
4 года RDNA от AMD: еще один Zen или новый Bulldozer?
В 2019 году AMD представила новую архитектуру GPU, что стало первым крупным проектом графического чипа за семь лет. С момента своего дебюта эта архитектура претерпела две редакции, подчеркивающие важность чиплетов и кэша на арене рендеринга. Учитывая эти разработки, уместно оценить, чего AMD достигла благодаря своему инженерному мастерству, и рассмотреть влияние каждого обновления.
В статье будут освещены представленная технология, обзор ее производительности в играх и финансовые последствия для AMD.
Стала ли RDNA таким же монументальным успехом, как Zen? Или различные модификации привели к еще одному «бульдозерному» моменту для AMD? Давайте выясним.

Почему GCN нуждалась в изменении
Нынешние GPU от AMD попадают в один из двух совершенно разных секторов продуктов: те, которые предназначены для игр, и те, которые в итоге используются в суперкомпьютерах, анализаторах больших данных и системах машинного обучения.
Однако все они имеют одно и то же наследие — архитектуру, известную как Graphics Core Next (GCN). Впервые она появилась в 2012 году и использовалась почти 10 лет, хотя и с некоторыми серьезными изменениями. GCN представляла собой тщательную переработку своей предшественницы TeraScale, и с самого начала она была разработана с учетом высокой масштабируемости и одинакового использования в графических и вычислительных приложениях общего назначения (GPGPU).
Масштабируемость возникла из-за того, что процессорные блоки были сгруппированы вместе. С самой первой версии GCN до её окончательной версии основа GPU состояла из четырех вычислительных блоков (CU).
Каждый из них содержал 4 векторных блока SIMD (одна инструкция, несколько данных), которые выполняли математические операции с 16 точками данных размером 32 бита, и один скалярный блок, который использовался для логических операций на основе целых чисел.
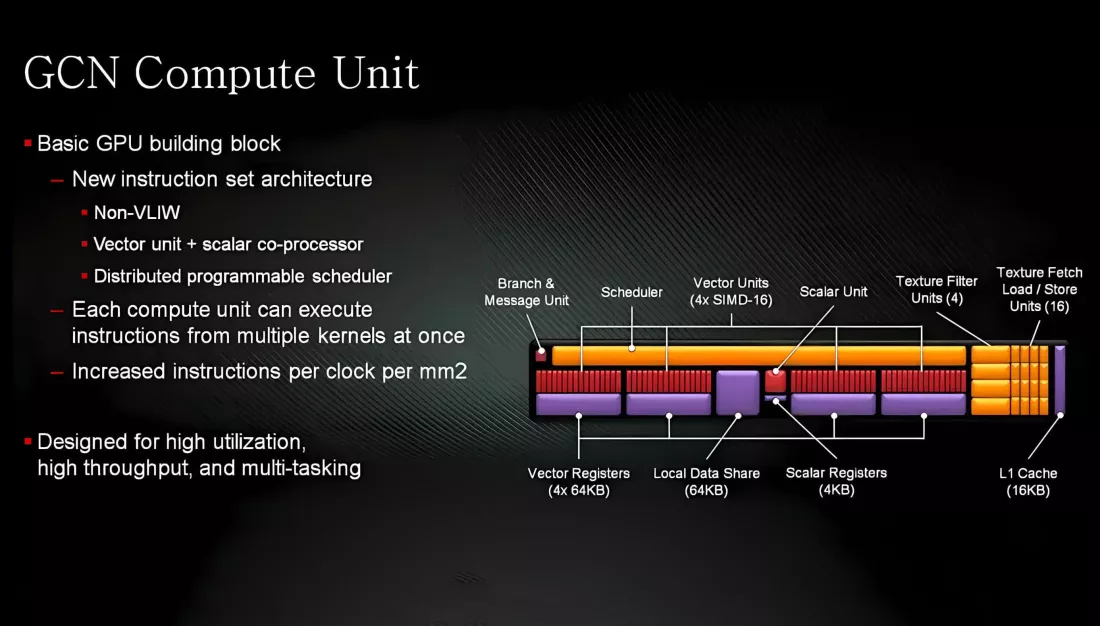
Каждый векторный SIMD имел регистровый файл размером 64 КБ, и все четыре устройства использовали общий блок оперативной памяти объёмом 64 КБ (так называемое Local Data Share – локальное распределение данных, LDS), а все процессорные блоки применяли общий кэш данных L1 объемом 16 КБ. Четырехъядерная группа CU имела общий скалярный кэш объемом 16 КБ и кэш инструкций объемом 32 КБ, при этом все эти кэши были связаны с кэшем L2 всего GPU.
К моменту выхода GCN 5.1 в 2018 году ничего из этого существенно не изменилось, хотя в работе иерархии кэша было внесено множество улучшений. Однако в мире игр у GCN были некоторые заметные недостатки: разработчикам было непросто добиться максимальной производительности чипов с точки зрения пропускной способности и использования полосы пропускания.
Например, потоки отправлялись GPU группами по 64 (каждая из них называлась волной или волновым фронтом) и каждому блоку SIMD могла быть выдана отдельная волна, поставленная в очередь глубиной до 10. Тем не менее, частота выдачи инструкций составляла 1 каждые 4 цикла, поэтому для обеспечения занятости устройств необходимо было отправлять множество потоков – более чем достижимо в вычислениях и тем более в играх.
Первая версия GCN имела аппаратные структуры под названием асинхронные вычислительные машины (ACE). Когда дело доходит до рендеринга кадра в 3D-игре, GPU получает от системы команды, которые выстраиваются в длинную очередь. Однако не обязательно все их выполнять в строго линейной последовательности, и именно здесь в игру вступают ACE.
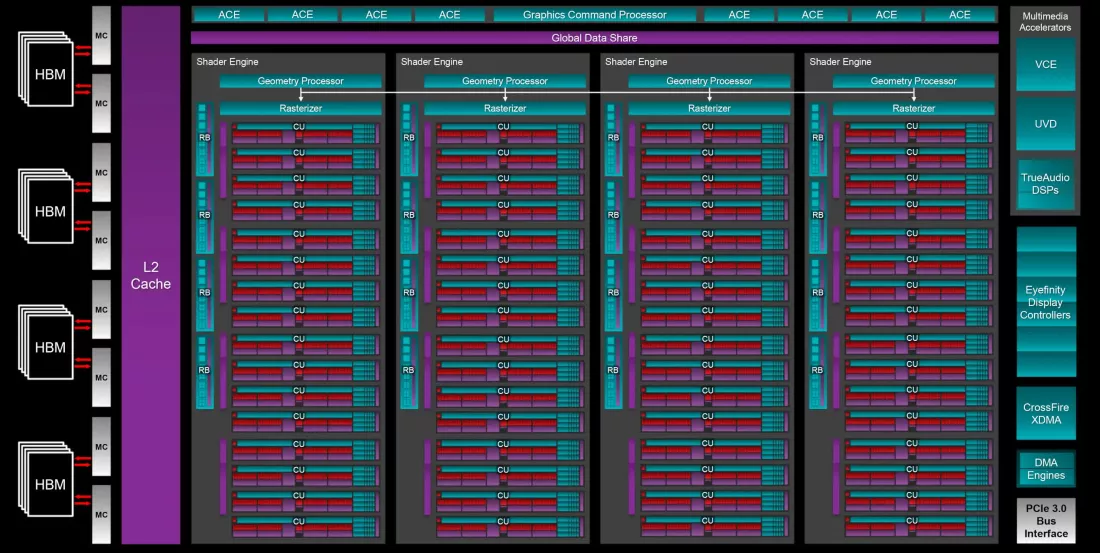
GPU на базе GCN могут по сути разделить очередь на три разных типа (по одному для графических команд, вычислительных операций и транзакций данных), а затем соответствующим образом планировать их. Однако в то время API Direct3D не имел особой поддержки этой системы, хотя после выхода Direct3D 12 в 2015 году асинхронное затенение стало в моде. AMD извлекла из этого выгоду, сделав GCN еще более сосредоточенной на вычислениях.
Это стало совершенно очевидно, когда AMD представила GCN на рынке высококлассных игровых видеокарт — Radeon VII за 700 долларов (ниже). Имея 60 CU (в полном чипе их было 64) и 16 ГБ памяти HBM2 на шине шириной 4096 бит, это был абсолютный GPU-монстр.
По сравнению с GeForce RTX 2080, которая также продавалась по цене 700 долларов, она могла быть быстрее в некоторых играх, но большинство результатов тестов показали, что архитектура просто не идеально подходит для современных 3D-игр.

GCN 5.1 в основном использовалась в профессиональных картах для рабочих станций, а Radeon VII была по сути ни чем иным, как временным продуктом, созданным для того, чтобы иметь что-то на полках для игровых энтузиастов, пока следующее поколение GPU готовилось к появлению.
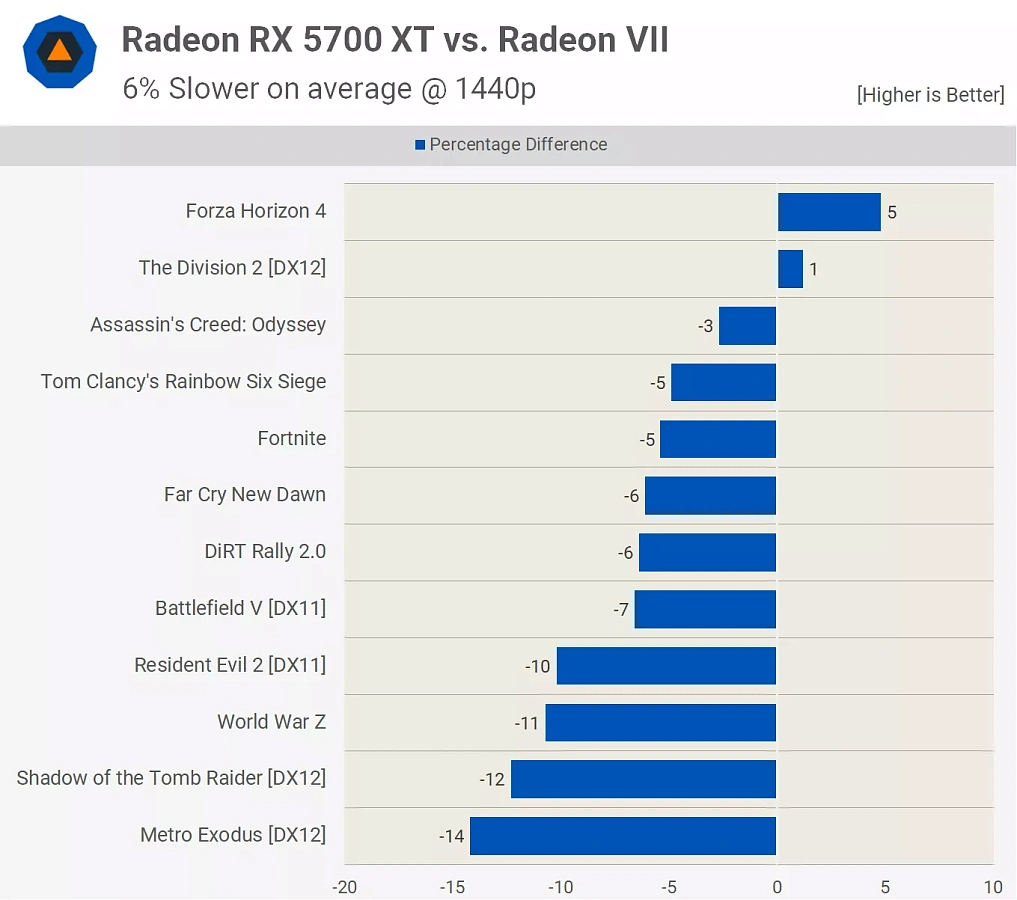
Всего четыре месяца спустя AMD выпустила преемника давно существующей архитектуры GPU — RDNA. Благодаря этому новому дизайну AMD удалось устранить большинство недостатков GCN, и первая видеокарта с данной архитектурой, Radeon RX 5700 XT, ясно показала, насколько больше она настроена на игры, чем GCN.
Один маленький шаг для GPU
Когда в 2017 году вышла серия Ryzen CPU с новым дизайном Zen, покупатели получили совершенно новую архитектуру, воссозданную с нуля. В случае с RDNA этого не произошло, поскольку фундаментальные концепции по своей природе всё ещё были похожи на GCN. Однако практически всё внутри было изменено, чтобы разработчикам игр было проще добиться максимально возможной производительности GPU.
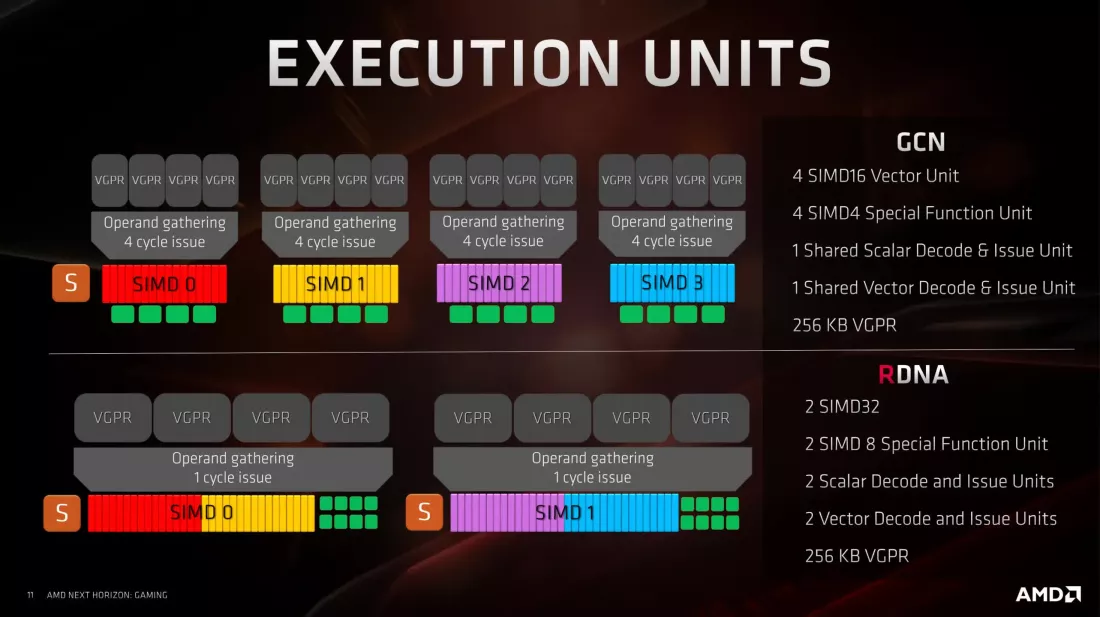
Количество SIMD на каждый CU изменили с 4 на 2, причем любой теперь работает с 32 точками данных, а не с 16. Модуль диспетчеризации теперь может обрабатывать потоки пакетами по 32 или 64, а в первом случае - блоки SIMD теперь может быть задействован и обрабатывать инструкцию один раз за цикл.
Всего лишь эти два изменения значительно облегчили разработчикам загрузку GPU, хотя это и означало, что компилятору нужно было больше работать над выбором правильного размера волны для обработки. AMD выбрала 32 для вычислительных и геометрических шейдеров и 64 для пиксельных шейдеров, хотя это не было чем-то высеченным на камне.
CU теперь группировались парами (так называемые процессоры рабочей группы, WGP), а не квартетами. И хотя кэши инструкций и скалярные кэши по-прежнему были общими, теперь им нужно было обслуживать только два CU. Исходный кэш L1 объемом 16 КБ был изменен и переименован в L0, а новый кэш L1 объемом 128 КБ теперь обслуживал банк из четырех WGP — оба имеют строки кэша размером 128 байт (что помогает улучшить внутреннюю пропускную способность).
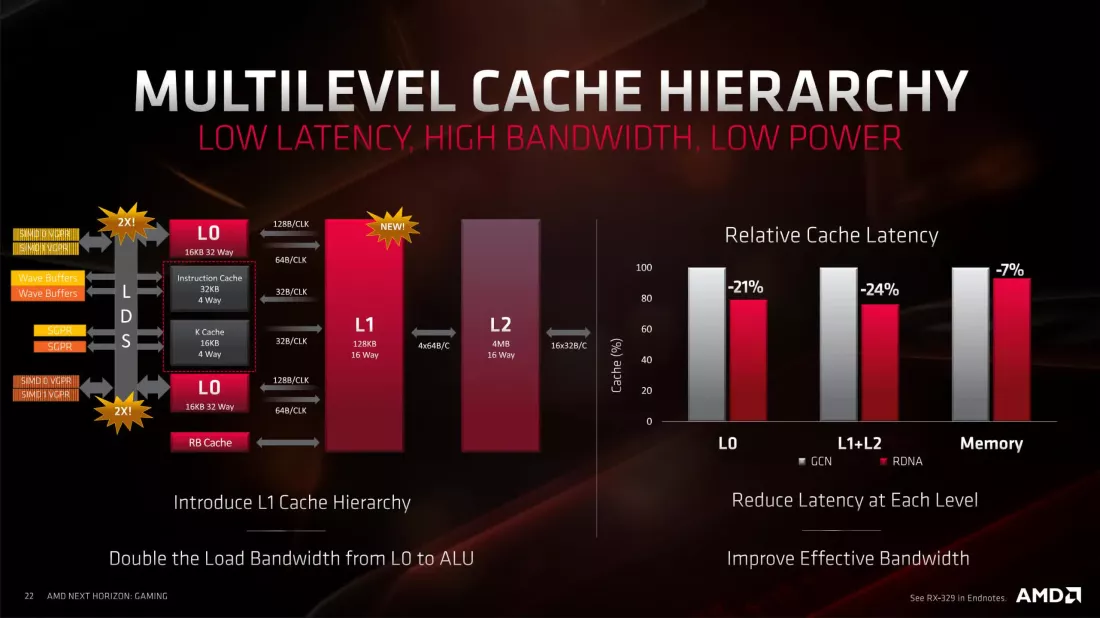
Сжатие данных без потерь теперь использовалось в каждой секции GPU, задержки по всем направлениям были уменьшены и даже были обновлены блоки адресации текстур. Все эти изменения помогли сократить затраты времени на перемещение данных, очистку кэшей и т. д.
Но, пожалуй, самым удивительным аспектом первой версии RDNA были не архитектурные изменения, а тот факт, что первая ее версия была создана для видеокарт среднего класса и средней цены. Чип Navi 10 в Radeon RX 5700 XT не представлял собой огромную пластину кремния, набитую вычислительными блоками, а имел площадь всего 251 мм² и 40 CU внутри. Сделанный на том же узле TSMC N7, что и GPU Vega 20 в Radeon VII, он был на 24% меньше, что отлично сказалось на производительности пластин.
Однако у него также было на 38% меньше CU, хотя нельзя было ожидать, что все дополнительные обновления и кэш будут бесплатными с точки зрения количества транзисторов. Но при тестировании в играх она была в среднем всего на 9% медленнее, чем Radeon VII, и в довершение ко всему, была на 300 долларов дешевле.
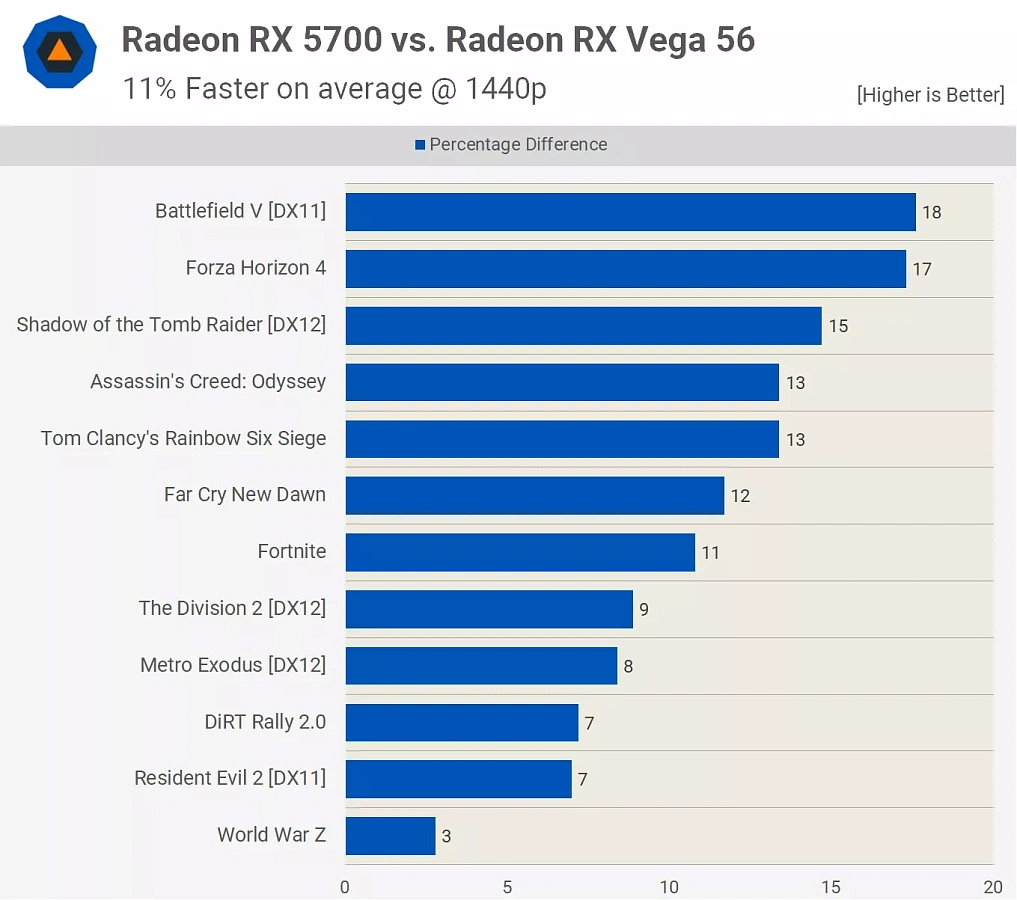
В целом, это был многообещающий вход в новую архитектуру, поскольку RDNA была шагом в правильном направлении, хотя и небольшим. Поскольку его производительность находилась где-то между Radeon RX Vega 56 и Radeon VII, это был хороший баланс между высокой скоростью, энергопотреблением и розничной ценой.
Однако запуск нового GPU не прошел без проблем, и хотя RDNA нашла применение почти в 30 различных продуктах (благодаря трем вариантам конструкции чипа), некоторые люди были разочарованы тем, что у AMD не было в продаже чего-то более мощного.
К счастью, им не пришлось долго ждать решения этого вопроса.
Раунд 2 для RDNA
Спустя чуть больше года после запуска Radeon RX 5700 XT, пока мир боролся с глобальной пандемией, AMD выпустила RDNA 2. По сути почти ничего не изменилось, кроме двух новинок — текстурные блоки были модернизированы так, что могли выполнять тесты пересечения лучей и треугольников, и был добавлен дополнительный последний уровень кэша (LLC).
Первое было экономически эффективным дополнением, которое давало GPU возможность обрабатывать трассировку лучей при минимальном количестве дополнительных транзисторов, но второе не было разрозненным предложением, поскольку его объем был гораздо больше, чем несколько МБ. До этого момента в истории GPU 6 МБ LLC считались «большими», поэтому, когда AMD включила 128 МБ из них в первый чип RDNA 2, Navi 21, это не только ошеломило поклонников GPU, но и изменило ход развития GPU навсегда.

В то время как CPU становились всё быстрее и мощнее благодаря усовершенствованиям в методах изготовления микросхем, DRAM изо всех сил старалась не отставать. Гораздо сложнее уменьшить миллиарды крошечных конденсаторов и не столкнуться с проблемами. К сожалению, чем мощнее GPU, тем больше пропускной способности памяти ему требуется для подачи данных.
Чтобы обойти эту проблему, Nvidia решила использовать технологию Micron GDDR6X и оснастить свой GPU множеством интерфейсов памяти. Однако эта оперативная память была дороже стандартной GDDR6, а дополнительные интерфейсы просто увеличивали размер чипов. Подход AMD заключался в том, чтобы использовать свои ноу-хау в области кэширования, полученные в подразделении CPU, и внедрить массу LLC в свои чипы RDNA 2.
Благодаря этому потребность в широких шинах памяти с быстрой оперативной памятью была значительно снижена, что помогло держать под контролем размеры матрицы GPU и цены на видеокарты. И размер матрицы здесь был важен, поскольку Navi 21, по сути, представляла собой две Navi 10 (всего 80 CU), окруженных стеной кэша.
Последний был построен из 10,3 миллиардов транзисторов, тогда как новый чип содержал более чем вдвое больше — 26,8 миллиардов. Дополнительные 6,2 миллиарда в основном использовались для так называемого Infinity Cache, хотя внутри были и другие изменения. AMD перенастроила и оптимизировала всю архитектуру, в результате чего чипы RDNA 2 смогли работать на значительно более высоких тактовых частотах, чем их предшественники.
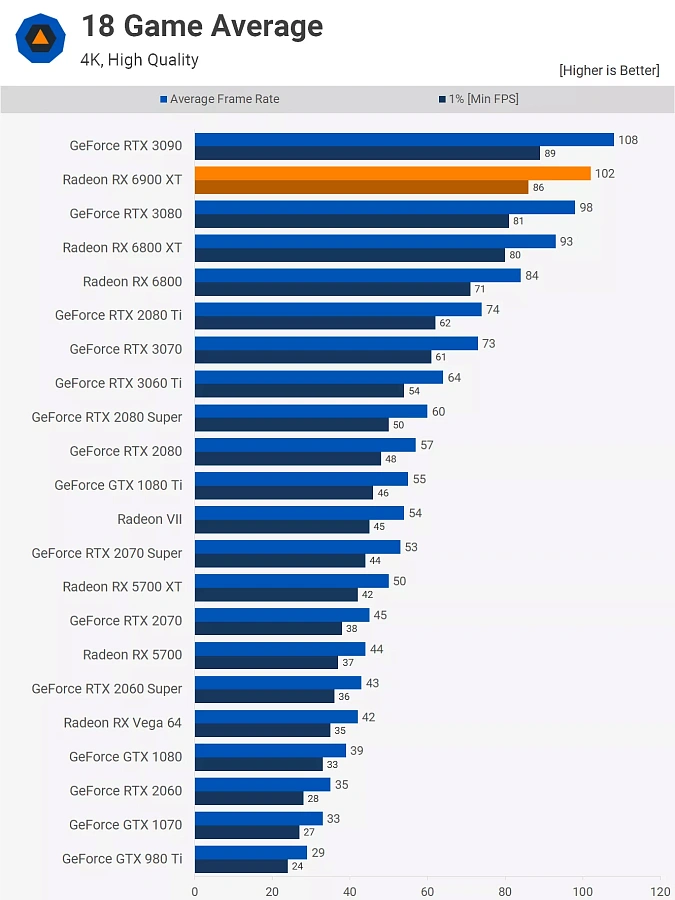
Конечно, всё это не имело бы значения, если бы конечный продукт не был хорошим. Несмотря на ошеломляющую цену в 1000 долларов, Radeon RX 6900 XT предлагала уровень производительности GeForce RTX 3090 за меньшую цену на 500 долларов. Она не всегда была на одном уровне, и в зависимости от используемой игры и разрешения GeForce RTX 3080 за 700 долларов была такой же быстрой.
В этой ценовой категории у AMD были Radeon RX 6800 XT и RX 6800 на 50 и 120 долларов дешевле, чем RTX 3080 соответственно. Разница в производительности между 6800 и RTX 3090 составила почти 30%, но разница в цене составила 63%. Возможно, AMD и не завоевала корону производительности, но нельзя было отрицать, что ее продукты по-прежнему были очень мощными и имели отличное соотношение цены и качества, в то время как цены на GPU были запредельными.
Но в противовес этому была производительность трассировки лучей. Если коротко, то она была далеко не так хороша, какой достигли с Nvidia Ampere, хотя, учитывая, что это было первое погружение AMD в область физически корректного моделирования света, возможности не впечатляли.

Там, где Nvidia решила разработать и реализовать две большие специальные ASIC (интегральные схемы для конкретных приложений) для обработки пересечения луч-треугольника и вычислений обхода BVH (иерархия ограничивающего объема), AMD выбрала более умеренный подход. В нём не будет специального оборудования, а процедуры будут выполняться с помощью вычислительных блоков (CU).
Это решение было основано стремлением сохранить размер матрицы как можно меньшим. Чип Navi 21 был довольно большим — 521 мм², и хотя Nvidia была рада предложить процессоры еще большего размера (GA102 в RTX 3090 составляла 628 мм²), добавление специальных блоков сильно увеличило бы площадь.

В ноябре того же года Microsoft и Sony выпустили свои новые консоли Xbox и PlayStation, оснащенные специальными APU AMD (CPU и GPU в одной матрице), которые использовали RDNA 2 для графической части без Infinity Cache. Учитывая необходимость сделать данные чипы как можно меньшими, стало совершенно ясно, почему AMD выбрала именно этот путь.
Всё дело было в улучшении финансовых показателей графического подразделения.
Деньги и прибыль имеют значение
До второй половины 2021 года AMD публиковала данные о выручке и операционной прибыли всего по двум подразделениям: «Вычисления и графика» и «Корпоративные, Встраиваемые и Полукастомные технологии». Доходы от продаж видеокарт и дискретных графических процессоров в ноутбуках шли в первую группу, тогда как доходы от продажи APU для консолей Xbox и PlayStation - во вторую.
За период с первого квартала 2018 по первый квартал 2021 операционная рентабельность компании была, мягко говоря, нестабильной.
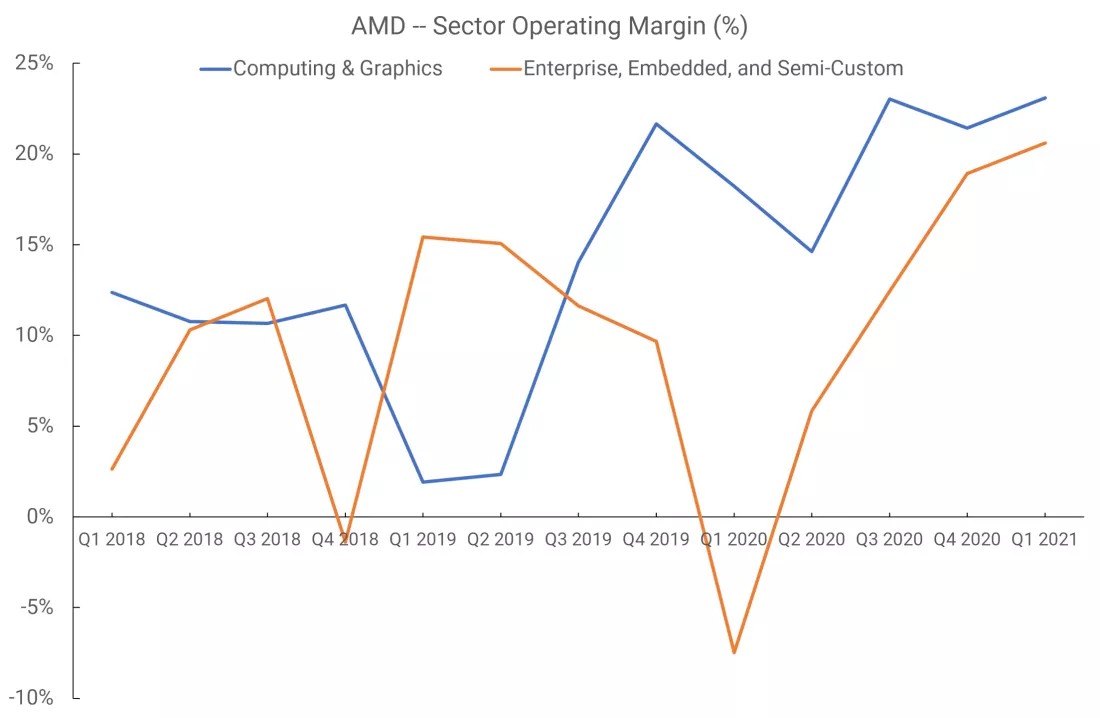
RDNA была запущен во втором квартале 2019 года, но доходы от таких продаж действительно начнут ощущаться только в следующем квартале, поскольку только две модели видеокарт оснащены новым чипом. Нельзя сказать, что росту операционной прибыли способствовала архитектура GPU, поскольку в итоги также включены продажи CPU.
Однако, начиная со второго квартала 2021 года, AMD разделила отчетность на четыре подразделения: «Центры обработки данных», «Клиентские устройства», «Игровые системы» и «Встраиваемые системы». Третье охватывает всё, что связано с GPU, включая APU, которые попадают в консоли.
Показатели графического подразделения AMD оказались самыми низкими из четырех. AMD заявила, что в 2022 финансовом году только один клиент отвечал за шестую часть всей выручки компании, которым, как предполагали другие, была Sony. Если бы это действительно было так, то продажи APU PlayStation 5 составляли более 50% доходов игрового сектора.
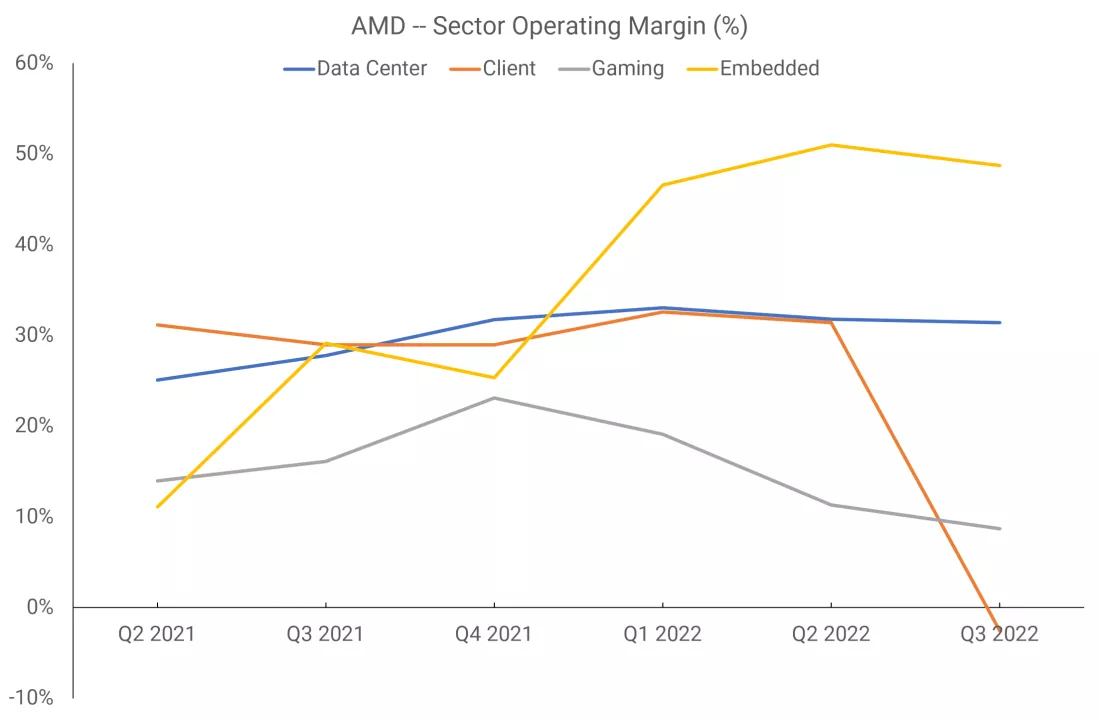
Показатели поставок дискретных видеокарт в том финансовом году резко упали, что не оставляет особых сомнений в том, что операционная прибыль этого подразделения оставалась положительной благодаря продажам консолей. AMD использует TSMC для производства подавляющего большинства, если не всех, своих чипов, но заказы необходимо размещать за несколько месяцев вперед — если процессоры не будут проданы вскоре после изготовления, они должны оставаться в распределительном центре, что снижает прибыль за этот период.
Недостаточно информации, чтобы понять, получает ли AMD прибыль от своих инвестиций в RDNA, как и невозможно отделить инвестиции в Zen от прибыли центров обработки данных и игрового сектора. Но цифры выручки, составившие в среднем 1,6 млрд долларов за вышеуказанные 6 кварталов, привели к тому, что средняя операционная рентабельность составила 15% – только клиентский сектор оказался ниже этой цифры, и это в основном связано со спадом продаж ПК.
Между тем, за тот же период сегмент графики Nvidia (который включает в себя GPU для настольных компьютеров, ноутбуков, рабочих станций, автомобилей и т. д.) в среднем составлял около 3,6 миллиардов долларов в квартал при средней операционной рентабельности 43%. Веселый зеленый гигант занимает большую долю рынка дискретных GPU, чем AMD, поэтому более высокие цифры выручки неудивительны, но операционная маржа в некоторой степени открывает глаза.

Но стоит принять во внимание тот факт, что APU, которые AMD продает Microsoft и Sony, в любом случае не будут иметь большой прибыли, иначе вы не смогли бы купить одну из последних консолей за 400 долларов. Массовое производство микросхем «все-в-одном» полезно для дохода, но в меньшей степени для получения чистой прибыли.
Если исключить предполагаемый доход, который дают консольные чипы, и предположить, что они приносят прибыль в размере 10%, это будет означать, что RDNA генерирует разумную сумму прибыли — операционная маржа может достигать 20%. Не уровень Nvidia, но понятно, почему прибыль этой компании такая высокая.
Чиплеты и вычисления
RDNA 2, безусловно, стала инженерным успехом AMD: этот дизайн нашел применение почти в 50 различных продуктах. Однако в финансовом отношении GPU постоянно занимают второе место по сравнению с другими секторами. В то же время, когда AMD выпустила своё первое обновление RDNA, компания также анонсировала новую архитектуру, предназначенную только для вычислений, под названием CDNA.
Это была GCN-образная Годзилла с первым чипом, использующим данную конструкцию (Arcturus), со 128 CU в матрице площадью 750 мм². Вычислительные блоки были обновлены для размещения специализированных матричных блоков (аналогично тензорным ядрам Nvidia), и в следующем году AMD упаковала два таких огромных процессора в матрицу площадью 724 мм². Под кодовым названием Alderbaran (ниже) он быстро стал предпочтительным GPU для многих суперкомпьютерных проектов.

Возвращаясь к игровой графике, AMD стремилась использовать больше своего опыта в области процессоров. Кэш Infinity в RDNA 2 появился в результате работы, проделанной по разработке кэша L3 высокой плотности и системы межсоединений Infinity Fabric для процессоров Zen.
Поэтому было вполне естественно, что для RDNA 3 будет использоваться еще один успех CPU: чиплеты.
Но как это сделать? Гораздо проще физически разделить ядра CPU, поскольку они работают совершенно независимо. В подавляющем большинстве процессоров AMD для настольных ПК, рабочих станций и серверов вы найдете как минимум два так называемых чиплета: один содержит ядра (Core Complex Die, CCD), а другой — дом для всех структур ввода/вывода (IOD). Основное различие между ними заключается в количестве CCD.

Сделать что-то подобное в GPU — гораздо более сложная задача. GPU Navi 21 представляет собой большой блок из четырех отдельных процессоров, каждый из которых содержит 10 WGP, растеризаторы, механизмы рендеринга и кэш L1. Можно подумать, что они были бы идеальными для разделения на дискретные чипсеты, но система межсоединений, необходимая для огромного объема транзакций данных, сведёт на нет любую экономию средств и добавит много ненужной сложности и энергопотребления.
Для RDNA 3 AMD применила более взвешенный подход, основанный на ограничениях, с которыми боролись всё более мелкие технологические узлы. Когда такие компании, как TSMC, объявляют о новом производственном процессе, они обычно делают это с различными заявлениями о более высокой производительности, более низком энергопотреблении и большей плотности транзисторов.
Однако последнее является общей цифрой: транзисторы и другие схемы, связанные с логикой и обработкой, безусловно, продолжают уменьшаться в размерах, но все, что связано с передачей сигналов и памятью, не изменилось. SRAM использует массив транзисторов, действующий как своего рода энергозависимая память, но эту структуру невозможно сжать настолько, насколько это возможно с помощью логики.
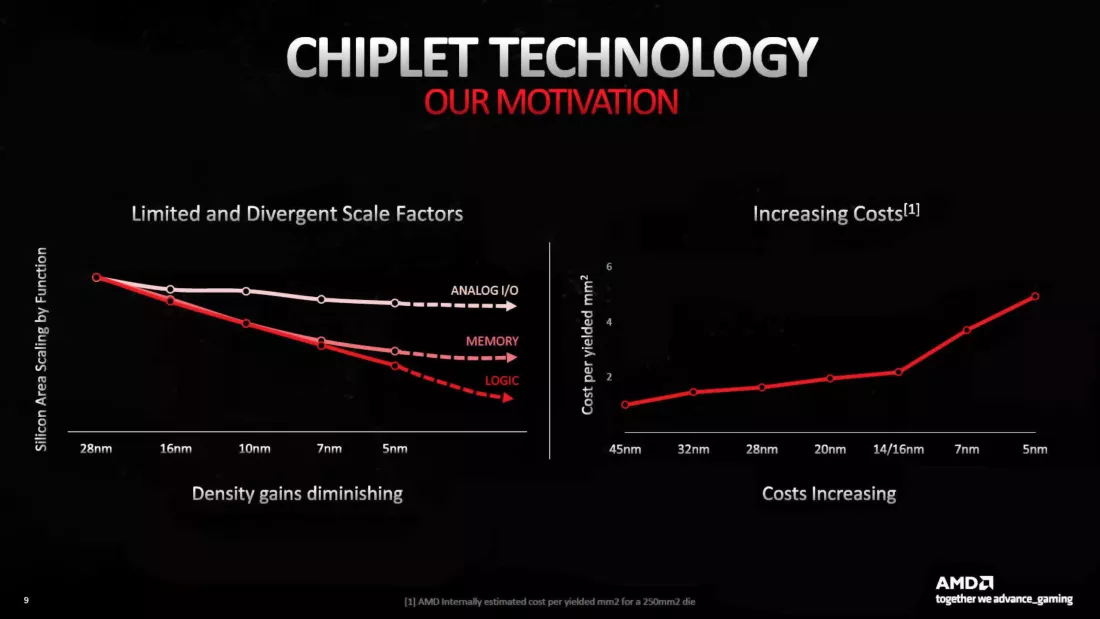
И поскольку скорости передачи сигналов для USB, DRAM и т. д. продолжают расти, более плотное расположение этих схем вызывает всевозможные проблемы с помехами. Технологический узел TSMC N5 может иметь логическую плотность, скажем, на 20% выше, чем у N7, но схемы SRAM и ввода-вывода лучше всего на несколько процентов.
Вот почему AMD решила поместить интерфейсы VRAM и L3 Infinity кэш в один чиплет, а остальную часть GPU — в другой. Первые можно было бы производить по более дешевому и менее совершенному процессу, тогда как вторые могли бы использовать преимущества чего-то лучшего.
В ноябре 2022 года AMD выпустила RDNA 3 в виде GPU Navi 31. Основной чиплет (называемый графической вычислительной матрицей, GCD) был изготовлен на технологическом узле TSMC N5 и содержал 96 CU при площади матрицы всего 150 мм². Вокруг него располагались шесть матриц кэша памяти (MCD), каждая площадью всего 31 мм², включающие 16 МБ кэша Infinity, два 32-битных интерфейса GDDR6 и одну систему Infinity Link.
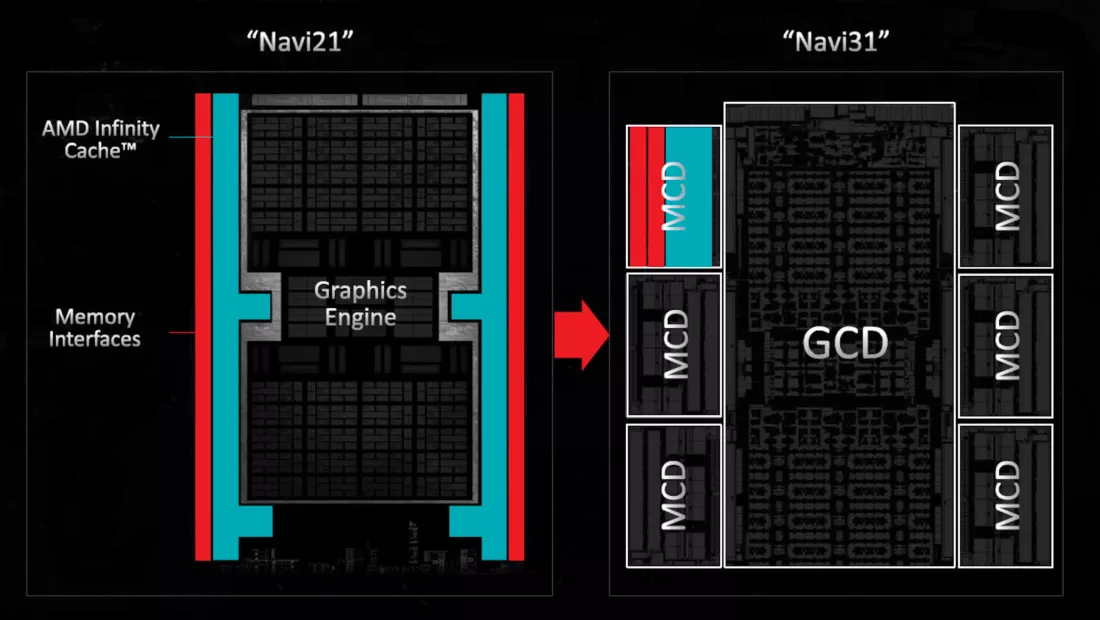
Если бы AMD решила придерживаться монолитного подхода к Navi 31, тогда весь чип, вероятно, имел бы размер всего лишь от 500 до 540 мм², и без необходимости в сложной сети связей между всеми чипсетами это было бы дешевле всё это упаковать.
AMD планировала это в течение многих лет, поэтому она явно просчитала показатели рентабельности. Все это связано с выходом пластин и ростом затрат на производство чипов. Давайте воспользуемся некоторыми ориентировочными ценами, чтобы подчеркнуть это: одна пластина N6, используемая для изготовления MCD, может стоить 12 000 долларов, но на ее основе можно будет получить более 1500 таких чиплетов (8 долларов за матрицу). Пластина N5 стоимостью 16 000 долларов может произвести 150 GCD по цене 107 долларов за матрицу.
Объедините один GCD с шестью MCD и вы получите около 154 долларов до прибавки стоимости на компановку. С другой стороны, один чип площадью 540 мм2 на пластине N5 может стоить около 250 долларов, поэтому экономическая выгода от использования чиплетов очевидна.
Передовые технологии отвечают консервативным изменениям
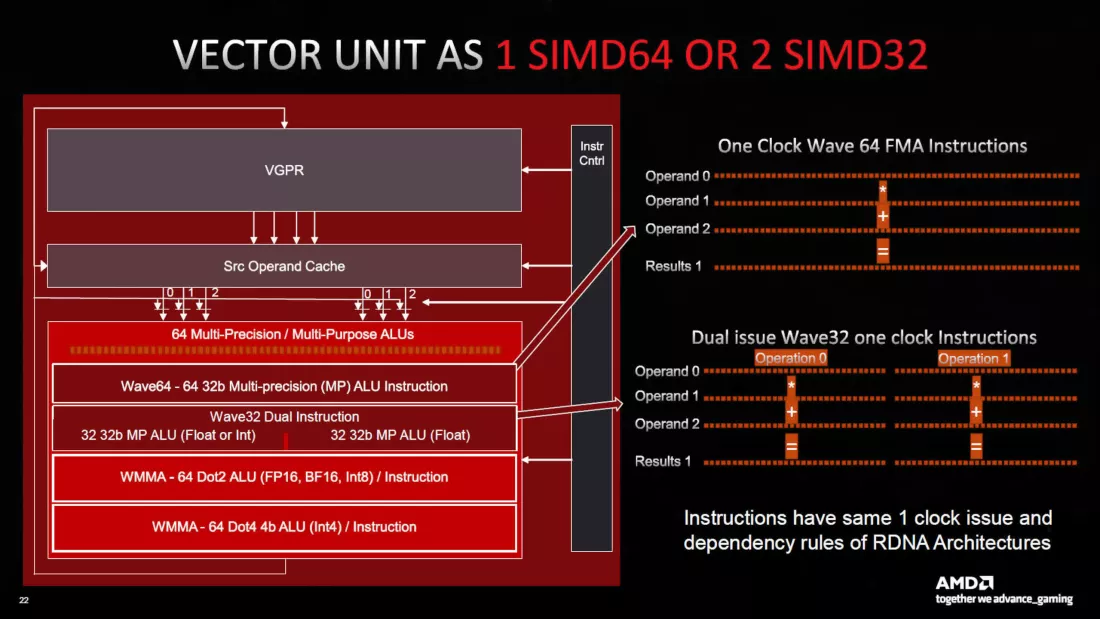
Каким бы смелым не было использование чиплетов для RDNA 3, остальные обновления оказались более консервативными. Размер файлов регистров и кэшей L0, L1 и L2 был увеличен, но кэш L3 Infinity был уменьшен. Каждый модуль SIMD был расширен для одновременной работы с 64 точками данных, поэтому обработка Wave64 теперь выполнялась за один цикл.
Производительность трассировки лучей была немного повышена, в устройства внесены изменения для повышения пропускной способности пересечения луч-треугольников, но другого специализированного оборудования для этого не было. Матричные блоки CDNA также не были скопированы в RDNA — такие операции по-прежнему выполнялись вычислительными блоками, хотя RDNA 3 имел «ускоритель искусственного интеллекта» (AMD мало что рассказала о функциях этого блока).
Довольно много шума было поднято по поводу производительности обработки нового дизайна и обсуждалась фраза «двойная проблема». При использовании он позволяет блокам SIMD обрабатывать две инструкции одновременно, и маркетинговое подразделение AMD продемонстрировало это, заявив, что пиковая пропускная способность FP32 вдвое выше, чем у RDNA 2.
Единственная проблема заключается в том, что возможность выполнять двойную выдачу инструкций во многом зависит от способности компилятора (программы в драйвере, которая преобразует код программы в операции GPU) определить, когда это может произойти. Компиляторы не очень хороши в этом и обычно требуют участия тренированного человеческого глаза для получения наилучших результатов.
Самая мощная карта с чипом RNDA 3, Radeon RX 7900 XTX, была встречена с похвалой, когда появилась на прилавках по цене 1000 долларов. Хотя в целом она не такая быстрая, как GeForce RTX 4090 от Nvidia, но, безусловно, соответствует RTX 4080, и за прошедшие с тех пор месяцы снижение цен со стороны AMD сделало ее лучшим выбором.
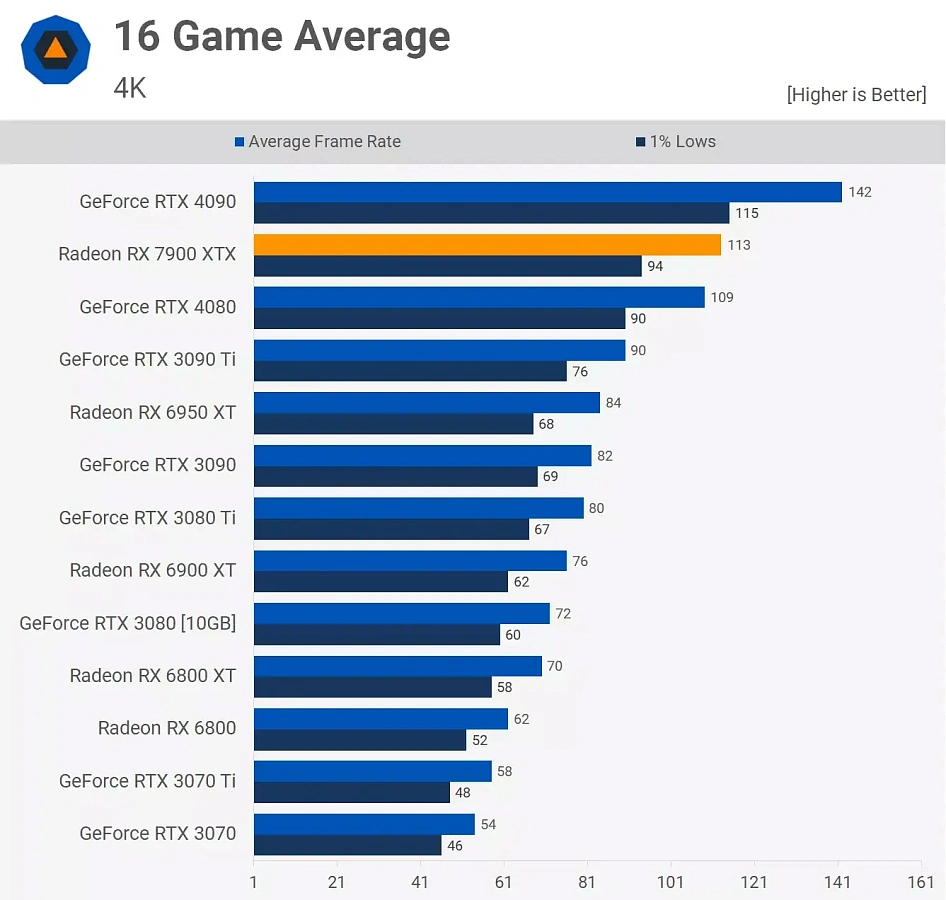
Трассировка лучей, опять же, не является сильной стороной, и, несмотря на заявления о повышении энергоэффективности, многие были удивлены тем, сколько энергии требуется Navi 31, особенно в режиме ожидания. Хотя ему, безусловно, требовалось меньше энергии, чем предыдущему Navi 21, потребность в системе Infinity Link частично нивелировала любые выгоды от использования более совершенных технологических узлов.
Ещё одним недостатком по сравнению с RDNA 2 была широта ассортимента продукции. Не так давно RDNA 3 можно было найти в 18 отдельных продуктах, хотя рыночные условия, вероятно, вынудили AMD вмешаться в этот вопрос.
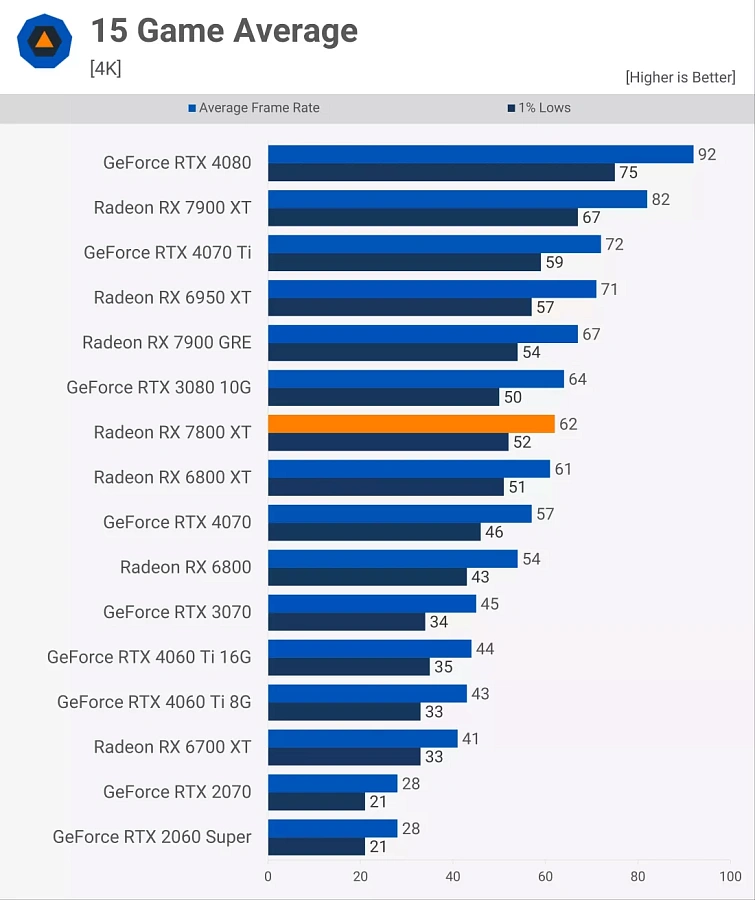
Для некоторых ещё хуже было то, что, когда наконец появились видеокарты RDNA 3 среднего и младшего класса, их относительное улучшение производительности по сравнению со старой конструкцией было несколько занижено — в случае с Radeon RX 7800 XT оно было просто на несколько процентов быстрее, чем уходящий RX 6800 XT.
И использование чиплетов, похоже, не сильно улучшило операционную прибыль AMD. За три квартала, прошедшие с момента появления RDNA 3, выручка и прибыль игрового подразделения оставались практически на прежнем уровне. Конечно, возможно, что новые GPU действительно улучшили ситуацию, потому что, если бы продажи консольных APU снизились, казалось бы, единственный способ сохранить финансовые показатели такими же — это если GPU станут более прибыльными.
Однако AMD больше не продает APU только Microsoft и Sony. Карманные ПК, такие как Steam Deck от Valve, становятся все более популярными, и поскольку все они оснащены чипами AMD, эти продажи внесут свой вклад в банковский баланс игрового подразделения.
Что будущее готовит для RDNA
Если подводить итоги того, чего AMD достигла с RDNA за четыре года, и оценить общий успех изменений, конечный результат окажется где-то между Bulldozer и Zen. Поначалу первый вариант стал почти катастрофой для компании, но с годами окупился тем, что его производство было дешевым. Zen, с другой стороны, отличился с самого начала и вызвал сейсмический переворот на всем рынке процессоров.
Хотя сложно точно судить, насколько хорошо это было для AMD. RDNA и две ее версии явно не относятся ни к Bulldozer, ни к Zen. Ее рыночная доля в секторе дискретных GPU за это время немного колебалась, иногда опережая Nvidia, а иногда теряя, но в целом она осталась прежней.
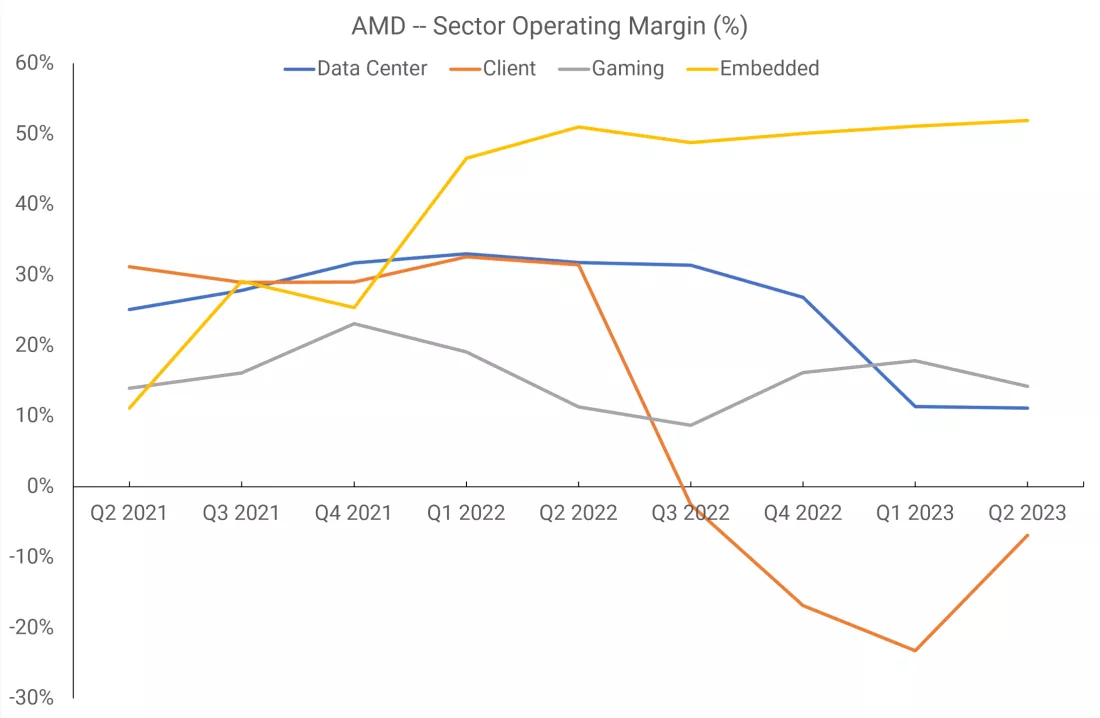
Игровое подразделение с момента своего создания получало небольшую, но стабильную прибыль, и хотя прибыль, похоже, в настоящее время снижается, нет никаких признаков надвигающейся гибели. Фактически, только с точки зрения прибыли, это второе лучшее подразделение AMD!
И даже если бы это было не так, AMD зарабатывает более чем достаточно денег на своем подразделении встраиваемых систем (благодаря покупке Xilinx), чтобы предотвратить любые короткие периоды общих потерь.
Но куда же пойдёт AMD дальше?
Есть только три пути вперед: первый — продолжать текущий курс незначительных архитектурных обновлений, получать небольшую прибыль и удерживать узкую часть всего рынка GPU. Второй — отказаться от сектора высокопроизводительных GPU для настольных ПК и полностью сосредоточиться на доминировании на рынках бюджетных и недорогих процессоров, заострив внимание на технологиях, которые еще больше уменьшают размеры матриц и увеличивают выход пластин.
Третий путь является полной противоположностью второго – забыть о «лучшем соотношении цены и качества», а также об архитектуре, которая может масштабироваться до любого возможного уровня, и сделать все, чтобы на вершине каждого графика производительности была видеокарта Radeon, а не GeForce.

Nvidia достигает этого с RTX 4090 благодаря использованию наилучшего технологического узла от TSMC и с точки зрения шейдерных блоков - крупнейшего GPU потребительского уровня, который можно купить за деньги. Здесь нет никаких хитроумных трюков – это грубый подход, который работает очень хорошо. Весь чип AD103 в RTX 4080 всего на 20% больше, чем GCD в Navi 31, и имеет достаточно схожую производительность.
Однако RDNA всегда стремилась максимально эффективно использовать имеющиеся возможности обработки. Об этом свидетельствует огромная сложность системы кэширования в RDNA 2/3, поскольку и Intel, и Nvidia используют гораздо более простую структуру в своих GPU.
Говоря о кэше, решение втиснуть огромные объемы кэша последнего уровня в GPU RDNA, чтобы компенсировать потребность в сверхбыстрой видеопамяти и повысить производительность трассировки лучей, почти наверняка вдохновило Nvidia сделать то же самое со своей Ada Lovelace архитектуре.
Сейчас мы находимся на этапе эволюции GPU, когда существует относительно небольшая разница между тем, как разные производители проектируют свои GPU, и времена, когда можно было наблюдать огромные улучшения в производительности только за счет проектирования архитектуры, давно прошли.

Если AMD хочет категорически удержать корону абсолютной производительности, ей необходимо создать GPU RDNA, который будет иметь значительно больше вычислительных блоков, чем мы видим в настоящее время. Или просто более мощные — изменение модулей SIMD в RDNA 3, возможно, является признаком того, что в следующей версии мы можем увидеть CU с четырьмя SIMD, а не с двумя, чтобы устранить все ограничения двойной проблемы.
Но даже в этом случае AMD необходимо иметь больше CU в целом, и единственный способ добиться этого — иметь гораздо больший GCD, а это означает принятие более низкой производительности или перемещение этого чипа на лучший технологический узел. И то, и другое, конечно, повлияет на прибыль, и в отличии от Nvidia, AMD, похоже, не желает завышать цены на GPU.
Вероятность выбора второго пути также мала, поскольку, как только это будет сделано, шансов на возвращение будут низкими. История GPU полна компаний, которые пытались, потерпели неудачу и ушли навсегда, как только перестали конкурировать на верхнем уровне шкалы.
Остаётся первый вариант – продолжать нынешний курс действий. Что касается архитектуры, Nvidia существенно переработала свои шейдерные ядра в течение многих лет, и только последние два поколения демонстрируют много общего. Компания также вложила значительные ресурсы в разработку и маркетинг функций машинного обучения и трассировки лучей, причем первые из них однозначно связаны с брендом GeForce.

За прошедшие годы AMD разработала множество технологий, но в эпоху RDNA ни для одной из них не требовалась видеокарта Radeon. Благодаря своей архитектуре Zen и другим изобретениям в области процессоров, AMD перетащила область вычислений в будущее, заставив Intel улучшить свою деятельность. Он принес в массы энергоэффективную многопоточную обработку — не потому, что стал более дешевой альтернативой Intel, а потому, что стал конкурировать и побеждать на голову выше.
Нельзя отрицать, что RDNA оказалась успешной разработкой, учитывая широкое распространение ее использования, но это определенно не Zen. Для роста игрового сектора недостаточно быть лучшим соотношением цены и качества или быть фаворитом сообщества благодаря подходу к программному обеспечению с открытым исходным кодом. Похоже, у AMD есть все необходимые инженерные навыки и ноу-хау, чтобы сделать это. Сделают ли они решительный шаг – это совсем другой вопрос.
Как говорится, удача любит смелых.
Источник: techspot.com