

NVIDIA удалось вдвое повысить производительность H100 за счет применения TensorRT-LLM

NVIDIA не собирается никому отдавать лидерство в сегменте искусственного интеллекта, постоянно предлагая как новые ускорители, или модернизированные версии существующих, так и работая над программной оболочкой, предлагающей дополнительные оптимизации и прирост производительности.
Компания заявила о разработке программного обеспечения с открытым исходным кодом TensorRT-LLM, предназначенного для повышения производительности при работе с большими языковыми моделями, такими как GPT-J. Оно работает за счет инновационной технологии пакетной обработки данных на лету, оптимизируя планирование динамических и разнообразных рабочих нагрузок, максимально задействуя возможности графического процессора.
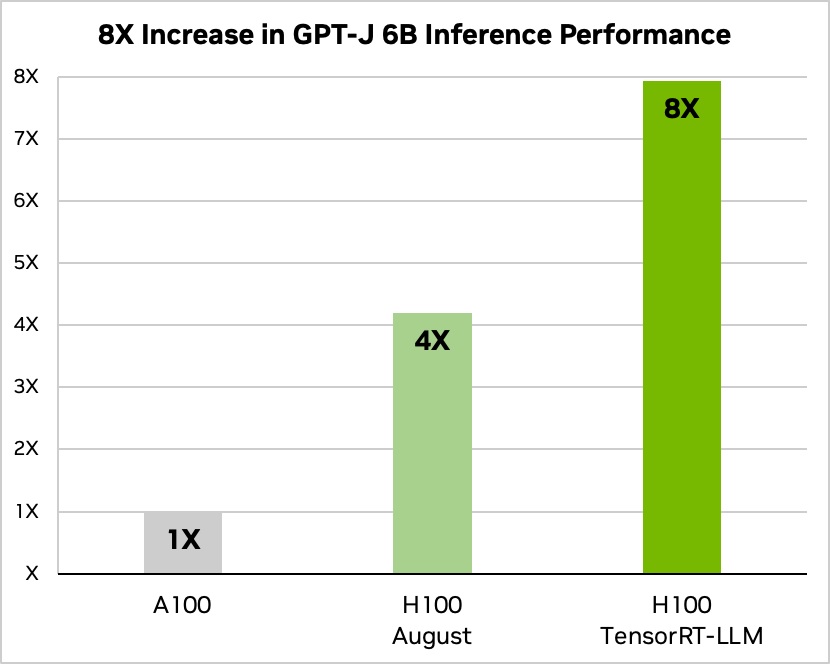
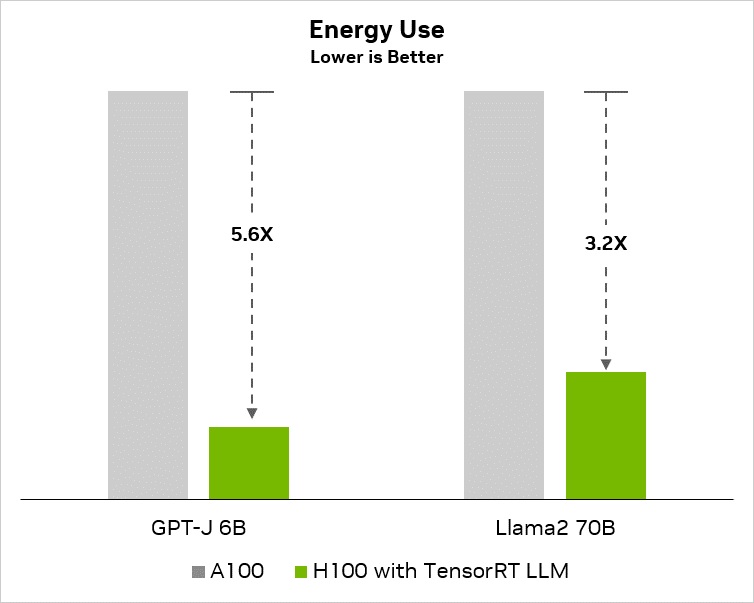
Внутренние тесты TensorRT-LLM показали 2-кратный прирост производительности ускорителя H100, а также 8-кратный прирост по сравнению с ускорителем прошлого поколения A100. Этот прирост применим к рабочей нагрузке GPT-J с применением 6 миллиардов параметров. Помимо этого, отмечается существенное улучшение энергосбережения.
«TensorRT-LLM прост в использовании, обладает множеством функций, включая потоковую передачу токенов, пакетную обработку в реальном времени, страничное внимание, квантование и многое другое. Он обеспечивает высокую производительность для LLM с использованием графических процессоров NVIDIA и позволяет нам экономить средства для наших клиентов», – Навин Рао (Naveen Rao), вице-президент по разработкам в Databricks.