Apple работает над возможностью хранения больших языковых моделей в NAND, а не DRAM
Практически все полупроводниковые компании акцентируют внимание на решениях для искусственного интеллекта, будь то новое оборудование для обучения или новое программное обеспечение. Apple тоже не собирается проходить мимо столь прибыльного рынка, внедряя в свои процессоры специализированные нейронные движки, а также разрабатывая новые решения для работы ИИ.

Сейчас для работы с большими языковыми моделями (LLM) необходимо загружать их параметры в оперативную память (DRAM), из-за чего ускорителям требуется большое количество памяти, значительно влияющей на итоговый ценник, особенно это касается моделей, работающих со стеками HBM. Apple собирается изменить это, позволяя размещать LLM в микросхемах памяти NAND, а не DRAM, то есть сохраняя модели на твердотельном накопителе, а не в памяти ускорителей.
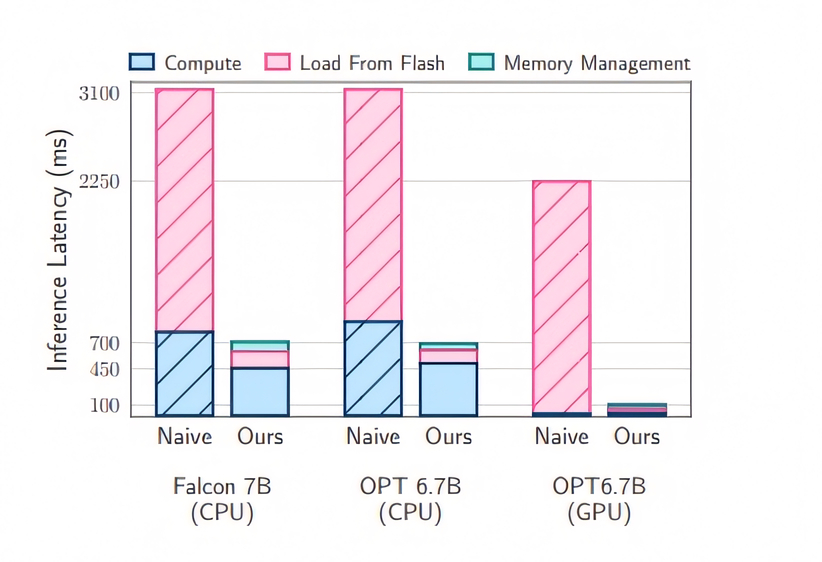
Новые методы работы с ИИ известны как Windowing и Row-column bundling: первый сокращает количество требуемых операций ввода-вывода за счет переиспользования загруженных в DRAM параметров, а второй, в свою очередь, позволяет читать отдельные части данных с чипов памяти. Совокупность этих методов не только позволяет работать с ИИ при наличии меньшего количества DRAM, но и ускоряет вывод до пяти раз по сравнению с традиционным подходом, задействующим только DRAM.