блок может выполнять что-то совершенно независимое от других – например, один может заниматься обработкой множества графических шейдеров, в то время как другие обрабатывают длинные сложные вычислительные шейдеры.
В случае RDNA 2, каждый SE содержит свой собственный набор фиксированных функциональных модулей: схем, которые обычно не регулируются программно и предназначенны для выполнения одной конкретной задачи.
- Модуль Primitive Setup (модуль настройки примитивов) – подготавливает вертексы к растеризации, а также генерирует дополнительные (тесселяция) и удаляет лишние
- Растеризатор – преобразует трехмерный мир треугольников в двухмерную пиксельную сетку
- Выводы рендеринга (модули ROP) – считывают, записывают и смешивают пиксели
Модуль настройки примитивов обрабатывает 1 треугольник за такт. Может показаться, что это немного, но не забывайте, что эти чипы работают на частотах от 1,8 до 2,2 ГГц, так что настройка примитивов вряд ли может стать причиной боттлнека в GPU. В Ampere блок примитивов находится на следующем уровне организации, и мы скоро к нему подойдём.
Ни AMD, ни Nvidia не дают подробной информации о своих растеризаторах. Последние называют их Raster Engines (растровый движок), и мы лишь знаем, что они обрабатывают 1 треугольник за такт и генерируют сколько-то пикселей, но нет никакой дополнительной информации, такой как их субпиксельная точность, например.
В каждом SE в чипе Navi 21 находится 4 банка по 8 модулей ROP, в результате чего получается 128 выходных блоков рендеринга; у GA102 от Nvidia – 2 банка по 8 ROP на каждый GPC, поэтому полный чип содержит 112 модулей. Может показаться, что AMD имеет преимущество, ведь большее количество ROP означает, что за такт может обрабатываться больше пикселей. Однако такие модули нуждаются в хорошем доступе к кэшу и локальной памяти, и ниже мы затронем эту тему. А пока продолжим рассмотрение организации самих блоков SE/GPC.

«Шейдерные движки» (SE) у AMD подразделены на то, что они называют «двойными вычислительными блоками» (DCU, Dual Compute Units), при этом чип Navi 21 имеет по десять DCU на один SE (обратите внимание, что зачастую в документации они также классифицируются как WGP, Workgroup Processor’ы). По терминологии Nvidia они называются кластерами обработки текстур (TPC, Texture Processing Clusters), и в случае Ampere и GA102 таких TPC в GPU – шесть. А сам кластер TPC содержит в себе нечто под названием Polymorph Engine – по сути, те же модули настройки примитивов Ampere.
Они тоже работают со скоростью 1 треугольник за такт, и хотя рабочая частота GPU Nvidia ниже, чем у AMD, у чипа Nvidia гораздо больше TPC, чем SE у Navi 21. Таким образом, если GA102 дать ту же тактовую частоту, то он должен иметь заметное преимущество, поскольку весь чип содержит 42 модуля настройки примитивов, в то время как у нового RDNA 2 от AMD их всего 4. Но поскольку на один Raster Engine приходится по шесть TPC, получается, что GA102 фактически имеет 7 полных модулей примитивов против 4 аналогичных у Navi 21. Казалось бы, чипу AMD недостаёт 75% скорости, чтобы сравняться с чипом Nvidia по производительности обработки геометрии (хотя, конечно, для игр это ещё далеко не всё).
Последний уровень организации чипов это вычислительные модули (CU, Compute Units) в RDNA 2 и потоковые мультипроцессоры (SM, Streaming Multiprocessors) в Ampere – производственные линии наших заводов по производству визуализации.
Это довольно широкопрофильные «цеха», поскольку они содержат все программируемые блоки, используемые для обработки графики, вычислений, а теперь ещё и шейдеров рейтрейсинга. Как вы можете видеть на изображении выше, каждый из них занимает очень небольшую часть площади кристалла, но они чрезвычайно сложны и непосредственно влияют на общую производительность чипа.
До сих пор принципиальной разницы между двумя GPU мы не наблюдали. Пока речь шла об общей компоновке и организации элементов на чипе, серьезных разногласий не было – номенклатура и терминология элементов разнятся, но их функции во многом схожи. И поскольку по большей части эти функции ограничены их программируемостью и гибкостью, то любые сравнения одного GPU с другим сводятся по сути просто к оценкам масштаба. То есть к тому, какой из них имеет больше какой-то конкретной вещи.
Но вот с CU/SM у AMD и Nvidia имеются отличия принципиальные – они используют разные подходы к обработке шейдеров. В чём-то у них много общего, но есть множество моментов, где их пути существенно расходятся.
Количество ядер Nvidia
Поскольку Ampere появился раньше RDNA 2, мы сначала рассмотрим SM Nvidia. Сейчас нет смысла разглядывать макрофотографии кристаллов, поскольку на них мы не увидим внутреннее строение блоков SM/CU, поэтому обратимся к схемам, иллюстрирующим не компоновку элементов, а динамику изменения количества всех типов этих элементов от чипа к чипу.
Если Turing привнёс довольно кардинальные изменения по сравнению со своим десктопным предшественником Pascal (вместо блоков и регистров FP64, получив тензорные ядра и трассировку лучей), то Ampere выглядит довольно легким апгрейдом – по крайней мере, на
первый взгляд. По заявлениям же маркетингового подразделения Nvidia, новая разработка более чем вдвое увеличила количество ядер CUDA в каждом SM.
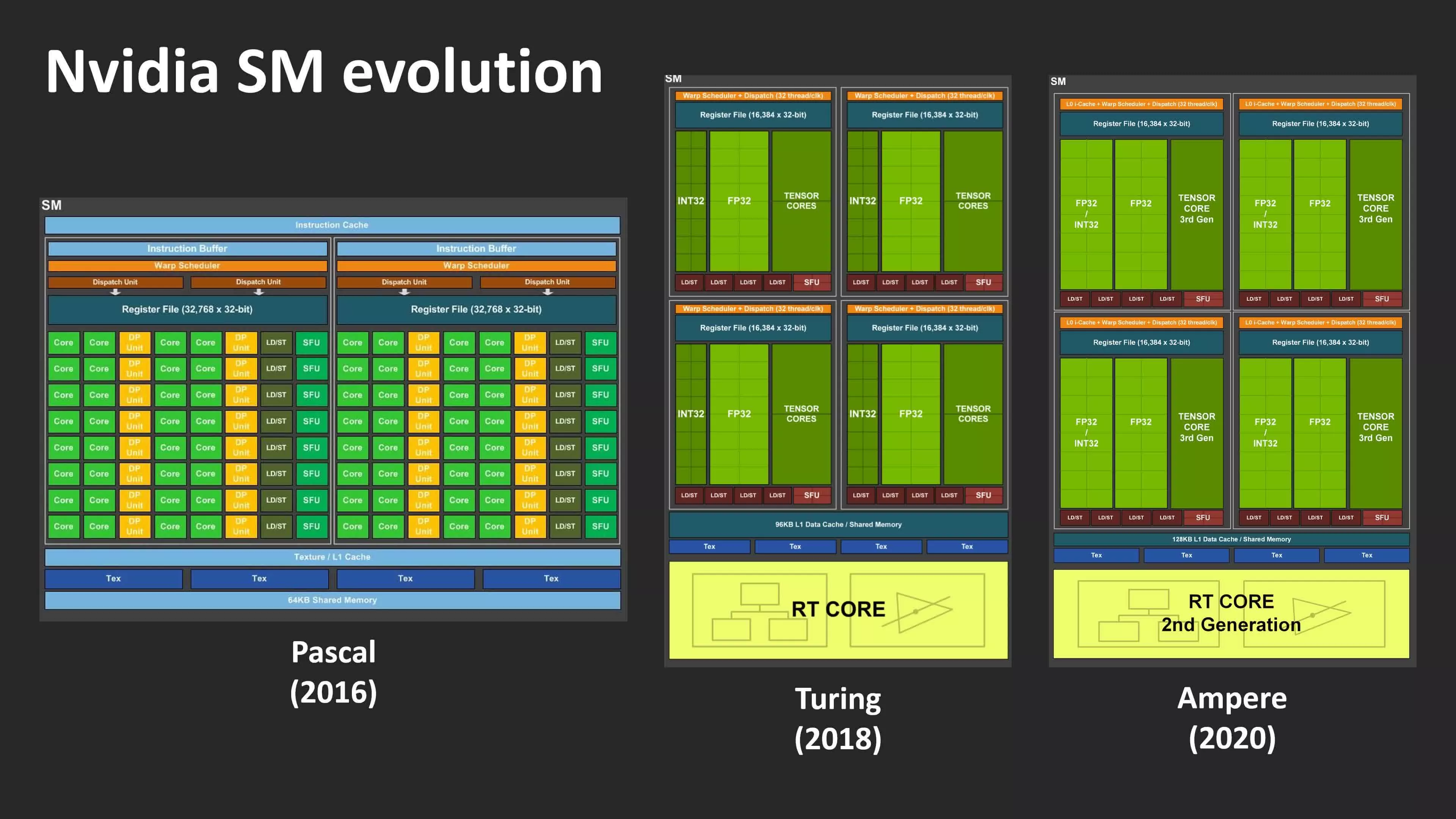
В Turing потоковые мультипроцессоры SM содержат четыре раздела (иногда называемые блоками обработки – processing blocks), в каждом из которых находятся логические блоки 16x INT32 и 16x FP32. Эти схемы предназначены для выполнения очень специфических математических операций с 32-битными данными: блоки INT обрабатывают целые числа, а блоки FP работают со значениями с плавающей точкой, то есть десятичными числами.
Nvidia заявляет, что SM в Ampere имеет в общей сложности 128 ядер CUDA, что, строго говоря, неправда – либо же, если это действительно так, то и в Turing столько же. Блоки INT32 в Turing действительно могли обрабатывать значения с плавающей точкой, но только в очень небольшом количестве простых операций. В Ampere Nvidia ввела ряд поддерживаемых математических операций с плавающей точкой, чтобы обеспечить совместимую работу с другими блоками FP32. Это означает, что общее количество ядер CUDA на один SM в действительности не изменилось, просто половина из них теперь имеет больше возможностей.
Все ядра в каждом разделе SM обрабатывают одну и ту же инструкцию в каждый момент времени, но, поскольку блоки INT/FP могут работать независимо, SM в Ampere может обрабатывать до 128 вычислений FP32 за цикл, либо 64 операций FP32 + 64 операций INT32. В Turing был возможен только второй вариант.
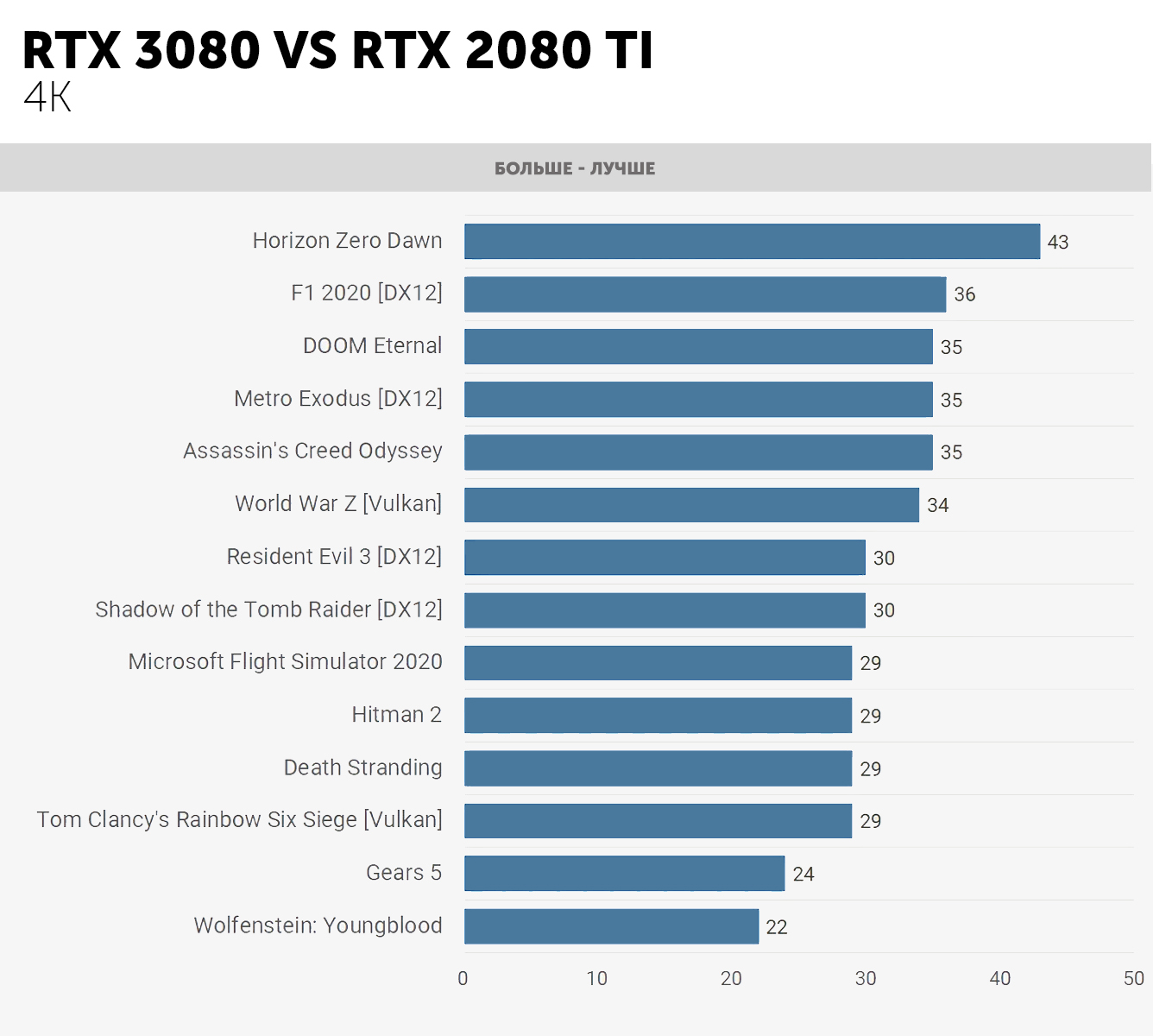
Таким образом, новый GPU потенциально может удвоить производительность FP32 по сравнению с его предшественником. Для вычислительных рабочих нагрузок, особенно в профессиональных приложениях, это большой шаг вперед, но для игр польза от этого невелика. Это стало очевидно, когда мы впервые протестировали GeForce RTX 3080, в которой используется чип GA102 с 68-ю активными SM.
Несмотря на то, что пиковая пропускная способность FP32 составляет 121% по сравнению с GeForce 2080 Ti, в среднем она увеличивает частоту кадров только на 31%. Так почему же вся эта вычислительная мощность тратится зря? Ответ прост: нет, не зря, просто игры не всегда используют инструкции FP32.
Когда Nvidia выпустила Turing в 2018 году, они тогда отметили, что в среднем около 36% инструкций, обрабатываемых графическим процессором, относятся к процедурам INT32. Эти вычисления обычно выполняются для определения адресов памяти, сравнения двух значений и диспетчеризации логических потоков.

Так что для этих операций функция двойной скорости FP32 не работает, поскольку блоки с поддержкой двух типов данных могут работать либо только с целыми числами, либо только с плавающей точкой. SM-раздел переключится на эту функцию лишь в том случае, когда все 32 потока, обрабатываемые им в данный момент, имеют одну и ту же операцию FP32, выстроенную в очередь для обработки. Во всех остальных случаях разделы в Ampere работают так же, как и в Turing.
Это означает, что по обработке FP32 GeForce RTX 3080 имеет преимущество только в 11% над 2080 Ti при работе в режиме INT+FP. Вот почему реальный прирост производительности в играх не столь значителен, как можно было бы предположить.
Какие есть ещё улучшения? На каждый SM-раздел теперь приходится меньше тензорных ядер, но каждое из них намного более функционально, чем в Turing. Эти схемы выполняют очень специфические вычисления (например, умножают два значения FP16 и складывают ответ с другим числом FP16), и теперь каждое ядро выполняет 32 таких операций за цикл.
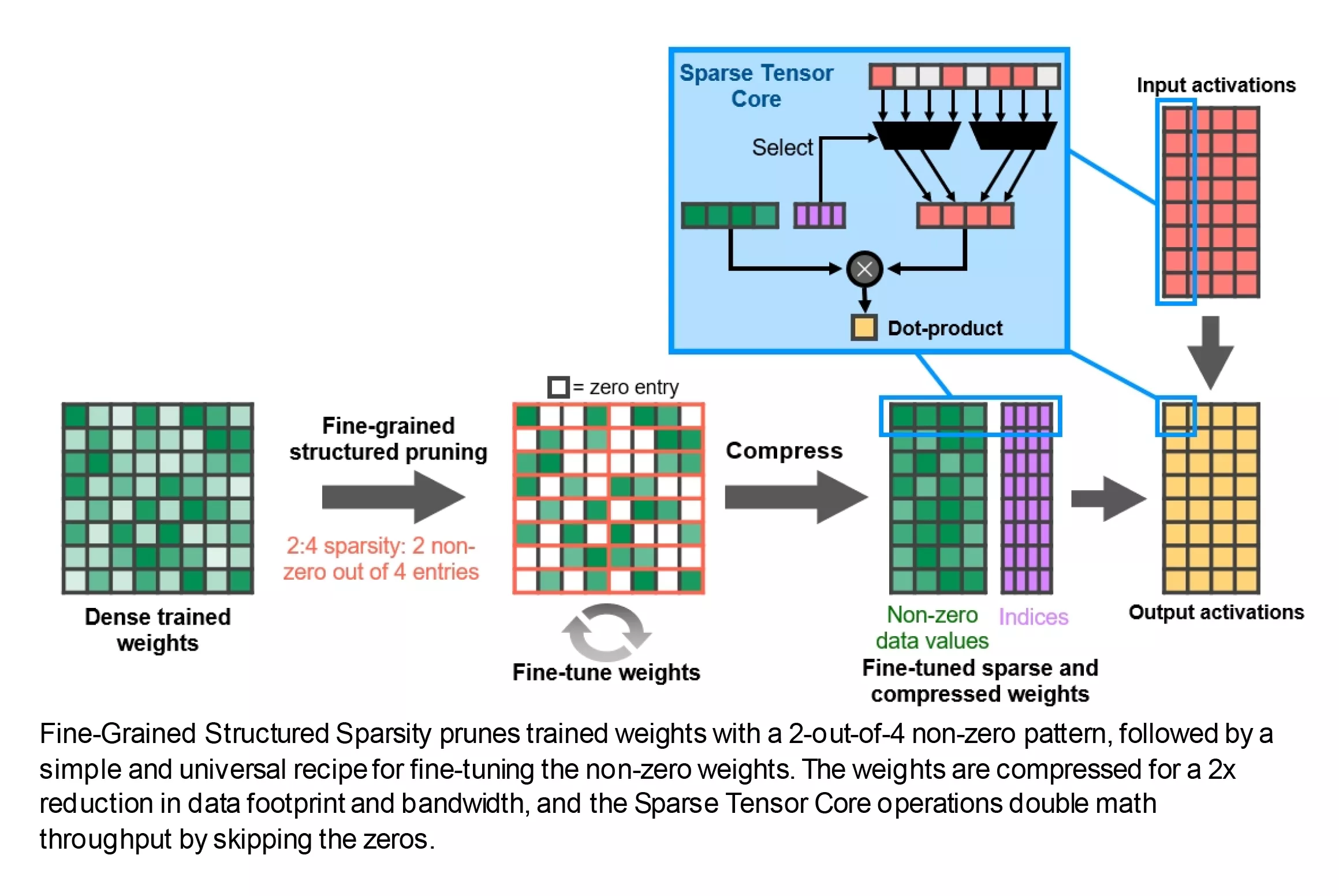
Кроме того, представлена новая функция под названием Fine-Grained Structured Sparsity («тонкоструктурированная разреженность»), и, если не вдаваться в подробности, то по сути это означает, что математическая скорость может быть удвоена путем удаления данных, не влияющих на ответ. Опять же, это хорошая новость для профессионалов, работающих с нейронными сетями и искусственным интеллектом, но для разработчиков игр это не особо погоду меняет.
RT-ядра также были доработаны: теперь они могут работать независимо от ядер CUDA, поэтому, пока они работают с алгоритмом BVH или вычисляют пересечения лучей и примитивов, остальная часть SM может продолжать обрабатывать какие-то шейдеры. И та часть RT-ядра, которая проверяет, пересекает ли луч примитив или нет, также увеличила производительность вдвое.
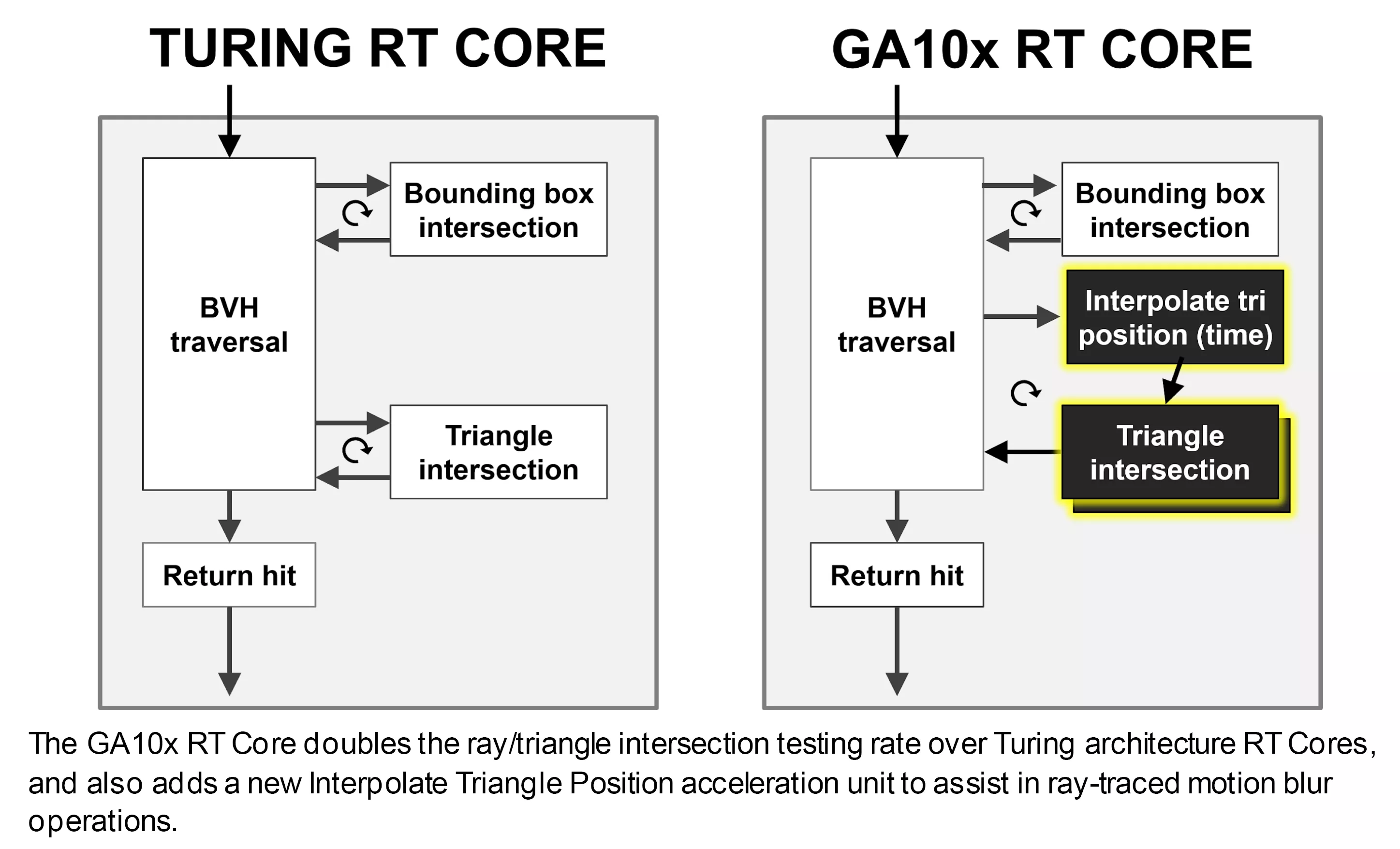
Кроме того, ядра трассировки теперь дополнены схемами, облегчающими применение рейтресинга к размытию в движении, но эта функция доступна пока только через проприетарный движок Nvidia Optix API.
А также ряд других доработок. В целом подход основан на рациональной устойчивой эволюции, а не на чем-либо революционном. Учитывая, что по своим возможностям архитектура Turing с самого начала показала себя совсем неплохо, наблюдаемая сегодня картина выглядит совершенно закономерно.
Ну а теперь – что насчет AMD? Что они сделали со своими CU, вычислительными модулями, в RDNA 2?
Очарование рейтрейсинга
На первый взгляд, AMD не сильно изменила вычислительные модули – они по-прежнему содержат два векторных блока SIMD32, скалярный блок SISD, блоки текстур и комплект различных кэшей. Некоторые изменения произошли в отношении того, какие типы данных и связанные с ними математические операции могут выполняться ими, и мы поговорим об этом чуть позже. Для обычного пользователя же наиболее заметным изменением является то, что AMD теперь предлагает аппаратное ускорение для определенных процедур рейтрейсинга.
Эта часть CU выполняет проверки пересечения луча с треугольником или кубом – то же, что и RT-ядра в Ampere. Однако последние также ускоряют алгоритмы BVH, тогда как в RDNA 2 это реализовано с помощью вычислительных шейдеров с использованием блоков SIMD32.
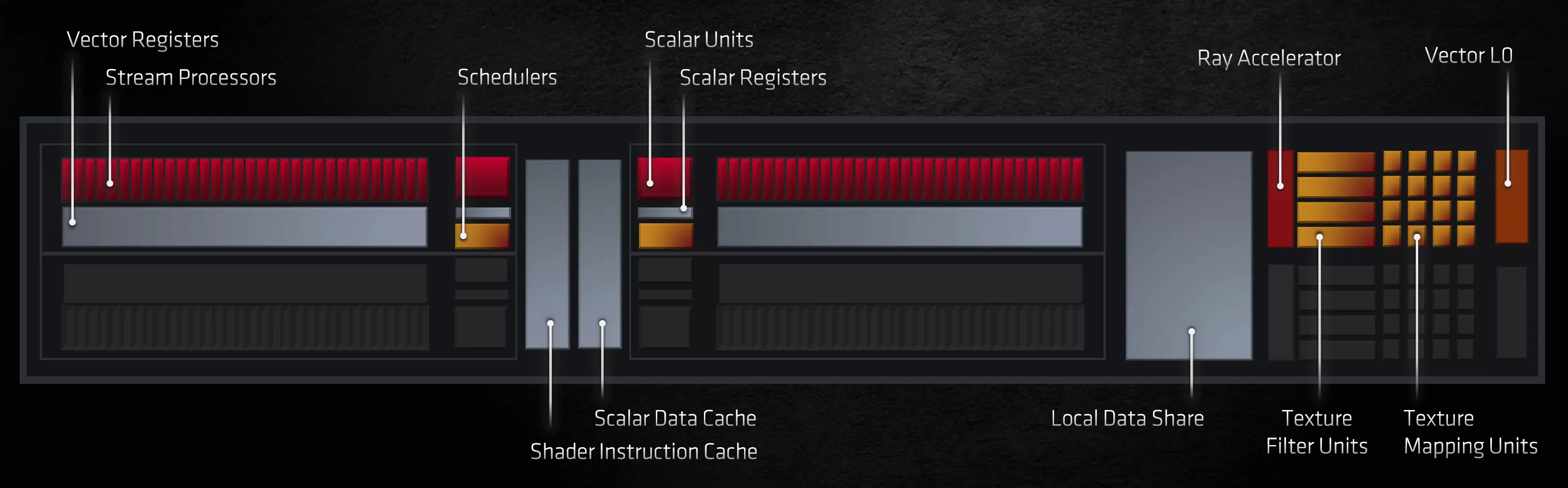
Независимо от того, сколько у вас шейдерных ядер или насколько высоки их тактовые частоты, использование специализированных схем, предназначенных для выполнения только одной задачи, всегда будет лучше, чем универсализированный подход. Именно поэтому и появились GPU – какой угодно рендеринг может сделать и CPU, но его универсализированная природа претит ему заниматься столь специфичными нагрузками.
Модули ускорителей лучей (RA units, Ray Accelerators) находятся рядом с текстурными процессорами, потому что они фактически являются частью одной структуры. Еще в июле 2019 года мы сообщали о регистрации патента, поданного AMD, в котором подробно описывался «гибридный» подход к обработке ключевых алгоритмов трассировки лучей...
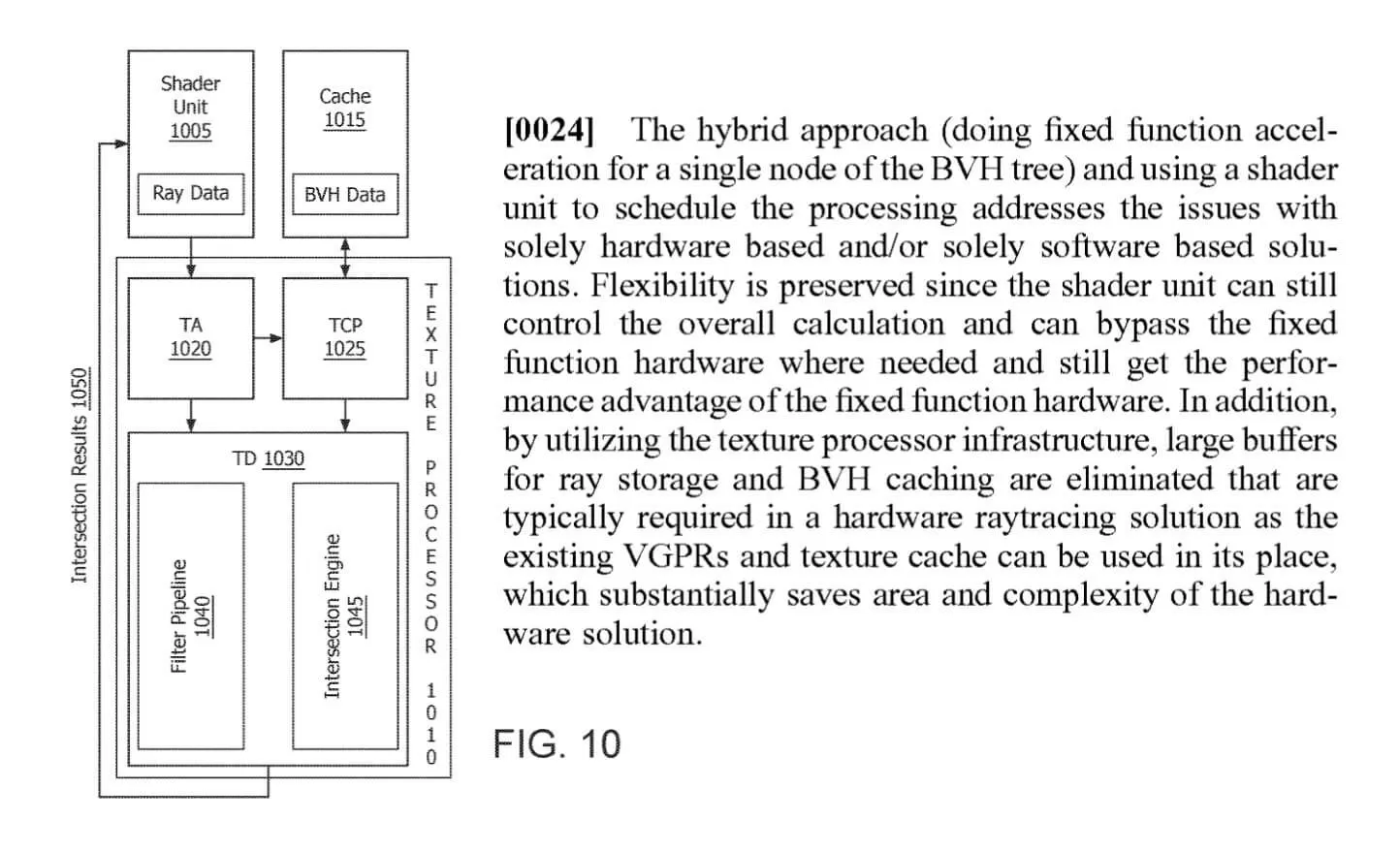
Хотя эта система действительно более гибкая и более рационально распределяет нагрузку по трассировке лучей, ее первая реализация у AMD не лишена недостатков. Наиболее заметный из них в том, что в каждый момент времени текстурные процессоры способны обрабатывать либо только операции, связанные с текстурами, либо только с пересечениями лучей с примитивами.
Учитывая, что RT-ядра у Nvidia теперь работают полностью независимо от остальной части SM, это, казалось бы, дает Ampere явное преимущество по сравнению с RNDA 2 в плане проработки структур ускорения и проверки пересечений рейтрейсинга.
Мы лишь бегло взглянули на производительность рейтрейсинга в новейших видеокартах AMD, но этого было достаточно, чтобы убедиться, что она сильно зависит от игры.
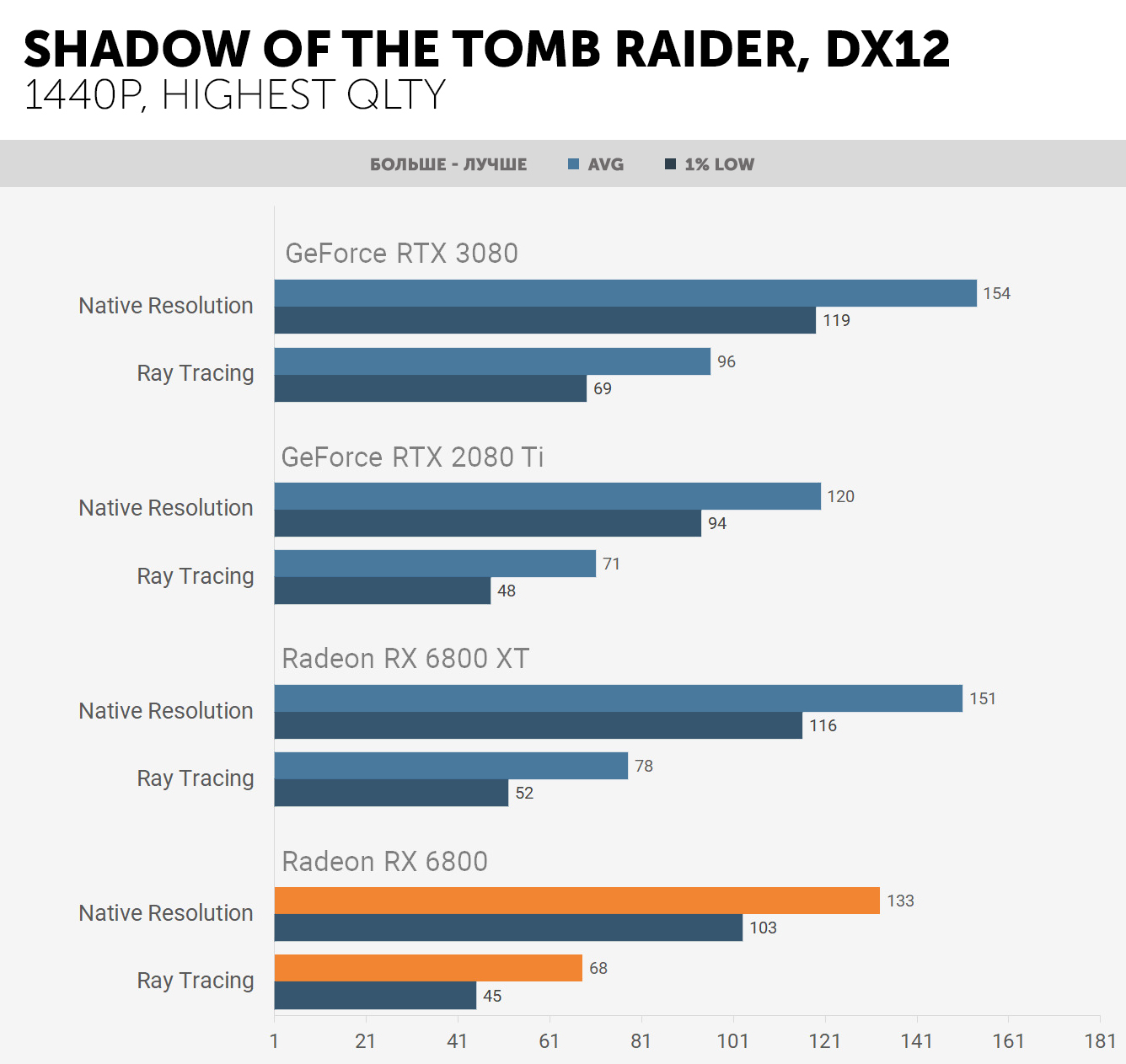
Например, при игре в Gears 5 на Radeon RX 6800 (который использует вариант GPU Navi 21 с 60-ю CU) частота кадров падала только на 17%, тогда как в Shadow of the Tomb Raider FPS снижался в среднем до 52%. Для сравнения, у Nvidia RTX 3080 (GA102 с 68-ю SM) средние потери FPS составили 23% и 40% соответственно в двух играх.
Чтобы больше рассказать об этой технологии AMD, необходим более детальный анализ рейтрейсинга, но в качестве первого отклика на неё можно сказать, что она выглядит конкурентоспособной, но чувствительной к тому, какое приложение выполняет трассировку лучей.
Как уже говорилось, вычислительные блоки (CU) в RDNA 2 теперь поддерживают больше типов данных. Прежде всего, надо отметить типы данных с низкой точностью, такие как INT4 и INT8. Они используются для тензорных операций в алгоритмах машинного обучения, и хотя AMD имеет отдельную архитектуру (CDNA) для ИИ и дата-центров, это обновление предназначено для использования с DirectML.
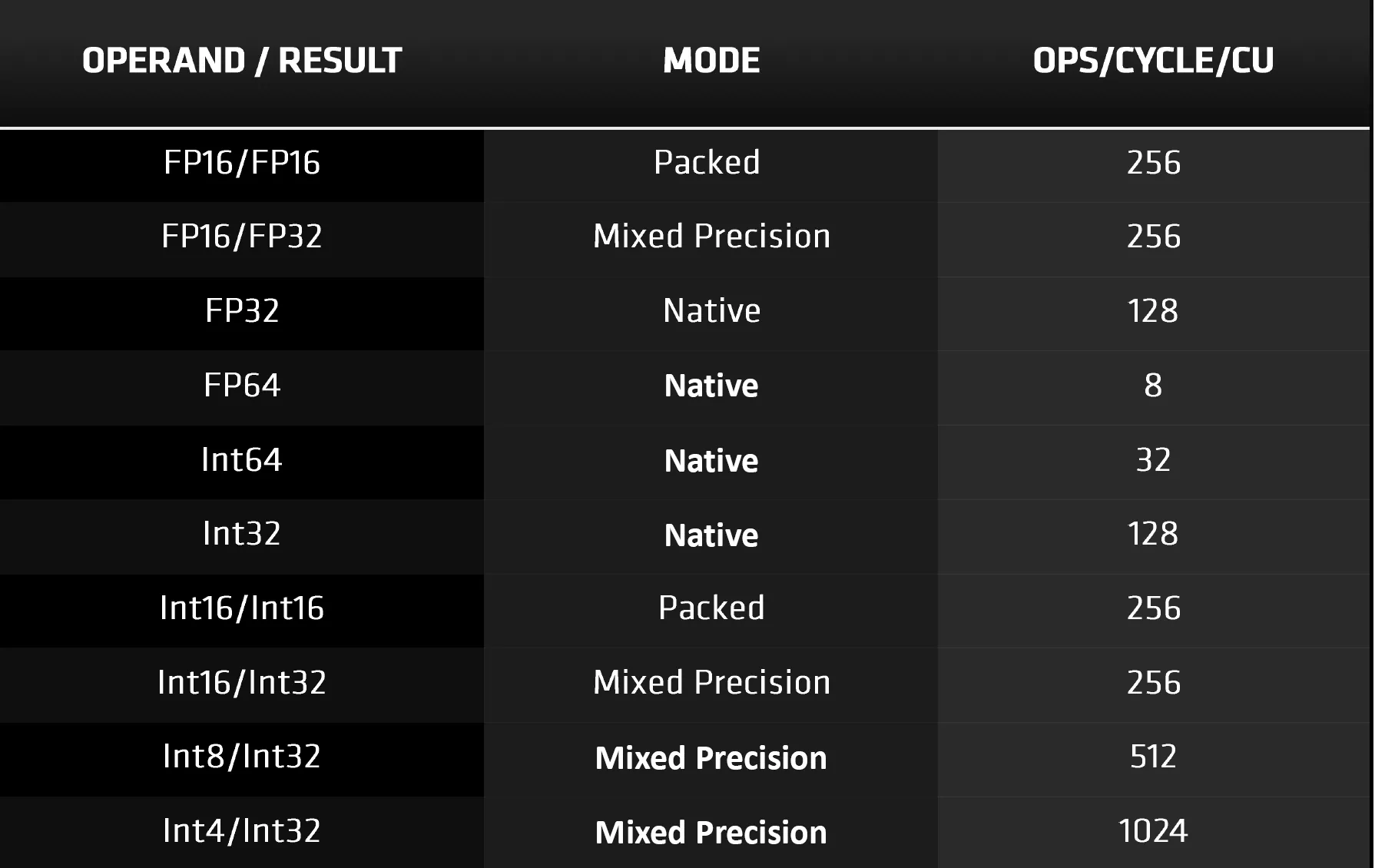
Этот API является недавним дополнением к семейству Microsoft DirectX 12, и сочетание аппаратного и программного обеспечения предоставляет возможность улучшить скорость шумоподавления в алгоритмах трассировки лучей и промежуточного масштабирования. Что касается последнего, то у Nvidia, конечно же, есть своя технология под названием DLSS. Их система использует тензорные ядра в SM для выполнения части вычислений, но, учитывая, что аналогичный процесс может быть построен посредством DirectML, может показаться, что эти модули в некотором смысле избыточны. Однако и в Turing, и в Ampere тензорные ядра также обрабатывают все математические операции формата FP16.
В RDNA 2 подобные вычисления выполняются с помощью шейдерных блоков (SU, shader units), используя форматы пакованных данных, то есть каждый 32-битный векторный регистр содержит два 16-битных. Так чей же подход лучше? AMD называет свои блоки SIMD32 векторными процессорами, поскольку они выдают единую инструкцию для нескольких значений данных.
Каждый векторный блок содержит 32 потоковых процессора (SM, Stream Processor), и поскольку каждый из них работает только с одним фрагментом данных, сами операции фактически носят скалярный характер. По сути, это то же самое, что и SM-раздел в Ampere, где каждый блок обработки также несет одну инструкцию для 32 значений данных.
Но если у Nvidia каждый SM может обрабатывать до 128 вычислений FP32 FMA (Fused Multiply-Add, «умножение-сложение с однократным округлением») за цикл, то в RDNA 2 один CU выполняет только 64. Использование FP16 увеличивает это значение до 128 FMA за цикл, что совпадает с Ampere при выполнении стандартных вычислений FP16 тензорными ядрами.
Потоковые мультипроцессоры (SM) Nvidia могут одновременно обрабатывать инструкции для целочисленных и FP-значений (например, 64 FP32 и 64 INT32) и имеют независимые модули для FP16 операций, тензорной математики и для процедур рейтрейсинга. Вычислительные блоки (CU) AMD выполняют большую часть рабочей нагрузки с помощью блоков SIMD32, хотя у них есть отдельные скалярные блоки, поддерживающие простую целочисленную математику.
Таким образом, создаётся впечатление, что здесь преимущество за Ampere: у GA102 больше SM, чем CU у Navi 21, и у них больше возможностей в плане пиковой пропускной способности, гибкости и предлагаемых функций. Между тем, у AMD в рукаве припрятана одна очень неплохая карта.
Миссия: прокормить голодных бегемотов
Система памяти, многоуровневые кэши
GPU с тысячами логических блоков, которым покорны все затейливости математики – это, конечно, хорошо. Но они будут совершенно беспомощны, если не будут получать необходимые инструкции и данные с достаточной скоростью. Обе новые разработки имеют множество многоуровневых кэшей с огромной пропускной способностью.
Взглянем на Ampere сперва. В целом, внутри произошли некоторые заметные изменения. Объем кэша L2 увеличился на 50% (Turing TU102 имел 4096 Кб), а кэши L1 в каждом SM увеличились вдвое.

Как и прежде, кэши L1 конфигурируются в зависимости от того, сколько памяти в них можно выделить для данных, текстур или общих вычислений. Однако для графических шейдеров (вертексных, пиксельных, и т.п.), а также для асинхронных вычислений кэш фактически установлен следующим образом:
- 64 Кб для текстур и данных
- 48 Кб для общей основной памяти
- 16 Кб зарезервировано для особых операций
Полностью настраиваемым кэш первого уровня (L1) становится лишь при работе в режиме полноценных вычислений. С другой стороны, доступная пропускная способность также удвоилась, поскольку теперь кэш может считывать/записывать 128 байтов за такт (хотя нет ни слова о том, увеличилась ли при этом латентность).
Остальная часть внутренней памяти в Ampere осталась прежней, но за пределами GPU нас ждет сюрприз. Nvidia привлекла к проекту знаменитого производителя DRAM – компанию Micron, чтобы использовать модифицированную версию GDDR6 для локальной памяти. По сути, это обычная GDDR6, только шина данных полностью заменена. Вместо использования классического варианта PAM (Pulse-Amplitude Modulation, «амплитудно-импульсная модуляция») – 1 бит на пин, при котором сигнал быстро-быстро колеблется между двумя напряжениями, GDDR6X использует четыре напряжения:
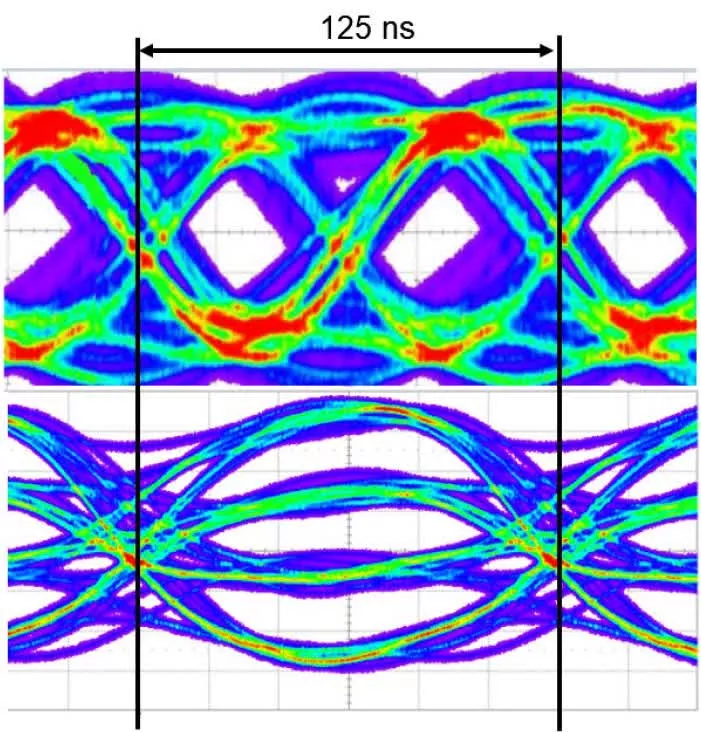
PAM-2 в GDDR6 (сверху) vs PAM-4 в GDDR6X (снизу)
Благодаря этому, GDDR6X эффективно передает 2 бита данных на пин за цикл, поэтому при той же тактовой частоте и количестве пинов пропускная способность удваивается. GeForce RTX 3090 поддерживает 24 модуля GDDR6X, работающих в одноканальном режиме и рассчитанных на 19 Гбит/с, что дает пиковую пропускную способность 936 Гб/с.
Это на 52% больше, чем у GeForce RTX 2080 Ti, и это не то, на что можно махнуть рукой. Такие показатели пропускной способности в прошлом были достигнуты только при использовании HBM2, реализация которого более дорогостоящая по сравнению с GDDR6.
Как бы то ни было, такую память производит только Micron; внедрение технологии PAM-4 добавляет сложности производственному процессу, требуя гораздо более жестких допусков при передаче сигналов. AMD пошла по другому пути: вместо того, чтобы обращаться за помощью к специалистам со стороны, они озадачили собственное подразделение CPU, чтобы предложить что-то новое. Общая система памяти в RDNA 2 мало чем отличается по сравнению с предшественником, но есть пара значительных изменений.

Каждый шейдерный движок (SE) теперь имеет два набора кэшей 1 уровня, и это понятно, ведь теперь они содержат по два банка двойных вычислительных модулей DCU (у RDNA был только один). Но запихать 128 Мб кэша L3 в GPU?! Вот это многих удивило. Применив технологию SRAM для кэша L3, как уже было ими испытано на серверных чипах Zen 2 серии EPYC, AMD встроила в чип два набора кэш-памяти высокой плотности объемом по 64 Мб. Транзакции данных управляются 16-ю интерфейсами, каждый из которых передаёт 64 байта за такт.
Этот так называемый Infinity Cache («бесконечный кэш») имеет свой собственный тактовый домен и может работать на частоте 1,94 ГГц, обеспечивая пиковую внутреннюю пропускную способность 1986,6 Гб/с. А поскольку это не внешняя DRAM, задержки здесь исключительно низкие. Такой кэш идеально подходит для хранения структур ускорения рейтрейсинга, а также для обработки BVH-структур с большим количеством проверок данных.

Две 64-мегабайтные полосы кэша Infinity Cache и системы Infinity Fabric
Пока неясно, работает ли L3 кэш в RDNA 2 так же, как в CPU Zen 2: то есть как жертвенный L2 кэш (victim cache). Обычно, когда необходимо очистить последний уровень кэша, чтобы освободить место для новых данных, любые новые запросы этой информации адресуются DRAM.
Жертвенный кэш хранит данные, помеченные на удаление из следующего уровня памяти, и имея под рукой 128 Мб L3, Infinity Cache потенциально может хранить 32 полных набора кэша L2. Такая система снижает нагрузку на DRAM и контроллеры GDDR6.
В прошлом, GPU от AMD страдали от нехватки внутренней пропускной способности, особенно после того, как была увеличена их тактовая частота. Системам экстра-кэша пришлось пройти немалый путь прежде, чем эта проблема ушла на второй план.
Кто же предложил здесь наиболее удачное решение? Использование GDDR6X дает GA102 огромную полосу пропускания для локальной памяти, а большие кэши смягчают влияние кэш-промахов (останавливающих обработку потока). Массивный кэш 3-го уровня в Navi 21 означает, что нет нужды так часто обращаться к DRAM, и позволяет GPU работать на более высоких тактовых частотах без дефицита данных.
Решив придерживаться стандарта GDDR6, AMD предоставила третьим сторонам свободу выбора производителей памяти, в то время как любой компании, производящей видеокарты на базе GeForce RTX 3080 или 3090 придётся иметь дело только с Micron. Кроме того, на сегодняшний день модули GDDR6X производятся только объёмом 8 Гб, в то время как память GDDR6 доступна любая из возможных.
Система кэширования в RDNA 2, скорее всего, лучше, чем та, которая предложена в Ampere, поскольку использование нескольких уровней встроенной SRAM всегда обеспечивает более низкие задержки и лучшую производительность, чем внешняя DRAM, какая бы пропускная способность у неё ни была.
Входы/выходы GPU
Конвейеры рендеринга
Обе архитектуры предлагают множество frontend/backend-обновлений для конвейеров рендеринга. Ampere и RDNA 2 полностью поддерживают сеточные шейдеры (Mesh Shaders) и шейдеры с переменной частотой затенения (VRS, Variable Rate Shaders) в DirectX12 Ultimate, хотя производительность геометрии у чипа Nvidia действительно выше благодаря большему количеству процессоров для этих задач.
С помощью Mesh Shaders, разработчики, конечно, будут создавать ещё более реалистичные миры, но ни одна игра не имеет критической зависимости от этого этапа рендеринга. Всё потому, что основная и самая сложная часть работы приходится на этапы пикселизации и трассировки лучей.
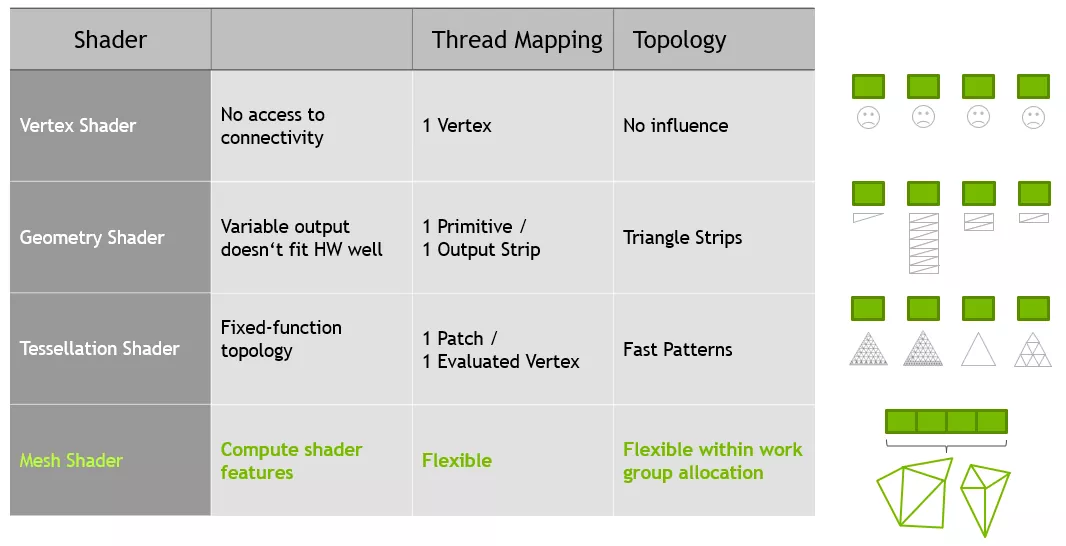
Именно здесь в игру вступают шейдеры VRS – как правило, к пиксельным блокам применяются шейдеры сразу для освещения и цвета, а не каждый шейдер по отдельности. Процесс похож на уменьшение разрешения игры для повышения производительности, но, поскольку его можно применить только к выбранным регионам, потеря визуального качества не всегда очевидна.
Но в обеих архитектурах были также обновлены модули ROP (модули вывода рендеринга) для улучшения производительности на высоких разрешениях независимо от того, используются ли шейдеры VRS. Nvidia во всех своих предыдущих поколениях GPU привязывала ROP к контроллерам памяти и кэшу L2.
В Turing восемь модулей ROP (вместе называемых ROP partition) были напрямую связаны с одним контроллером и частью кэша, ограниченной в 512Кб. Добавление большего количества ROP проблематично, поскольку для этого требуется больше контроллеров и объёма кэша, поэтому в Ampere ROP полностью размещены в графических кластерах GPC (Graphics Processing Clusters). GA102 имеет 16 модулей ROP на один GPC (каждый из которых обрабатывает 1 пиксель за такт), что дает в общей сложности 112 ROP-модулей на весь чип.
AMD следуют принципу, аналогичному старому подходу Nvidia (т.е. контроллер памяти и часть кэша L2), хотя их модули ROP в основном используют кэш L1 для чтения/записи/блендинга пикселей. Столь критичное обновление они получили в чипе Navi 21, и теперь каждый ROP-partition обрабатывает по 8 пикселей за цикл в 32-битном цвете и по 4 пикселя в 64-битном.
Еще одно новшество, добавленное в Ampere – это система обработки данных RTX IO, которая позволяет GPU напрямую обращаться к накопителю, копировать нужные данные, а затем распаковывать их с помощью ядер CUDA. Однако на данный момент эта система не может использоваться ни в одной игре, потому что Nvidia использует DirectStorage API (еще одно расширение DirectX12) для управления ею, релиз которого ещё не состоялся.

Используемые в настоящее время методы предполагают, что всем этим управляет центральный процессор: получает запрос данных от драйверов GPU, копирует данные с накопителя в системную память, распаковывает их, и наконец копирует в DRAM видеокарты.
Мало того, что здесь налицо масса бесполезного копирования, но и механизм действий является по своей природе последовательным – CPU обрабатывает один запрос за раз. Nvidia заявляет о таких цифрах, как «100-кратная пропускная способность» и «20-кратное снижение нагрузки ЦП», но пока эта система не будет протестирована в реальном мире, эти цифры останутся только именно заявлениями.

Вместе с релизом RDNA 2 и новой линейки видеокарт Radeon RX 6000, AMD представила технологию Smart Access Memory (SAM). Нет, это не их ответ на RTX IO от Nvidia, и это даже не новая функция. По умолчанию, контроллер PCI-E в CPU может адресовать до 256 Мб памяти VRAM на каждый отдельный запрос доступа.
Точное значение определяется размером регистра базового адреса (BAR, Base Address Register), и еще в 2008 году в спецификации PCI Express 2.0 появилась дополнительная функция, позволяющая изменять его размер. Польза этого состоит в уменьшении количества запросов на доступ при необходимости адресовать всю DRAM видеокарты.
Данная функция требует поддержки со стороны операционной системы, процессора, материнской платы, GPU и его драйверов. В настоящее время на ПК с Windows работоспособность этой
функции осуществима только при определенной конфигурации: у вас должны быть процессор Ryzen 5000, материнская плата серии 500 и видеокарта Radeon RX 6000.

Эта простая функция дала поразительные результаты, когда мы ее протестировали – повышение производительности на 15% при разрешении 4K это не мелочи, поэтому неудивительно, что Nvidia пообещала тоже внедрить подобную функцию в линейку RTX 3000 в ближайшем будущем.
Будет или нет развернута полномасштабная поддержка регулируемого BAR – покажет время, но такая функция, безусловно, приветствуется, пусть это и не относится к архитектуре Ampere/RDNA 2.
«Техника чудес, воплощение грёз…»
Мультимедийный движок, видеовыход
В мире графических процессоров мы привыкли слышать о количестве ядер, терафлопсах, гигабайтах в секунду и прочих ярких показателях, но благодаря росту числа производителей контента на YouTube и игровым стримам в реальном времени, стоит признать, что возможности дисплея и мультимедийного движка также имеют большое значение.
Спрос на мониторы со сверхвысокой частотой обновления на всех разрешениях вырос, поскольку цена мониторов, поддерживающих такие режимы, упала. Пару лет назад монитор 144Гц 4K 27 дюймов HDR обошёлся бы вам в 2000 долларов, сегодня же вы можете купить нечто подобное вдвое дешевле.
Обе наши архитектуры обеспечивают вывод изображения через HDMI 2.1 и DisplayPort 1.4a. Первый отличается более широкой полосой пропускания сигнала, но оба они рассчитаны на 4K при 240Гц с HDR и 8K при 60Гц. Это достигается либо с помощью цветовой субдискретизации (chroma subsampling) в формате 4:2:0, либо с помощью DSC 1.2a. Это алгоритмы сжатия видеосигнала, которые обеспечивают значительное снижение требований к полосе пропускания при минимальной потере качества картинки. Без них даже HDMI 2.1 со своей пиковой пропускной способностью в 6 Гб/с не справился бы с передачей картинки 4K с частотой 6Гц.

48-дюймовый CK OLED «мониторчик» от LG: для режима 4K при 120Гц необходимо соединение HDMI 2.1
Ampere и RDNA 2 также поддерживают системы VRR (Variable Refresh Rate, «переменная частота обновления») – FreeSync у AMD, G-Sync у Nvidia, – и в плане кодирования/декодирования видеосигналов существенных отличий нет.
У обоих процессоров вы найдёте поддержку декодирования 8K AV1, 4K H.264 и 8K H.265, правда, как на деле они справляются с такими режимами – ещё не было достаточно хорошо проверено. Ни одна из компаний не раскрывает подробностей о внутреннем устройстве своих экранных и мультимедийных движков. Какими бы важными они ни были в наши дни, всё внимание по-прежнему отдаётся другим узлам GPU.
На вкус и цвет товарищей нет
Играм – игровое, вычислениям – вычислительное
Знатоки истории GPU знают, что прежде AMD и Nvidia использовали довольно разные подходы к выбору архитектуры и конфигураций. Но по мере того, как 3D-графика становилась все более популярной, а разрозненные API приводились к однородности, конструктивных отличий становилось всё меньше.
И уже не столько требования рендеринга в современных играх задают тон архитектурам, сколько определяющий направление рыночный сектор видеокарт. На момент написания этой статьи у Nvidia было три чипа, использующих технологию Ampere: GA100, GA102 и GA104.

GA104 устанавливается в картах GeForce RTX 3060 Ti
GA104 – это просто урезанная версия GA102: у него меньше текстурных кластеров (TPC) на каждый графический кластер GPC, и на треть обрезан кэш L2. В остальном все точно так же. А GA100 – это вообще другое животное.
Оно полностью лишено RT-ядер и ядер CUDA с поддержкой INT32+FP32. Вместо этого, в нём имеется множество дополнительных модулей FP64, больше систем чтения/записи и огромный объем кэшей L1 и L2. Также, у него нет дисплейного и мультимедийного движков – просто потому, что этот GPU был разработан исключительно для крупномасштабных вычислительных кластеров ИИ и работы с данными.
В свою очередь, GA102 и 104 нацелены на все остальные рынки, интересующие Nvidia: геймеры, аниматоры, профессиональные художники, а также инженеры и их небольшие системы для ИИ и вычислений. Ampere должен быть «мастером на все руки» – задача не из легких.

AMD Arcturus на архитектуре CDNA. Площадь кристалла этого монстра – 750 мм2
RDNA 2 разрабатывалась прежде всего в расчете на игры – как для ПК, так и для консолей. Хотя, она вполне могла бы быть столь же универсальной, как и Ampere. Как бы то ни было, AMD решила поддерживать свою архитектуру GCN, развивая её в соответствии с актуальными требованиями профессиональных таргет-клиентов.
Там, где RDNA 2 породила «Big Navi», CDNA, можно сказать, породила «Big Vega» – в ускорителе Instinct MI100 находится их чип Arcturus, состоящий из 50 миллиардов транзисторов. Этот графический процессор имеет 128 вычислительных блоков, и, как и GA100 от Nvidia, избавлен от экранных и мультимедийных движков.
И хотя Nvidia в значительной степени доминирует на профессиональном рынке с моделями Quadro и Tesla, GPU, подобные Navi 21, попросту относятся к другой категории и не нацелены на конкуренцию с ними. Делает ли это RDNA 2 лучшей архитектурой? Помешает ли это каким-либо образом тому, чтобы Ampere вписался сразу на несколько рынков?
Судя по всем признакам, ответ будет: нет.
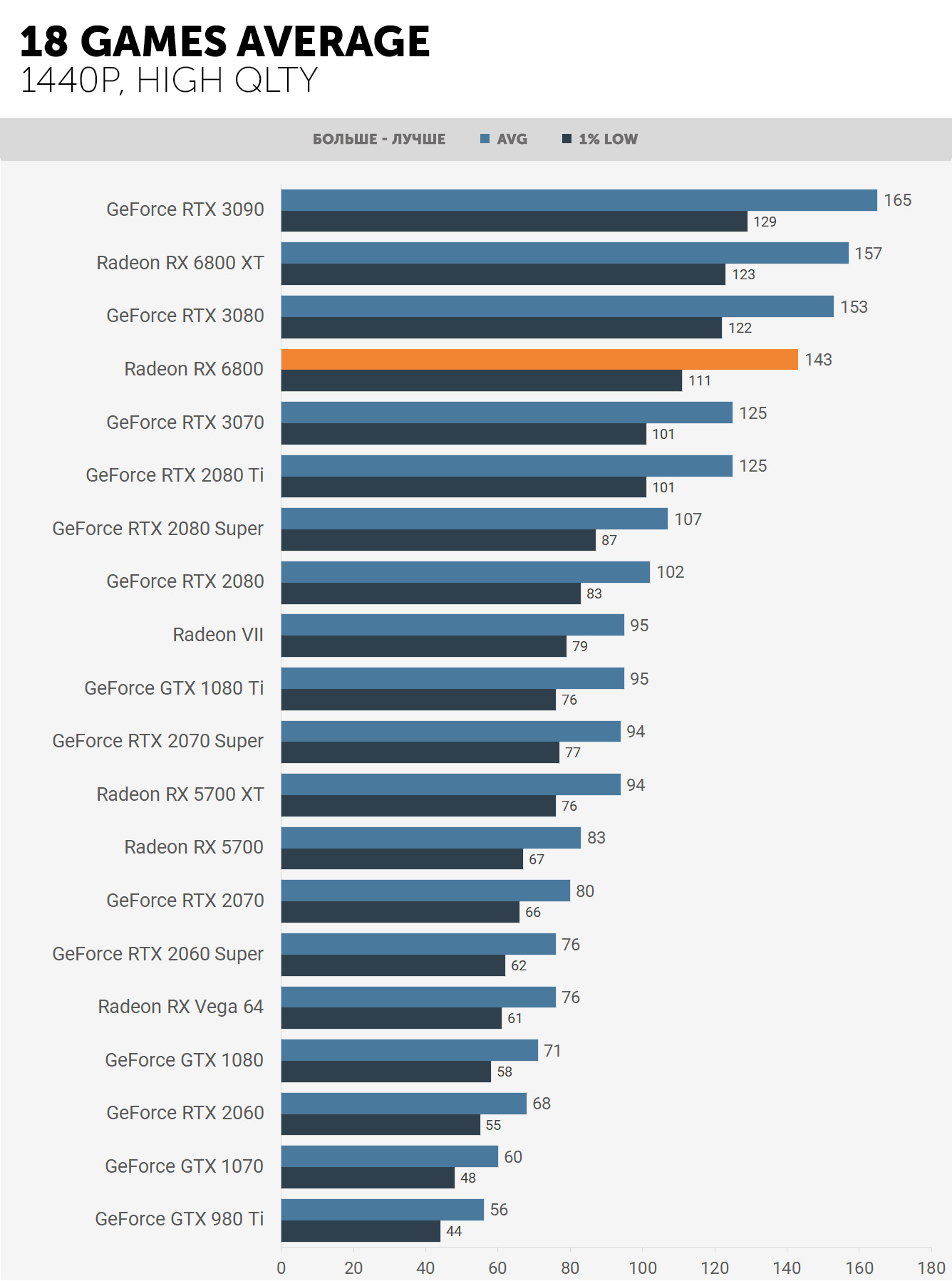
Скоро AMD приступит к производству Radeon RX 6900 XT, в которой используется полная версия Navi 21 (без отключенных CU), и которая ничуть не слабее, чем GeForce RTX 3090, а то и лучше. Однако, и у GA102 не весь потенциал активирован, поэтому и Nvidia всегда может обновить эту модель до полной «Super» версии, как они это сделали с Turing в прошлом году.
Можно смело утверждать, что, поскольку RDNA 2 используется в Xbox Series X/S и PlayStation 5, разработчики игр будут отдавать предпочтение этой архитектуре для своих игровых движков. Но достаточно вспомнить то время, когда GCN использовался в Xbox One и PlayStation 4, чтобы примерно представить, как это, вероятно, может выглядеть.
Первый релиз Xbox One в 2013 году был оснащён GPU на архитектуре GCN 1.0 – настольные компьютеры познакомились с ней лишь спустя год. А Xbox One X, выпущенный в 2017 году, использовал GCN 2.0, которой к тому времени было уже более 3 лет.

Значит ли это, что все игры, созданные для Xbox One или PS4 и портированные затем на ПК, автоматически лучше работали на видеокартах AMD? Нет, не значит. Поэтому трудно с уверенностью сказать, как сложится дальнейшая судьба RDNA 2 на этом поприще, несмотря на впечатляющий набор функций.
Но все это в конечном итоге не имеет значения, поскольку оба GPU обладают исключительными возможностями и представляют собой чудо полупроводниковых технологий. Nvidia и AMD предлагают разные инструменты, потому что они пытаются решать разные задачи. Ampere стремится угодить всем и каждому, а RDNA 2 – обожает геймеров.
На этот раз исход битвы совершенно не очевиден, хотя каждый может претендовать на победу в какой-то одной определенной категории, или в двух. В 2021 году мы станем свидетелями продолжения войны GPU, в которую вступит ещё и третий участник: это Intel со своей серией чипов Xe. По крайней мере, долго ждать нам этого зрелища уж точно не придётся!
По материалам techspot.com