Как разрабатываются и создаются процессоры? Часть 4: Будущее компьютерных архитектур и разработок.
Несмотря на постоянные улучшения и стабильный прогресс с каждым новым поколением, каких-то фундаментальных сдвигов в индустрии процессоров не происходит уже давно. Переход от ламп к транзисторам был огромным шагом вперёд, также как переход от отдельных компонентов на интегральные схемы. Однако после этого ничего столь же революционного и масштабного не происходило.
Да, транзисторы стали меньше, чипы стали быстрее, а их производительность выросла в сотни раз, но мы начинаем наблюдать застой...
Это четвертая и последняя статья в нашей серии, посвященной разработке и изготовлению процессоров. Начав с высокоуровневого кода, мы узнали, как он компилируется в язык ассемблера и далее – в бинарные инструкции, с которыми работает процессор. Мы заглянули в архитектуру процессоров и поняли, как они обрабатывают инструкции. Затем мы внимательно рассмотрели различные отдельные составляющие процессора.
Мы увидели, как создаются все эти структуры, как обеспечивается согласованная работа миллиардов транзисторов и как из необработанного кремния физически производятся процессоры. Мы узнали об основных свойствах полупроводников и о том, как на самом деле выглядят внутренности чипа.
Перейдём к четвёртой части. Поскольку компании-производители не разглашают результаты исследований и подробности своих актуальных технологий, трудно с уверенностью сказать, что именно находится внутри вашего процессора. Однако мы можем проанализировать современные открытые исследования и понять, в каком направлении движется отрасль.
Одним из самых известных способов представления индустрии производства процессоров – это закон Мура, который гласит, что количество транзисторов в чипе удваивается примерно каждые полтора года. Долгое время этот закон оправдывал себя, но в последнее время рост стал замедляться. Транзисторы становятся настолько маленькими, что мы приближаемся к физическому пределу уменьшения размеров. Если не появится какой-либо прорывной технологии, нам придётся в будущем искать какие-то другие способы повышения производительности.
Закон Мура на протяжении последних 120 лет.
Этот график становится ещё интереснее, если обратить внимание на последние 7 точек – они относятся к GPU компании Nvidia, а не к процессорам общего назначения. Сверху: технологические периоды (механические устройства, реле, лампы, транзисторы, интегральные схемы); слева: стоимость вычислений в секунду (в "постоянных долларах"); снизу: годы. Иллюстрация Стива Джарветсона (Steve Jurvetson).
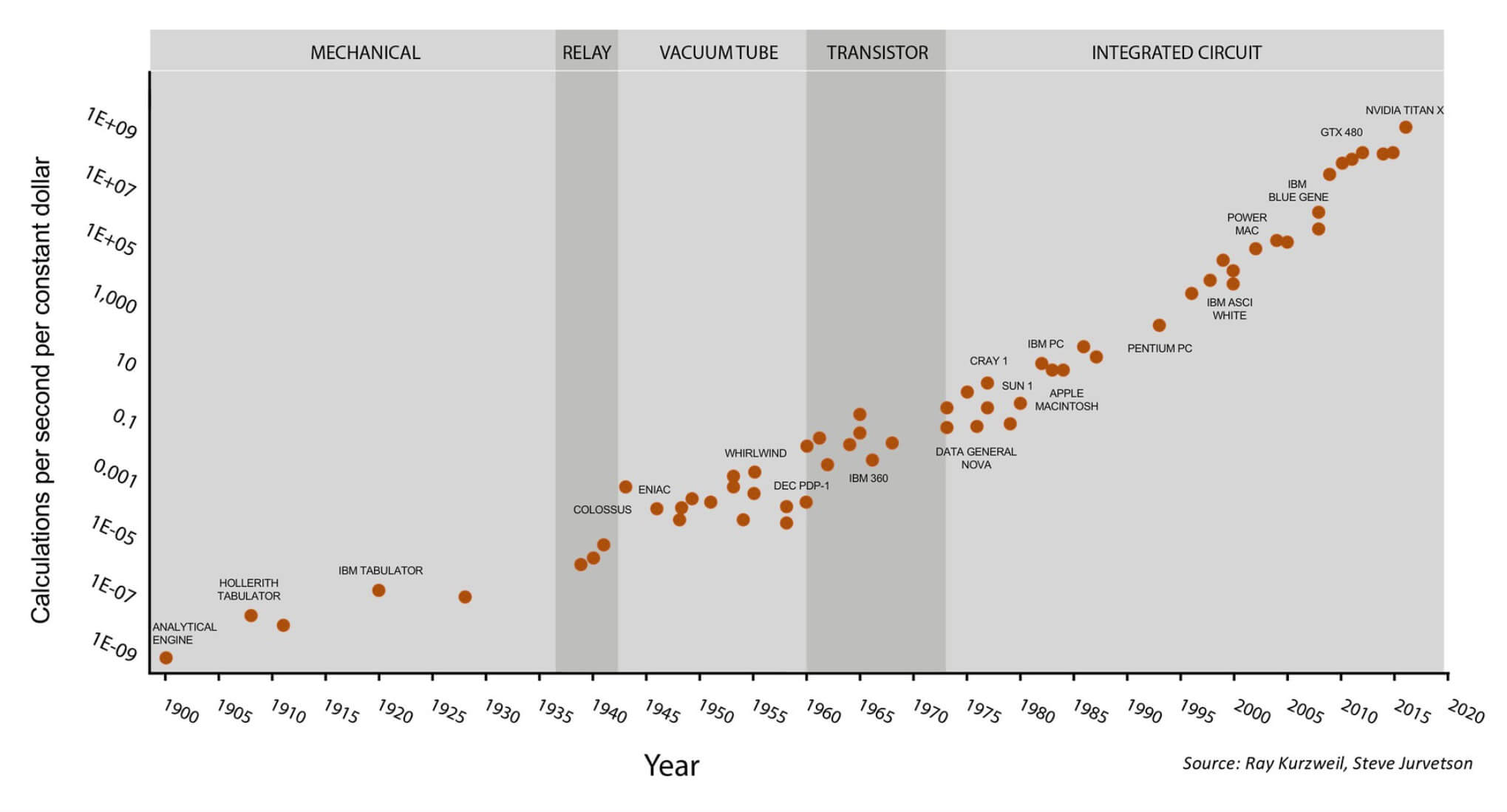
Одним из следствий этого анализа является то, что теперь компании для повышения производительности увеличивают не тактовую частоту, а количество ядер. Именно поэтому мы наблюдаем картину, когда вместо 2-ядерных процессоров с частотой 10 ГГц рынок заполняют 8-ядерные процессоры. Видимо, пространство для роста ограничено только лишь добавлением большего количества ядер.
В то же время, очень многообещающе выглядит область квантовых вычислений. Я в этом не специалист, да почти и нет пока настоящих специалистов в этой области, поскольку технология лишь в процессе создания. Чтобы развеять мифы, скажу, что квантовые компьютеры не дадут вам 1000 кадров в секунду при рендеринге в реальном времени, например. Главное преимущество квантовых компьютеров на данный момент состоит в том, что они используют другие, более продвинутые и ранее недостижимые алгоритмы.

Один из прототипов квантового компьютера IBM.
В обычном компьютере транзистор либо включен, либо выключен, что соответствует 1 и 0. В квантовом компьютере возможна суперпозиция, когда бит может быть одновременно 0 и 1. Благодаря этой появившейся возможности ученые-кибернетики разрабатывают новые методы вычислений и могут решать задачи, неразрешимые с помощью существующих вычислительных мощностей. И дело не в том, что квантовые компьютеры быстрее, а в том, что они представляют собой принципиально новую модель вычислений, способную решать множество новых задач.
До массового внедрения этой технологии ещё 10-20 лет, так какие же тенденции наблюдаются сегодня в индустрии процессоров? Активно ведутся десятки исследований в разных областях, но я коснусь лишь нескольких, самых, на мой взгляд, значительных.
Растёт тенденция влияния гетерогенных вычислений. Это метод включения нескольких различных вычислительных элементов в одну систему. Большинству из нас знаком этот метод на примере отдельного GPU в компьютере. Центральный процессор очень гибок в настройке и может выполнять широкий спектр вычислений с адекватной скоростью. С другой стороны, GPU разработан специально для выполнения графических вычислений, таких как матричное перемножение. С подобными типами инструкции они справляются на порядки быстрее центрального процессора. Переложив некоторую часть нагрузки графическими вычислениями с CPU на GPU, мы можем ускорить выполнение расчетов. Любой программист легко оптимизирует своё ПО, нужным образом изменив алгоритм, а вот оптимизировать оборудование гораздо сложнее.
Но GPU – не единственная область, где применение акселерации становится обычным явлением. Большинство смартфонов имеют десятки аппаратных акселераторов, предназначенных для ускорения выполнения весьма специфических задач. Такой подход к вычислениям известен как «Море ускорителей» (Sea of Accelerators), и к примерам его применения можно привести криптографические процессоры, процессоры изображений, ускорители машинного обучения, кодеры/декодеры видео, биометрические процессоры и многое другое.
По мере того, как нагрузки становятся все более специализированными, разработчики оборудования включают в свои чипы все больше акселераторов. Провайдеры облачных сервисов, такие как AWS, начали предоставлять разработчикам карты FPGA для ускорения их вычислений в облаке. В отличие от обычных вычислительных элементов, таких как ЦП и GPU, имеющих жёсткую внутреннюю архитектуру, архитектура FPGA гибкая. Это практически программируемое оборудование, которое можно настроить в соответствии с нуждами пользователя.
Если требуется выполнять распознавание изображений, можно реализовать эти алгоритмы аппаратно. А чтобы сперва протестировать новое оборудование с помощью симуляции, прежде чем его фактически изготовлять, можно использовать FPGA. FPGA обеспечивает бо́льшую производительность и энергоэффективность, чем графические процессоры, но все же меньше, чем ASIC (application-specific integrated circuit, «интегральная схема специального назначения»). Другие компании, такие как Google и Nvidia, разрабатывают ASIC машинного обучения для ускорения распознавания и анализа изображений.

Снимки кристаллов популярных мобильных процессоров, демонстрирующие их структуру. Фотографии предоставлены пользователем mostlikelynotarobot на портале reddit.com
Взглянув на снимки кристаллов относительно современных процессоров, мы видим, что бо́льшую часть площади ЦП на самом деле занимает не само ядро. Всё бо́льшую долю занимают разного рода ускорители. Это позволило ускорить выполнение очень специализированных вычислений, а также значительно снизить энергопотребление.
Раньше при необходимости добавления в систему обработки видео, разработчики просто добавляли в систему новый чип. Однако это крайне неэффективный подход. Каждый раз, когда сигналу нужно пройти по физическому проводнику от одного чипа к другому, требуется огромное количество энергии на бит. Сама по себе крошечная доля джоуля не кажется особо значительной, но при передаче данных внутри, а не снаружи чипа, она используется на 3-4 порядка эффективнее. Благодаря интеграции таких акселераторов с ЦП, мы наблюдали рост количества чипов со сверхнизким энергопотреблением.
И всё же ускорители не идеальны. Чем больше мы добавляем их в схемы, тем менее гибким становится чип, и мы начинаем жертвовать общей производительностью ради пиковой производительности специализированных видов вычислений. На каком-то этапе весь чип просто превращается в набор акселераторов и перестаёт быть ЦП как таковым. Баланс между производительностью специализированных вычислений и общей производительностью всегда очень тщательно настраивается. Это разногласие между оборудованием общего назначения и специализированными нагрузками называется разрывом специализации (specialization gap).
Если некоторым кажется, что возможности GPU/Machine Learning уже достигли своего апогея, мы можем ожидать, что всё больший объём вычислений будет передаваться специализированным ускорителям. Облачные вычисления и ИИ продолжают развиваться, поэтому GPU выглядят лучшим решением для достижения требуемого уровня объёма вычислений.
Другой областью, где разработчики ищут способы повышения производительности, является память. Традиционно, чтение и запись значений всегда были одним из самых серьёзных «узких мест» для процессоров. Нам могут помочь быстрые и большие кэши, но считывание из ОЗУ или с SSD может занимать десятки тысяч тактовых циклов. Поэтому инженеры часто рассматривают доступ к памяти как более затратный, чем сами вычисления. Если процессор хочет сложить два числа, то ему сначала нужно вычислить адреса памяти, по которым хранятся числа, выяснить, на каком уровне иерархии памяти есть эти данные, считать данные в регистры, выполнить вычисления, вычислить адрес приёмника и записать значение в нужное место. Для простых инструкций, выполнение которых может занимать один-два цикла, это чрезвычайно неэффективно.
Новаторская идея, которую сейчас активно исследуют — это метод под названием Near-Memory Computing (NMC, “околопамятные вычисления”). Вместо того, чтобы извлекать небольшие фрагменты данных из памяти и вычислять их быстрым процессором, исследователи делают наоборот. Они экспериментируют с созданием небольших процессоров непосредственно в контроллерах памяти ОЗУ или SSD. Разместив вычисления ближе к памяти, мы можем получить огромную экономию энергии и времени, ведь теперь нет нужды гонять данные столь много и долго. Вычислительные модули имеют прямой доступ к нужным им данным, поскольку находятся непосредственно в памяти. Эта идея всё ещё находится в зачаточном состоянии, но результаты выглядят многообещающе.
Одно из препятствий, стоящих на пути реализации near-memory computing — это ограничения, накладываемые процессом изготовления чипа. Как говорилось в третьей части, процесс кремниевого производства очень сложен и состоит из десятков этапов. Эти процессы обычно специализированы для изготовления либо быстрых логических элементов, либо элементов памяти. Если попытаться создать чип памяти с помощью процесса, оптимизированного для вычислительных элементов, то получится чип с чрезвычайно низкой плотностью элементов. Если же попробовать создать процессор с помощью процесса, предназначенного для модулей памяти, то получим очень низкую производительность и большие тайминги.
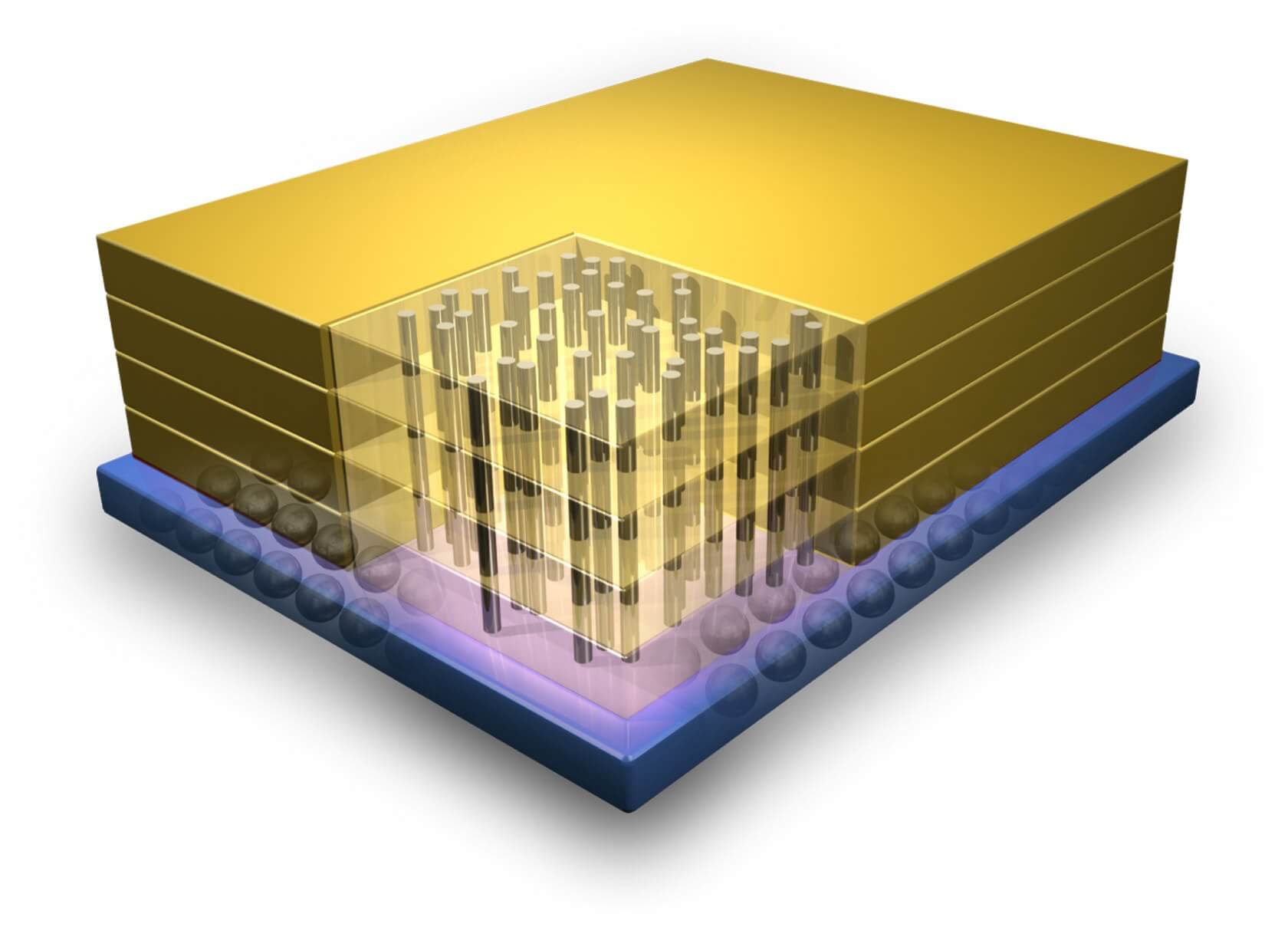
Пример 3D-интеграции, демонстрирующий вертикальные соединения между слоями транзисторов.
Одним из возможных решений этой проблемы является трёхмерная интеграция (3D Integration). Традиционные процессоры обладают одним очень широким слоем транзисторов, и это имеет свои ограничения. Как видно из названия, 3D-интеграция — это процесс расположения нескольких слоёв транзисторов друг над другом для повышения плотности и снижения задержек. Вертикальные проводники, производимые на разных процессах изготовления, используются для соединений между слоями. Эта идея была предложена уже давно, но индустрия отказалась от неё из-за серьёзных сложностей в её реализации. В последнее время мы наблюдаем возникновение технологии накопителей 3D NAND и возрождение этой области исследований.
Наряду с физическими и архитектурными изменениями, на всю индустрию полупроводников сильно повлияет тенденция усиления внимания к безопасности. До недавнего времени о безопасности процессоров думали чуть ли не в последнюю очередь. Это как если бы Интернет, электронная почта и многие другие системы, которые мы сегодня активно используем, разрабатывались почти без учёта безопасности. Все существующие меры защиты «прикручивались» по мере случавшихся инцидентов, чтобы мы чувствовали себя защищёнными. Касательно процессоров, подобная практика больно ударила по производителям, и особенно по Intel.
Уязвимости Spectre и Meltdown — это, вероятно, самые известные примеры того, как проектировщики добавляют функции, значительно ускоряющие процессор, не в полной мере осознавая связанные с этим угрозы. При разработке же современных процессоров гораздо большее внимание уделяется безопасности как ключевой части архитектуры. При её повышении часто страдает производительность, но учитывая ущерб, который компании могут понести из-за появления серьёзных уязвимостей, очевидно, что безопасностью пренебрегать не стоит в той же мере, как производительностью.
В предыдущих частях нашей серии мы коснулись таких техник, как высокоуровневый синтез, позволяющий проектировщикам сначала описать структуру на языке высокого уровня, а затем позволить сложным алгоритмам определить оптимальную для выполнения функции аппаратную конфигурацию. С каждым поколением этапы проектирования становятся всё более дорогостоящими, поэтому инженеры ищут способы ускорения разработки. Следует ожидать, что в дальнейшем и эта тенденция проектирования оборудования при помощи ПО будет только усиливаться.
Будущее предсказать невозможно, но рассмотренные нами в статье инновационные идеи и области исследований могут служить своего рода дорожной картой наших ожиданий в сфере проектирования процессоров будущего. Что с уверенностью можно сказать, так это то, что мы близимся к концу типичных усовершенствований процесса производства. Чтобы и дальше продолжать увеличивать производительность в каждом поколении, разработчикам придётся искать ещё более сложные решения.
Надеемся, что наша серия из четырёх статей пробудила ваш интерес к тому, как проектируются и производятся процессоры, как контролируется их качество и многому другому. Существует бесконечное количество материалов по этой теме, и если бы мы попытались раскрыть их все, то каждая из статей заняла бы целый университетский курс. Хочется надеяться, вы узнали для себя что-то новое и теперь лучше понимаете, насколько сложны компьютеры на каждом из уровней. Если у вас есть предложения, какую тему нам стоит рассмотреть поглубже, мы всегда готовы выслушать их.
Также рекомендуем к прочтению:
- Часть 1: Фундаментальные основы архитектуры процессоров;
- Часть 2: Процесс проектирования процессора
- Часть 3: Изготовление чипа