
NVIDIA представила графический процессор GH100 и ускоритель на его основе
На конференции GTC 2022 NVIDIA официально представила графический процессор GH100 на основе микроархитектуры Hopper. Он изготавливается по технологическому процессу TSMC N4, насчитывает 80 миллиардов транзисторов, поддерживает интерфейс PCI Express 5.0 и оснащается стеками памяти HBM3.

Технические характеристики NVIDIA GH100 подсказывают, что он может похвастаться 144 потоковыми мультипроцессорами и 18432 CUDA-ядрами, 576 тензорными ядрами четвертого поколения, шестью стеками памяти HBM3 с пропускной способностью 3 Тбайта/с, двенадцатью 512-битными контроллерами памяти, 60 Мбайт L2 кэша и наличием NVLink четвертого поколения.

NVIDIA GH100 обзавелся движком Transformer Engine, подразумевающим поддержку инструкций DPX, предназначенных для ускорения динамического программирования, применяемого в алгоритмах для геномики, квантовых вычислений, оптимизации маршрутов и прочих задач. Компания заявляет о 7-кратном увеличении производительности в подобного рода задачах с использованием DPX по сравнению с графическими процессорами прошлого поколения.
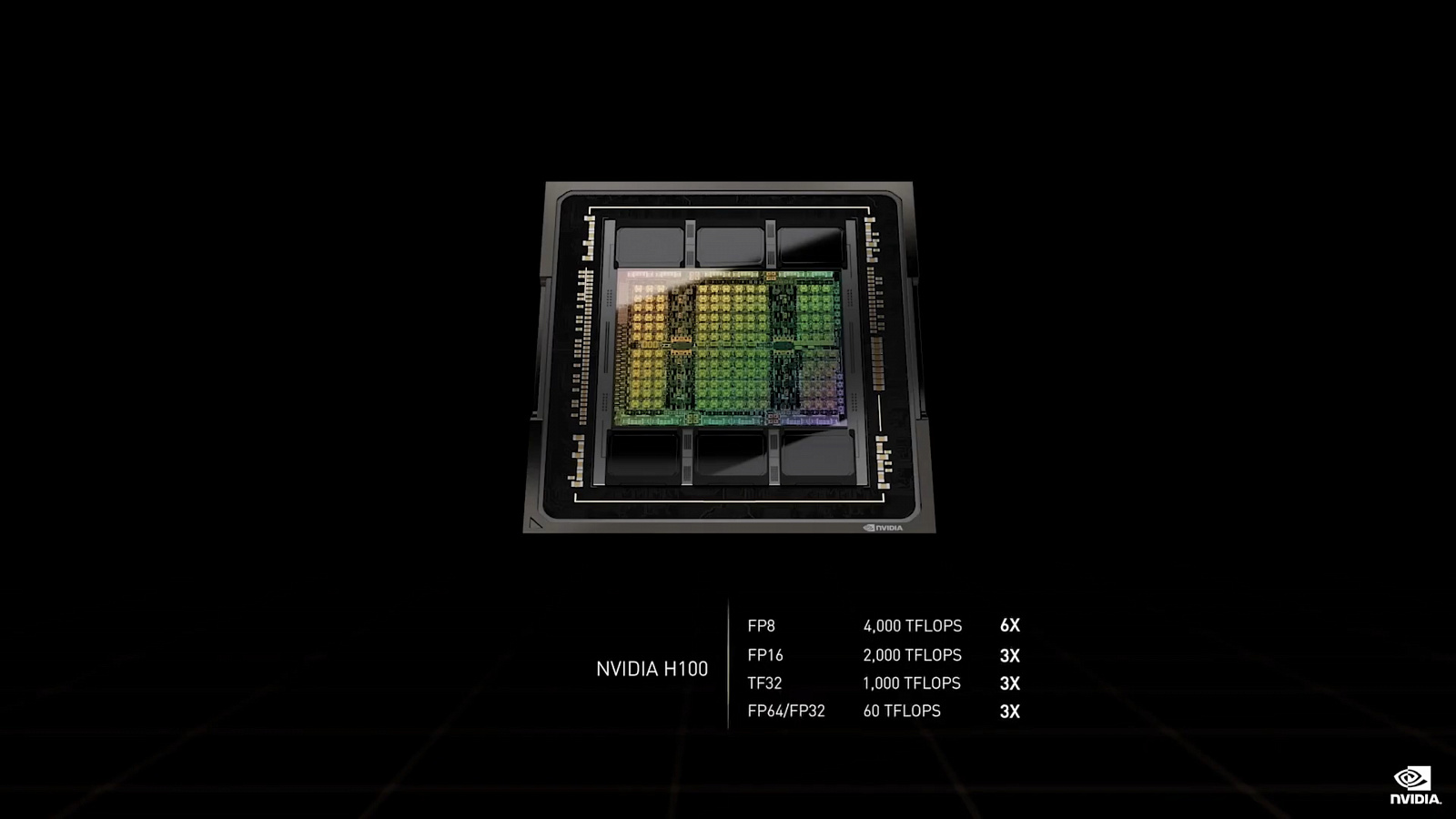
NVIDIA заявляет, что производительность GH100 составляет 4000 TFLOPS в операциях FP8, 2000 TFLOPS в операциях FP16, 1000 TFLOPS в операциях TF32 и 60 TFLOPS в операциях FP32/64.

Графический процессор GH100 лег в основу ускорителя NVIDIA H100 в форм-факторе SXM. Его характеристики несколько урезаны по сравнению с полноценной версией процессора. Так, в составе NVIDIA H100 расположился GH100 с 128 потоковыми мультипроцессорами, 16896 CUDA-ядрами, 528 тензорными ядрами, 50 Мбайтами L2 кэша и поддерживает только пять стеков памяти HBM3 объемом 80 Гбайт, теплопакет 700 Вт. Также будет выпущен ускоритель NVIDIA H100 в форм-факторе PCI Express. Он получит 14592 CUDA-ядра, 456 тензорных ядер и теплопакет 350 ВТ. Остальные характеристики идентичны.


На основе ускорителя NVIDIA H100 будет создано четвертое поколение систем DGX H100, производительность которых будет достигать 32 PFLOPS в операциях FP8. Их можно объединять в сети из 32 таких систем, образуя суперкомпьютеры NVIDIA DGX POD и SuperPOD нового поколения. Также компания работает над суперкомпьютером Eos – самым быстрым суперкомпьютером для работы с искусственным интеллектом в мире. Он получит 576 систем DGX H100 с производительностью 18 EFLOPS в операциях FP8, 9 EFLOPS в операциях PP16 и 275 PFLOPS в операциях FP64.