Глубокое погружение в архитектуру GPU: Nvidia Ada Lovelace, AMD RDNA 3 и Intel Arc Alchemist GPU изнутри
В области GPU, 2022 год стал значимой вехой, как в хорошем, так и в плохом смыслах. Intel выполнила своё обещание вернуться на рынок дискретных видеокарт, Nvidia увеличила размеры карт и подняла цены до небес, а AMD вывела технологию CPU на графическую арену. Заголовки тематических изданий и публикаций в сети пестрили историями о разочаровывающей производительности, плавящихся кабелях и ложных количествах fps.
Ажиотаж вокруг графических процессоров заполонил онлайн-форумы, оставив энтузиастов ПК одновременно восторженными и потрясенными трансформацией рынка видеокарт.. В этой суматохе легко забыть, что в новейших продуктах используются самые сложные и мощные чипы, которые когда-либо украшали домашние компьютеры.
В этой статье мы представим всех поставщиков и углубимся в их архитектуру. Давайте снимем фантики и посмотрим, что нового, что у них общего и что всё это значит для обычного пользователя. Это всеобъемлющее и техническое чтиво, поэтому мы разделили его на несколько частей, как показано в оглавлении далее, чтобы было легче ориентироваться и следить за логикой.
Общая структура GPU: начинаем с верхней части.
Начнем с важного аспекта этой статьи – это не сравнение производительности. Вместо этого мы смотрим на то, как все устроено внутри графического процессора, проверяем характеристики и цифры, чтобы понять различия в подходах AMD, Intel и Nvidia, когда дело доходит до проектирования своих GPU.
Разберёмся с общим устройством графических процессоров для самых крупных существующих чипов, использующих архитектуры, которые мы проверим. Важно подчеркнуть, что предложение Intel не ориентировано на тот же рынок, что и предложения AMD или Nvidia, поскольку это скорее графический процессор среднего класса.
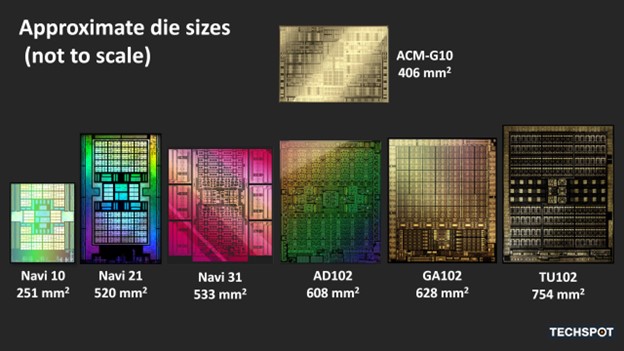
Все три сильно отличаются по размеру не только друг от друга, но и от аналогичных чипов, использующих предыдущие архитектуры. Весь этот анализ предназначен исключительно для понимания того, что именно находится под капотом всех трёх процессоров. Мы рассмотрим общую структуру, прежде чем разбирать основные разделы каждого графического процессора — шейдерные ядра, возможности трассировки лучей, иерархию памяти, а также дисплейные и медиа-движки.
AMD Navi 31
Первым рассмотрим AMD Navi 31, их самый крупный чип на базе RDNA 3, анонсированный на данный момент. По сравнению с Navi 21, их предыдущим топовым GPU, мы видим явный рост количества компонентов.
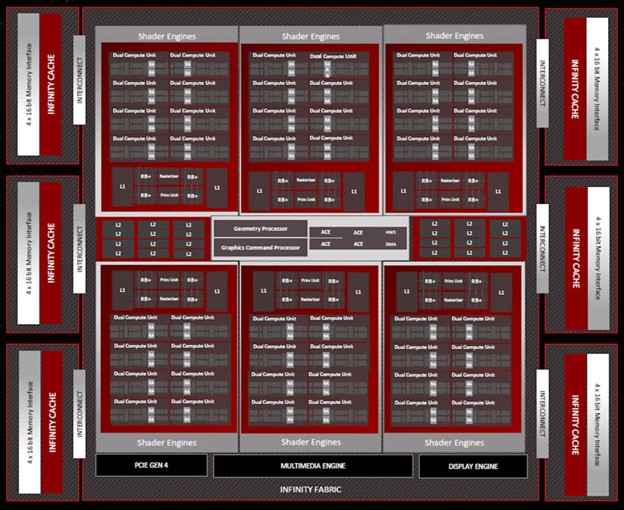
В шейдерных движках (SE) меньше вычислительных блоков (CU) — 16 против 200, но всего SE теперь 6 — на два больше, чем раньше. Это означает, что Navi 31 имеет до 96 CU, в общей сложности 6144 потоковых процессоров (SP). AMD выполнила полное обновление SP для RDNA 3, и мы рассмотрим это позже в статье.
Каждый шейдерный движок также содержит специальный блок для обработки растеризации, примитивный движок для настройки треугольников (RGB), 32 блока вывода рендеринга (ROP) и два кэша L1 по 256 КБ. Последний аспект теперь увеличен вдвое, но количество ROP для каждого SE осталось прежним.
AMD также не сильно изменила растеризатор и примитивные движки — заявленные улучшения в 50% относятся к матрице в целом, поскольку она имеет на 50% больше SE, чем чип Navi 21. Однако есть изменения в том, как SE обрабатывают протоколы, такие как более быстрая обработка нескольких команд отрисовки и лучшее управление этапами конвейера, что должно сократить время ожидания CU, прежде чем он сможет перейти к другой задаче. Самое очевидное изменение, которое вызвало больше всего слухов и сплетен перед ноябрьским запуском — чиплетный подход к корпусу GPU. Имея несколько лет опыта в этой области, вполне логично, что AMD решила сделать это, но исключительно из соображений стоимости/производства, а не из-за производительности.
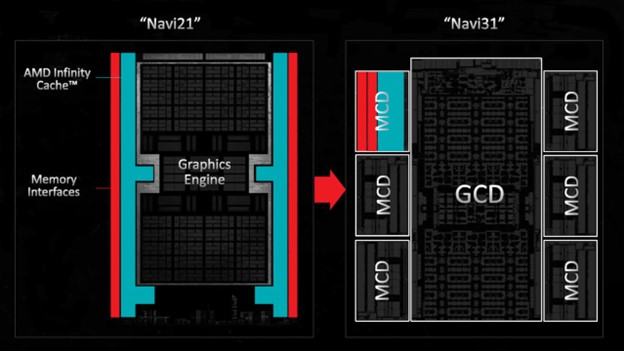
Мы более подробно рассмотрим это позже в статье, а пока давайте просто сконцентрируемся на том, где какие части находятся. В Navi 31 контроллеры памяти и связанные с ними разделы кэша последнего уровня размещены в отдельных микросхемах (называемых MCD или матрицами кэша памяти), которые окружают основной процессор (GCD, матрица графических вычислений). С увеличением числа SE, которые нужно питать, AMD также увеличила количество MC на 50%, поэтому общая ширина шины основной памяти GDDR6 теперь составляет 384 бита. На этот раз Infinity Cache меньше (96 Мбайт против 128 Мбайт), но большая пропускная способность памяти компенсирует это.
Intel ACM-G10
Переходим к Intel и матрице ACM-G10 (ранее именуемой DG2-512). Хоть это и не самый большой GPU, производимый Intel, это их самая большая потребительская графическая матрица. Блок-схема представляет собой довольно стандартную структуру, хотя она больше похожа на схему Nvidia, чем AMD. Всего имеется 8 фрагментов рендеринга, каждый из которых содержит 4 ядра Xe, что в сумме составляет 512 векторных движков (эквивалент потоковых процессоров AMD и ядер CUDA от Nvidia).

В каждый фрагмент рендеринга также упакован примитивный блок, растеризатор, процессор буфера глубины, 32 текстурных блока и 16 ROP. На первый взгляд этот GPU может показаться довольно большим, поскольку 256 TMU и 128 ROP — это больше, чем, например, у Radeon RX 6800 или GeForce RTX 2080. Однако чип AMD RNDA 3 содержит 96 вычислительных блоков, каждый из которых имеет 128 ALU, тогда как ACM-G10 имеет в общей сложности 32 ядра Xe по 128 ALU на ядро. Таким образом, только с точки зрения количества ALU, графический процессор Intel на базе Alchemist в три раза меньше, чем у AMD. Но, как мы увидим позже, значительная часть матрицы ACM-G10 отдана другому блоку обработки чисел.
По сравнению с первым графическим процессором Alchemist, выпущенным Intel через OEM-поставщиков, этот чип имеет все признаки зрелой архитектуры с точки зрения количества компонентов и структурного расположения.
Nvidia AD102
Завершаем начальный обзор различных компоновок на примере AD102 от Nvidia, первого GPU, использующего архитектуру Ada Lovelace. По сравнению со своим предшественником, Ampere GA102, он не кажется совсем другим, просто он намного крупнее. И, по большому счету, так оно и есть. Nvidia использует иерархию компонентов, состоящую из кластера графической обработки (GPU), в который входят 6 кластеров обработки текстур (TPC), в каждом из которых размещаются 2 потоковых мультипроцессора (SM). Эта схема не изменилась с выходом Ada, но общее количество, конечно, изменилось...
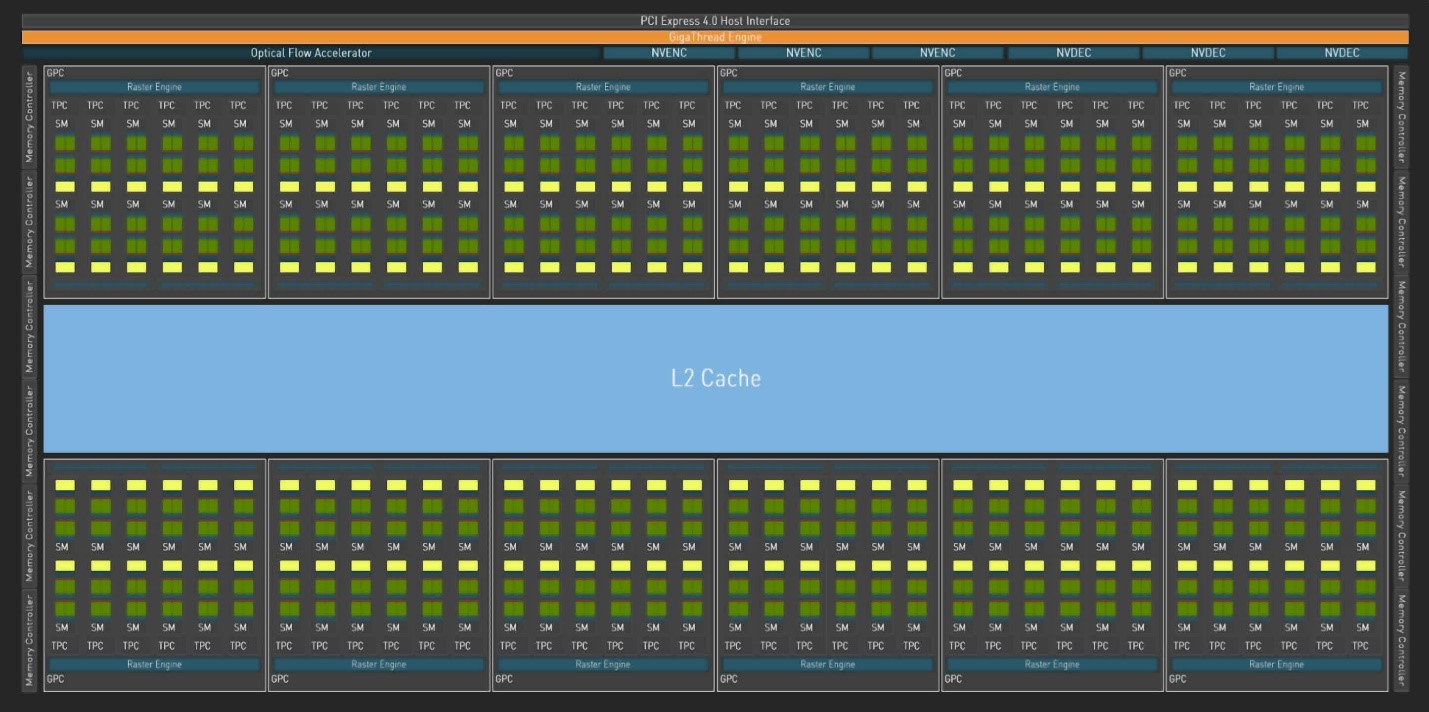
В полном корпусе AD102 количество GPC увеличилось с 7 до 12, так что теперь в нем насчитывается 144 SM, что дает в общей сложности 18432 ядра CUDA. Это может показаться смехотворно большим числом по сравнению с 6144 SP в Navi 31, но AMD и Nvidia считают свои компоненты по-разному. Хотя это грубое упрощение, один Nvidia SM эквивалентен одному AMD CU - оба содержат 128 ALU. Таким образом, если Navi 31 в два раза больше Intel ACM-G10 (только по количеству ALU), то AD102 в 3,5 раза больше. Именно поэтому несправедливо проводить какие-либо прямые сравнения производительности чипов, когда они так явно отличаются по масштабу. Однако когда они окажутся внутри видеокарты, будут оценены и представлены на рынке, это будет уже совсем другая история. Но что мы можем сравнить, так это самые мелкие повторяющиеся части трех процессоров.
Шейдерные ядра: внутри мозгов GPU
От обзора устройства процессора, давайте погрузимся в "сердца" чипов и рассмотрим основополагающие части процессоров, занимающихся подсчетом чисел: шейдерные ядра. Три производителя используют разные термины и фразы при описании своих микросхем, особенно когда речь идет об их обзорных диаграммах. Поэтому в данной статье мы будем использовать собственные изображения, с общими цветами и структурой, чтобы было легче понять, что одинаково, а что отличается.
AMD RDNA 3
Наименьшая унифицированная структура в шейдерной части GPU компании AMD называется Double Compute Unit (DCU). В некоторых документах его еще называют процессором рабочей группы (WGP), а в других - парой вычислительных блоков.
Обратите внимание, если что-то не показано на этих диаграммах (например, кэши констант, блоки двойной точности), это не означает, что они отсутствуют в архитектуре.
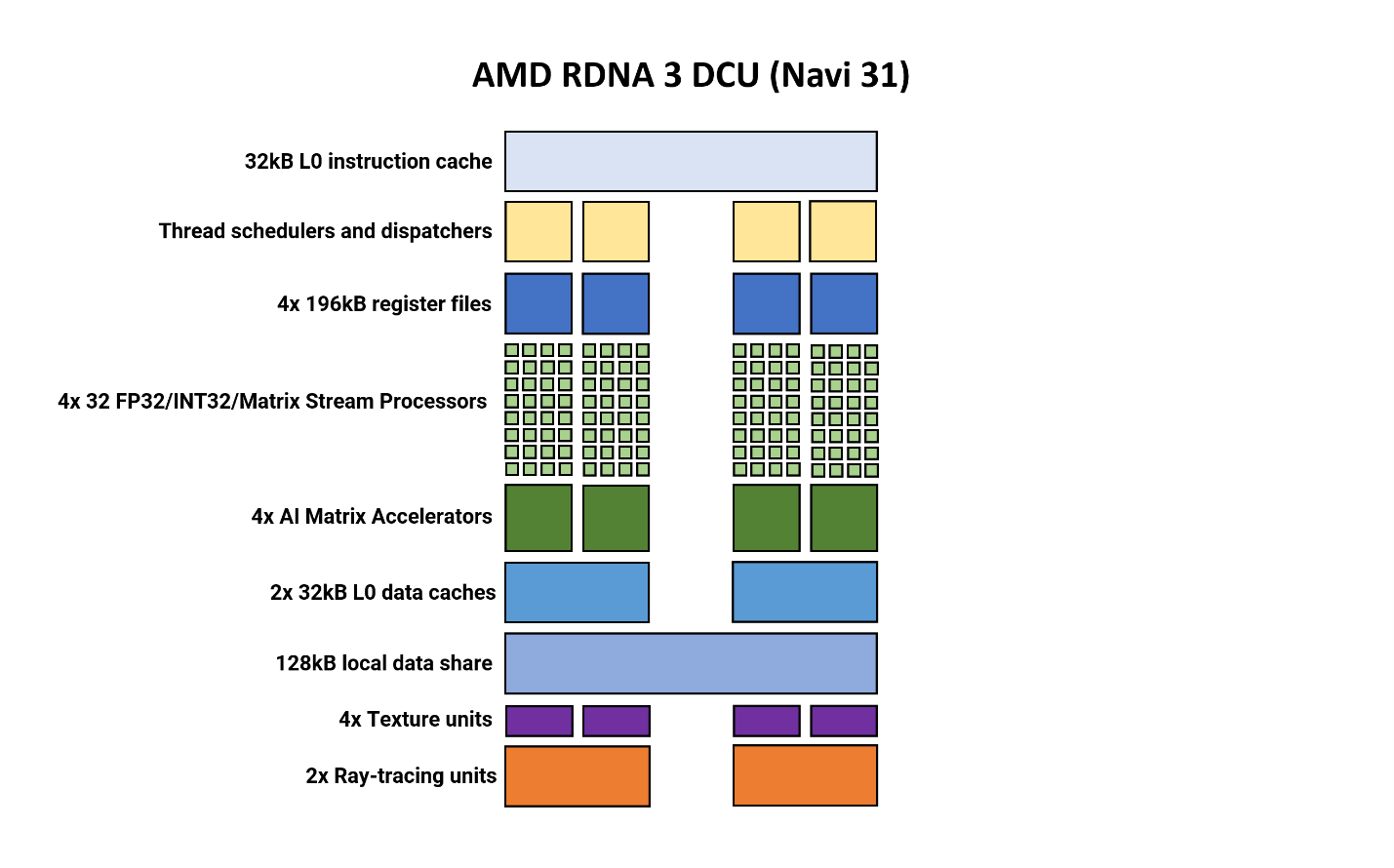
Во многом общая компоновка и структурные элементы не претерпели существенных изменений по сравнению с RDNA 2. Два вычислительных блока совместно используют кэш и память, каждый из них состоит из двух наборов по 32 потоковых процессора (SP). Новым в версии 3 является то, что в каждом SP теперь находится в два раза больше арифметических логических блоков (ALU), чем раньше. Теперь на каждый CU приходится два банка блоков SIMD64, и каждый банк имеет два порта данных - один для операций с плавающей точкой, целыми числами и матрицами, а другой - только для операций с плавающей точкой и матрицами. AMD действительно использует отдельные SP для разных форматов данных - вычислительные блоки в RDNA 3 поддерживают работу со значениями FP16, BF16, FP32, FP64, INT4, INT8, INT16 и INT32.
Использование SIMD64 означает, что каждый планировщик потоков может посылать группу из 64 потоков (так называемый волновой фронт) или совместно выпускать два волновых фронта по 32 потока за тактовый цикл. AMD сохранила те же правила работы с инструкциями, что и в предыдущих архитектурах RDNA, поэтому эта задача решается GPU/драйверами.
Еще одна существенная новинка - появление того, что AMD называет матричными ускорителями AI.
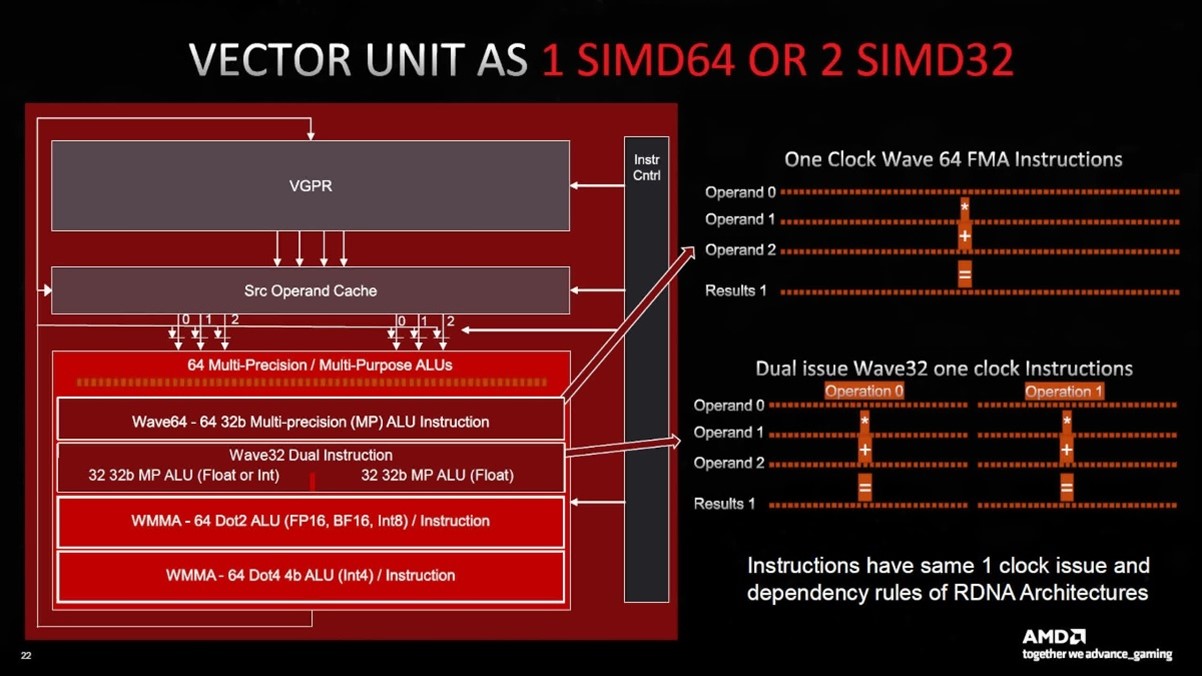
В отличие от архитектур Intel и Nvidia, которые мы рассмотрим в ближайшее время, они не выступают в качестве отдельных блоков - все матричные операции используют блоки SIMD, и любые подобные вычисления (называемые Wave Matrix Multiply Accumulate, WMMA) будут использовать весь банк из 64 ALU.
На момент написания статьи точная природа ускорителей ИИ не ясна, но, вероятно, это просто схемы, связанные с обработкой инструкций и огромного объема данных для обеспечения максимальной пропускной способности. Вполне возможно, что эта функция схожа с функциями ускорителя тензорной памяти Nvidia в архитектуре Hopper. По сравнению с RDNA 2 изменения относительно невелики - старая архитектура также могла обрабатывать 64-потоковые волновые фронты (так называемые Wave64), но они выпускались в течение двух циклов и использовали оба блока SIMD32 в каждом вычислительном блоке. Теперь все это можно сделать за один цикл и использовать только один SIMD-блок.

В предыдущей документации AMD заявляла, что Wave32 обычно используется для вычислительных и вершинных шейдеров (и, вероятно, для лучевых шейдеров тоже), тогда как Wave64 - в основном для пиксельных шейдеров, а драйверы компилируют шейдеры соответствующим образом. Переход на одноцикловую выдачу инструкций Wave64 даст толчок к развитию игр, сильно зависящих от пиксельных шейдеров. Однако для того, чтобы в полной мере использовать все эти дополнительные возможности, необходимо правильно их задействовать. Это характерно для всех архитектур GPU, и для этого все они должны быть сильно загружены большим количеством потоков (это также помогает скрыть задержки, присущие DRAM). Таким образом, удвоив количество ALU, AMD подтолкнула программистов к необходимости максимально использовать параллелизм на уровне инструкций. Это не является чем-то новым в мире графики, но одним из существенных преимуществ RDNA перед старой архитектурой AMD GCN было то, что для достижения полной загрузки ей не требовалось такого количества потоков в полете. Учитывая, насколько сложным стал современный рендеринг в играх, разработчикам предстоит еще немного потрудиться, когда дело дойдет до написания шейдерного кода.
Intel Alchemist
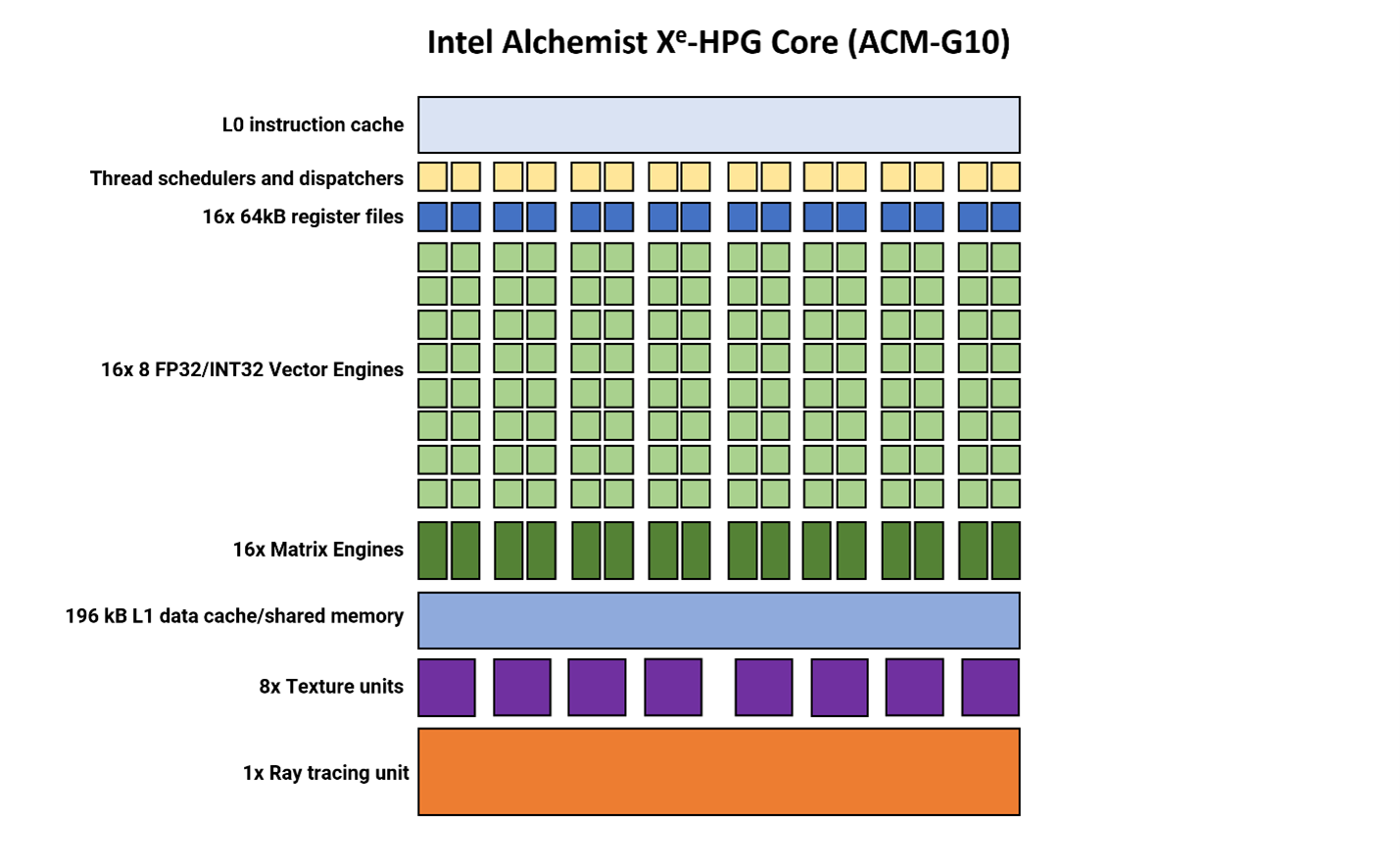
Перейдем теперь к Intel и рассмотрим DCU-эквивалент в архитектуре Alchemist, называемый Xe Core (сокращенно XEC). На первый взгляд, они выглядят совершенно огромными по сравнению со структурой AMD.
Если в RDNA 3 один DCU содержит четыре блока SIMD64, то в Intel XEC - 16 блоков SIMD8, каждый из которых управляется собственным планировщиком потоков и системой диспетчеризации. Как и потоковые процессоры AMD, так называемые векторные движки в Alchemist могут работать с целочисленными и плавающими форматами данных. Поддержка FP64 отсутствует, но в играх это не является большой проблемой.
Intel всегда использовала относительно узкие SIMD - те, что применялись в Gen11, имели ширину всего 4 (т.е. обрабатывали 4 потока одновременно), а в Gen12 (например, в процессорах Rocket Lake) ширина увеличилась вдвое.
Но если учесть, что игровая индустрия уже много лет привыкла к графическим процессорам с SIMD32, и игры кодируются соответствующим образом, то решение сохранить узконаправленные блоки кажется непродуктивным.
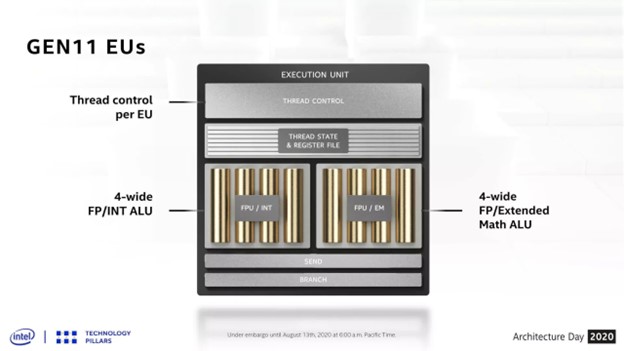
Если в RDNA 3 от AMD и Ada Lovelace от Nvidia вычислительные блоки могут выдавать 64 или 32 потока за один такт, то архитектура Intel требует 4 такта для достижения того же результата на одном VE - отсюда и шестнадцать SIMD-блоков на один XEC.
Однако это означает, что, если игры не написаны таким образом, чтобы обеспечить полную загрузку VE, SIMD-блоки и связанные с ними ресурсы (кэш, пропускная способность и т.д.) будут простаивать. Общей темой результатов бенчмарков с видеокартами Intel серии Arc является то, что они показывают лучшие результаты при высоких разрешениях и/или в играх с большим количеством сложных современных шейдерных процедур.
Отчасти это объясняется высоким уровнем разделения блоков и совместного использования ресурсов. Анализ микробенчмарков, проведенный сайтом Chips and Cheese, показывает, что при всем богатстве ALU архитектура с трудом справляется с их использованием.
Если перейти к другим аспектам XEC, то неясно, насколько велик кэш инструкций уровня 0, но если у AMD он 4-сторонний (поскольку обслуживает четыре SIMD-блока), то у Intel он должен быть 16-сторонним, что увеличивает сложность кэш-системы.
Intel также решила снабдить процессор выделенными блоками для выполнения матричных операций, по одному на каждый векторный движок. Наличие такого количества блоков означает, что значительная часть матрицы отведена под обработку матричных вычислений.

Если AMD использует для этого SIMD-блоки DCU, а Nvidia - четыре относительно крупных тензорных/матричных блока на SM, то подход Intel кажется несколько чрезмерным, учитывая, что для вычислительных приложений у нее есть отдельная архитектура, называемая Xe-HP.
Еще одной странной конструкцией кажутся блоки загрузки/хранения (LD/ST) в вычислительном блоке. Не показанные на наших диаграммах, они управляют инструкциями памяти от потоков, перемещая данные между регистровым файлом и кэшем L1. Ada Lovelace идентична Ampere с четырьмя блоками на SM-раздел, что в сумме дает 16 блоков. RDNA 3 также идентичен своему предшественнику, при этом каждый CU имеет выделенную схему LD/ST в составе текстурного блока.
В презентации Intel Xe-HPG показан всего один LD/ST на XEC, но в реальности он, скорее всего, состоит из дополнительных дискретных блоков внутри. Однако в руководстве по оптимизации для OneAPI приводится схема, на которой показано, что LD/ST циклически просматривает отдельные регистровые файлы по одному. Если это так, то Alchemist всегда будет пытаться достичь максимальной эффективности пропускной способности кэша, поскольку не все файлы обслуживаются одновременно.
Nvidia Ada Lovelace
Последний вычислительный блок, который мы рассмотрим, — это потоковый мультипроцессор (SM) Nvidia - GeForce-версия DCU/XEC. Эта структура не претерпела значительных изменений по сравнению с архитектурой Turing 2018 года. Более того, она практически идентична Ampere.
Некоторые блоки были доработаны с целью повышения производительности или расширения набора функций, но в основном говорить о чем-то новом не приходится. На самом деле, это могло бы быть так, но Nvidia, как известно, не очень охотно раскрывает информацию о внутреннем устройстве и спецификациях своих чипов. Intel предоставляет немного больше деталей, но эта информация обычно скрыта в других документах.
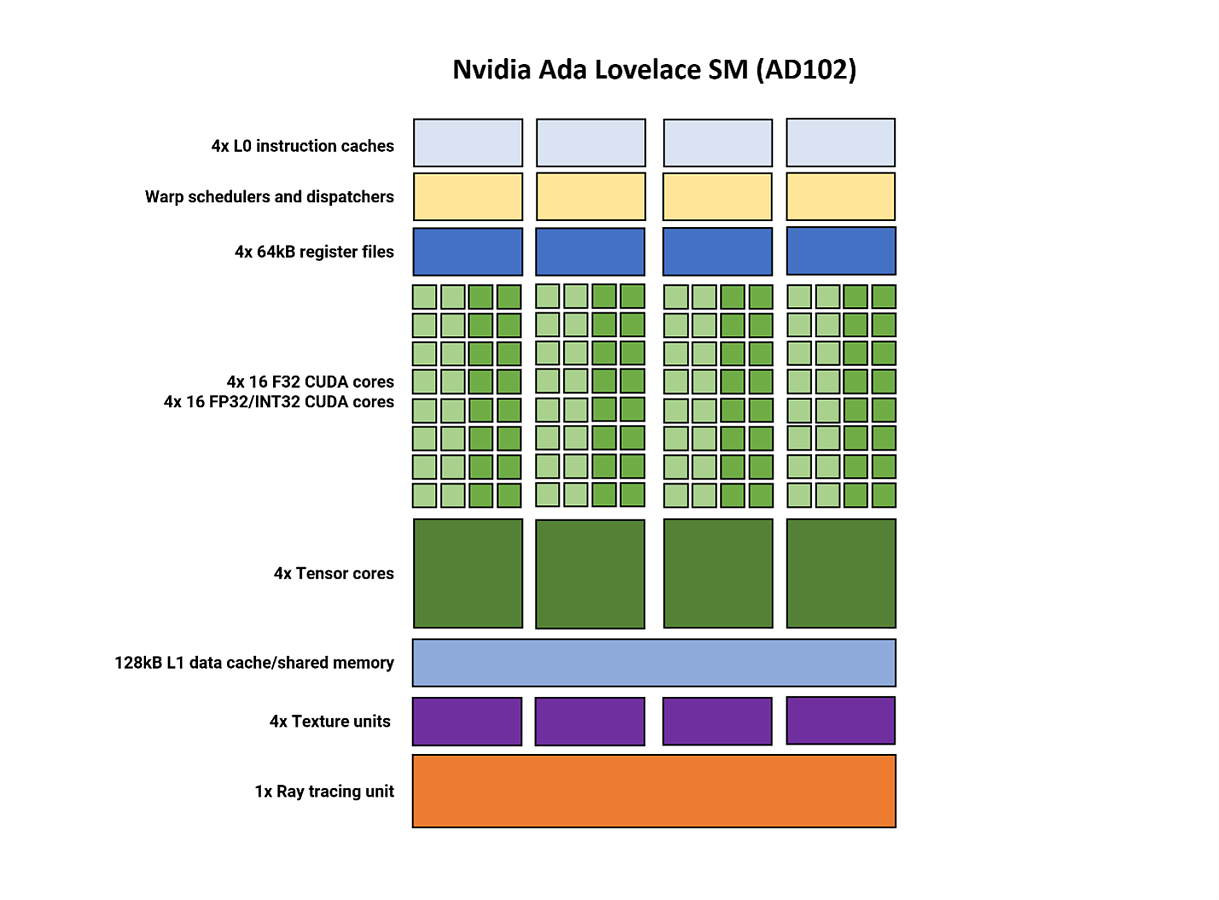
Но если кратко описать структуру, то SM разделен на четыре секции. Каждая из них имеет свой кэш инструкций L0, планировщик потоков и блок диспетчеризации, а также участок регистрового файла размером 64 кБ, сопряженный с процессором SIMD32.
Как и в AMD RDNA 3, SM поддерживает двухвыводные инструкции, когда каждый раздел может одновременно обрабатывать два потока, один с инструкциями FP32, а другой - с инструкциями FP32 или INT32.

Тензорные ядра Nvidia уже в четвертой ревизии, но на этот раз единственным заметным изменением стало включение трансформера FP8 из чипа Hopper - показатели пропускной способности остались неизменными. Добавление формата float с низкой точностью означает, что GPU будет более пригоден для обучения моделей ИИ. Тензорные ядра по-прежнему предлагают функцию sparsity от Ampere, которая может обеспечить удвоение пропускной способности. Еще одно улучшение связано с ускорителем оптических потоков (OFA) (на наших диаграммах не показан). Эта схема генерирует поле оптического потока, которое используется как часть алгоритма DLSS. Благодаря удвоенной производительности OFA в Ampere, дополнительная пропускная способность используется в последней версии временного апскейлера со сглаживанием DLSS 3.
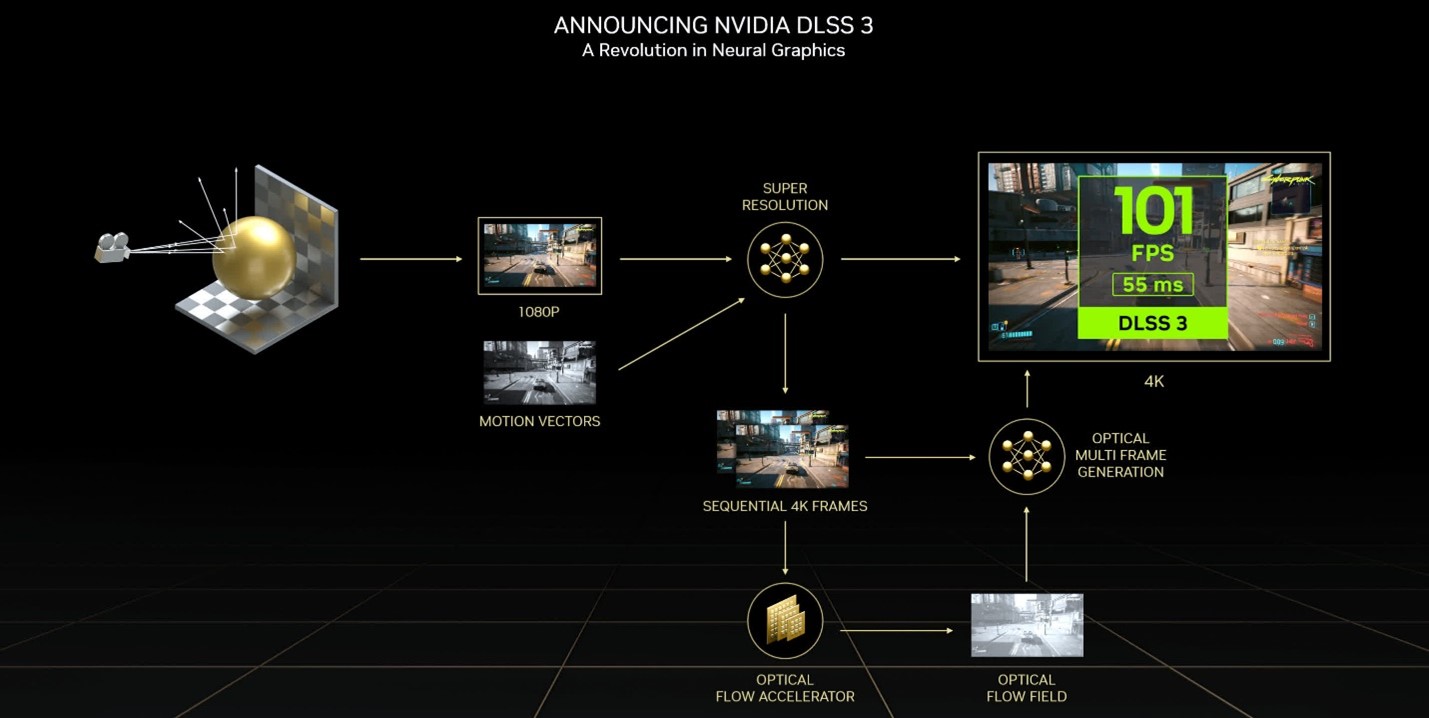
DLSS 3 уже подверглось критике, которая сводилась к двум аспектам: кадры, генерируемые DLSS, не являются "реальными", а сам процесс вносит дополнительную задержку в цепочку рендеринга. Первое утверждение не совсем верно, поскольку система работает следующим образом: сначала GPU рендерит два последовательных кадра, сохраняет их в памяти, а затем с помощью алгоритма нейронной сети определяет, как будет выглядеть промежуточный кадр. Затем цепочка возвращается к первому отрендеренному кадру и отображает его, после чего следует DLSS-кадр, а затем второй отрендеренный кадр. Поскольку движок игры не зацикливался на промежуточном кадре, экран обновляется без потенциального ввода. А поскольку два последующих кадра должны быть остановлены, а не выполнены, то любой ввод, который был опрошен для этих кадров, также будет остановлен. Станет ли DLSS 3 когда-либо популярным или обычным явлением, еще неизвестно.
Хотя SM Ada очень похож на Ampere, в ядре RT есть заметные изменения, которые мы рассмотрим в ближайшее время. Пока же подведем итоги вычислительных возможностей повторяющихся структур GPU AMD, Intel и Nvidia.
Сравнение вычислительных блоков
Мы можем сравнить возможности SM, XEC и DCU, посмотрев на количество операций для стандартных форматов данных за тактовый цикл. Обратите внимание, что это пиковые значения, которые не всегда достижимы в реальности.
Операций за такт |
Ada Lovelace |
Alchemist |
RDNA 3 |
FP32 |
128 |
128 |
256 |
FP16 |
128 |
256 |
512 |
FP64 |
2 |
n/a |
16 |
INT32 |
64 |
128 |
128 |
FP16 matrix |
512 |
2048 |
256 |
INT8 matrix |
1024 |
4096 |
256 |
INT4 matrix |
2048 |
8192 |
1024 |
Показатели Nvidia не изменились по сравнению с Ampere, в то время как у RDNA 3 в некоторых областях они удвоились. Однако Alchemist находится на другом уровне, когда речь идет о матричных операциях, хотя следует еще раз подчеркнуть, что это пиковые теоретические значения. Учитывая, что графическое подразделение Intel, как и Nvidia, в значительной степени ориентировано на центры обработки данных и вычисления, неудивительно, что архитектура отводит так много места на матрице под матричные операции. Отсутствие возможности работы с FP64 не является проблемой, поскольку этот формат данных не используется в играх, а соответствующая функциональность присутствует в архитектуре Xe-HP. Теоретически Ada Lovelace и Alchemist сильнее RDNA 3 в части матричных/тензорных операций, но поскольку мы рассматриваем GPU, используемые в основном для игровых нагрузок, выделенные блоки в основном обеспечивают ускорение алгоритмов DLSS и XeSS - в них используется конволюционная автоэнкодерная нейронная сеть (CAENN), которая сканирует изображение на предмет артефактов и корректирует их.
Временной апскейлер AMD (FidelityFX Super Resolution, FSR) не использует CAENN, так как основан преимущественно на методе ресэмплинга Ланцоша с последующей коррекцией изображения, обрабатываемого через DCU. Однако на презентации RDNA 3 была кратко представлена следующая версия FSR, в которой упоминалась новая функция Fluid Motion Frames. По общему мнению, производительность FSR 3.0 должна быть в два раза выше, чем у FSR 2.0, но будет ли она включать в себя генерацию кадров, как в DLSS 3, пока неясно.
Даёшь трассировку лучей для всех!
С выпуском серии видеокарт Arc, использующих архитектуру Alchemist, Intel присоединилась к AMD и Nvidia, предложив GPU, обеспечивающие специализированные ускорители для различных алгоритмов, связанных с использованием трассировки лучей в графике. И Ada, и RNDA 3 содержат существенно обновленные RT-блоки, поэтому имеет смысл рассмотреть, что в них нового и интересного. Начиная с AMD, самым большим изменением в их ускорителях лучей является добавление аппаратных средств для улучшения обхода иерархий граничных объемов (BVH). Это структуры данных, которые используются для ускорения определения поверхности, на которую упал луч света в 3D-мире.

В RDNA 2 вся эта работа выполнялась через вычислительные блоки, и в некоторой степени это происходит и сейчас. Однако в DXR, API трассировки лучей от Microsoft, появилась аппаратная поддержка управления флагами лучей.
Их использование позволяет значительно сократить количество обращений к BVH, что снижает общую нагрузку на пропускную способность кэш-памяти и вычислительных блоков. По сути, AMD сосредоточилась на повышении общей эффективности системы, представленной в предыдущей архитектуре.

Кроме того, в аппаратном обеспечении были улучшены алгоритмы сортировки боксов (что ускоряет их обход) и отбраковки (для пропуска тестирования пустых боксов). В сочетании с улучшениями в системе кэширования AMD утверждает, что производительность трассировки лучей увеличилась на 80% при той же тактовой частоте по сравнению с RDNA 2. Однако такие улучшения не приводят к увеличению количества кадров в секунду на 80% в играх, использующих трассировку лучей, - производительность в таких ситуациях зависит от многих факторов, и возможности блоков RT - лишь один из них. Поскольку Intel является новичком в области трассировки лучей, никаких улучшений как таковых нет. Вместо этого нам просто сообщают, что их RT-блоки обрабатывают обход BVH и расчеты пересечений между лучами и треугольниками. Это делает их более похожими на систему Nvidia, чем на систему AMD, но информации о них не так много. Зато известно, что каждый RT-блок имеет кэш неопределенного размера для хранения данных BVH и отдельный блок для анализа и сортировки потоков лучевых шейдеров с целью повышения эффективности использования SIMD.
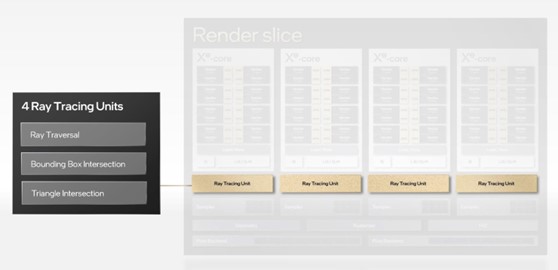
Каждый XEC работает в паре с одним RT-блоком, т. е. всего четыре блока на один фрагмент рендеринга. Первые тесты A770 с включенной трассировкой лучей в играх показали, что какие бы структуры ни использовала Intel, общие возможности Alchemist в трассировке лучей, по крайней мере, не хуже, чем у чипов Ampere, и немного лучше, чем у моделей RDNA 2. Но еще раз повторим, что трассировка лучей также сильно нагружает шейдерные ядра, кэш-систему и пропускную способность памяти, поэтому извлечь производительность RT-блока из таких бенчмарков не представляется возможным. Для архитектуры Ada Lovelace компания Nvidia внесла ряд изменений, при этом были сделаны достаточно большие заявления о повышении производительности по сравнению с Ampere. Ускорители для вычислений пересечения лучей и треугольников, как утверждается, имеют вдвое большую пропускную способность, а обход BVH для непрозрачных поверхностей теперь выполняется вдвое быстрее. Последнее важно для объектов, в которых используются текстуры с альфа-каналом (прозрачностью), например, листья на дереве.
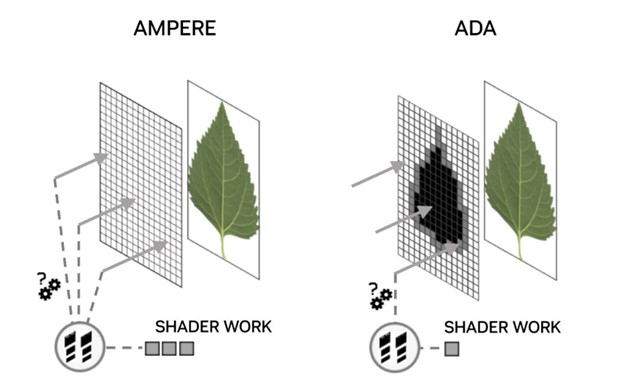
Луч, попадающий в полностью прозрачную часть такой поверхности, не должен приводить к результату попадания – луч должен пройти насквозь. Однако, чтобы точно определить это в современных играх с трассировкой лучей, необходимо обработать множество других шейдеров. Новый механизм Opacity Micromap Engine от Nvidia разбивает эти поверхности на дополнительные треугольники, а затем определяет, что именно происходит, сокращая количество необходимых лучевых шейдеров. Еще два дополнения к возможностям трассировки лучей в Ada - это сокращение времени сборки и объема памяти BVH (заявлено 10-кратное и 20-кратное сокращение соответственно), а также структура, позволяющая переупорядочивать потоки для лучевых шейдеров, что обеспечивает более высокую эффективность. Однако если первое не требует изменений в программном обеспечении разработчиков, то второе в настоящее время доступно только через API от Nvidia, поэтому оно не принесет пользы в текущих играх с DirectX 12.
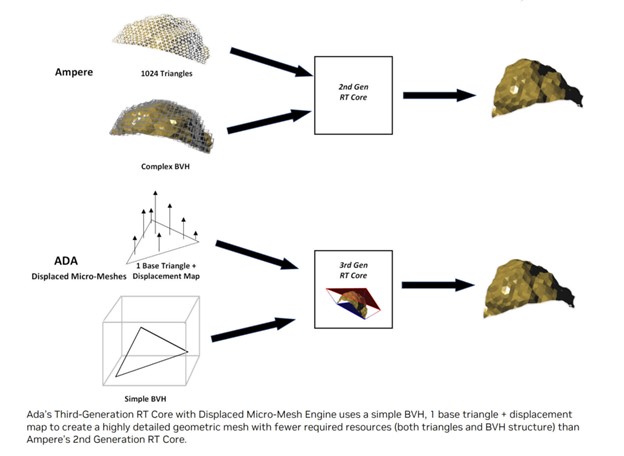
Во время тестирований производительность трассировки лучей GeForce RTX 4090, среднее падение частоты кадров при включенной трассировке лучей составило чуть менее 45%. У GeForce RTX 3090 Ti на базе Ampere это падение составило 56%. Однако это улучшение нельзя отнести исключительно на счет улучшений в ядре RT, поскольку 4090 имеет значительно большую пропускную способность и кэш-память для затенения, чем предыдущая модель. Пока не ясно, насколько улучшилась трассировка лучей в RDNA 3, но стоит отметить, что ни один из производителей GPU не ожидает, что RT будет использоваться изолированно - т.е. для достижения высокой частоты кадров по-прежнему необходимо использовать апскейлинг.
Поклонники трассировки лучей могут быть несколько разочарованы тем, что в новой серии графических процессоров в этой области не было явлено значительных успехов, однако с момента ее появления в 2018 году в архитектуре Turing от Nvidia был достигнут значительный прогресс.
Память: Проезжая по скоростному шоссе данных
Графические процессоры перебирают данные, как ни один другой чип, и обеспечение ALU числами имеет решающее значение для их производительности. На заре создания графических процессоров для ПК кэш-память практически отсутствовала, а глобальная память (оперативная память, используемая всем чипом) представляла собой отчаянно медленную DRAM. Даже всего 10 лет назад ситуация была ненамного лучше.
Итак, давайте разберемся, как обстоят дела в настоящее время, начав с иерархии памяти в новой архитектуре AMD. С момента своего появления RDNA использовала сложную, многоуровневую иерархию памяти. Самые значительные изменения произошли годом ранее, когда в GPU был добавлен огромный объем кэш-памяти L3, достигающий в некоторых моделях 128 Мбайт. Это сохранилось и в RDNA3, но с некоторыми незначительными изменениями.
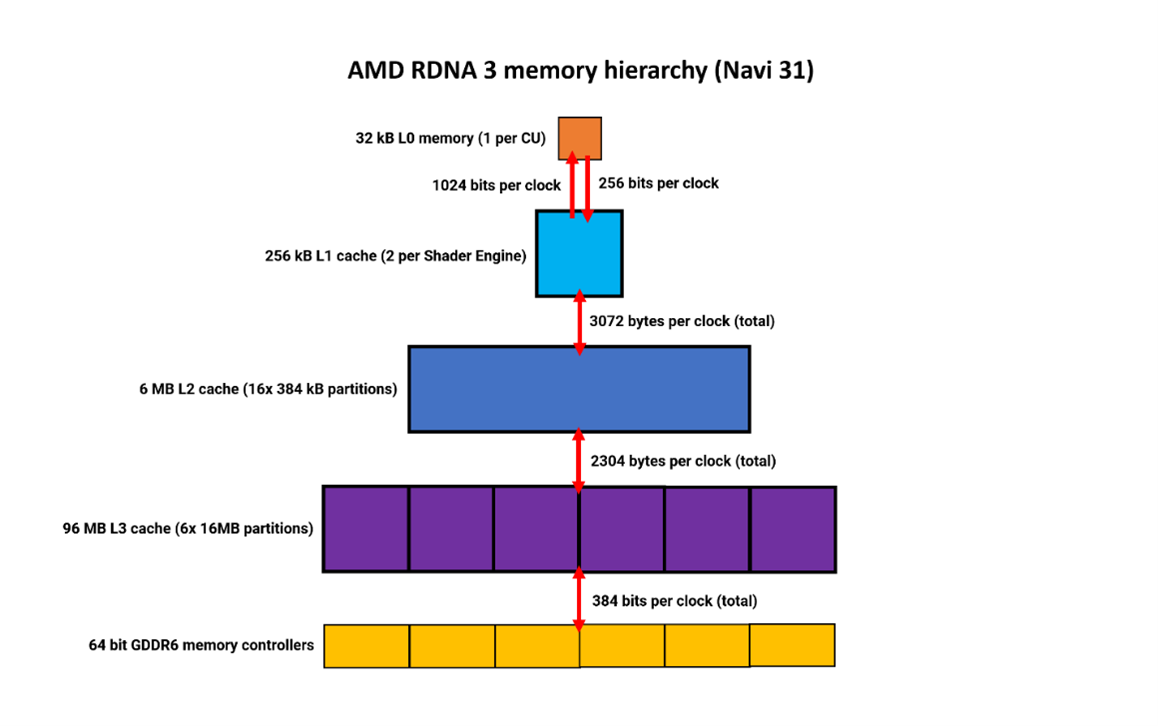
Регистровые файлы теперь на 50% больше (что и требовалось сделать, чтобы справиться с увеличением количества ALU), а первые три уровня кэш-памяти стали больше. Размер L0 и L1 удвоился, а кэш L2 увеличился до 2 Мбайт, и в общей сложности составляет 6 Мбайт на матрице Navi 31.
Кэш-память L3 фактически уменьшилась до 96 Мбайт, но на это есть веская причина - она больше не находится в матрице GPU. Подробнее об этом мы поговорим в одном из следующих разделов статьи.
Благодаря большей ширине шины между различными уровнями кэш-памяти общая внутренняя пропускная способность также значительно выше. Тактовая пропускная способность между L0 и L1 увеличилась на 50%, и на столько же - между L1 и L2. Но наибольшее улучшение наблюдается между L2 и внешним L3 - теперь они в общей сложности в 2,25 раза шире.

У Navi 21, используемой в Radeon RX 6900 XT, общая пиковая пропускная способность L2-L3 составляла 2,3 ТБ/с; у Navi 31 в Radeon RX 7900 XT этот показатель увеличивается до 5,3 ТБ/с благодаря использованию разветвителей Infinity компании AMD. Отделение кэш-памяти L3 от основной матрицы увеличивает задержки, но это компенсируется использованием более высоких тактовых частот для системы Infinity Fabric - в целом, время задержек L3 уменьшилось на 10% по сравнению с RDNA 2.
RDNA 3 по-прежнему рассчитана на использование GDDR6, а не более быстрой GDDR6X, но в топовой версии чипа Navi 31 установлены еще два контроллера памяти, что позволяет увеличить ширину глобальной шины памяти до 384 бит.
Система кэш-памяти AMD, безусловно, сложнее, чем у Intel и Nvidia, но микробенчмаркинг RDNA 2, проведенный компанией Chips and Cheese, показывает, что это очень эффективная система. Задержки низкие, и она обеспечивает фоновую поддержку, необходимую для достижения высокой загрузки CU, так что мы можем ожидать того же от системы, используемой в RDNA 3.
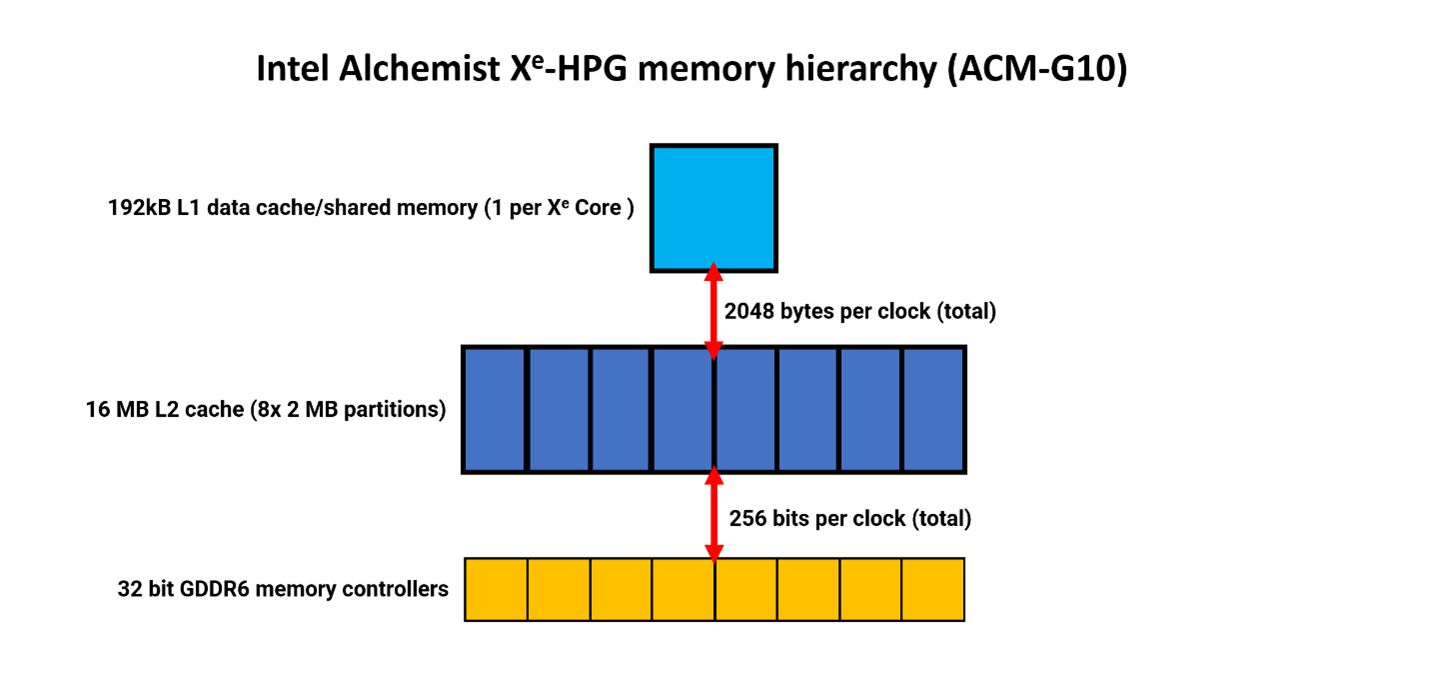
Иерархия памяти Intel несколько проще и представляет собой преимущественно двухуровневую систему (без учета небольших кэшей, например, для констант). Кэш данных L0 отсутствует, имеется лишь приличный объем 192 кбайт кэша данных и общей памяти L1.
Как и в случае с Nvidia, этот кэш может быть динамически распределен, причем до 128 Кбайт может быть доступно в качестве общей памяти. Кроме того, имеется отдельный текстурный кэш объемом 64 Кбайт (на нашей диаграмме не показан). Для чипа (DG2-512, используемого в A770), предназначенного для использования в видеокартах среднего ценового диапазона, кэш L2 очень велик - всего 16 Мбайт. Ширина данных тоже достаточно велика - всего 2048 байт за такт между L1 и L2. Этот кэш состоит из восьми разделов, каждый из которых обслуживает один 32-разрядный контроллер памяти GDDR6.
Однако анализ показал, что, несмотря на большое количество кэш-памяти и пропускной способности, архитектура Alchemist не очень хорошо справляется с их использованием, требуя рабочих нагрузок с большим числом потоков для маскировки относительно низкой латентности.
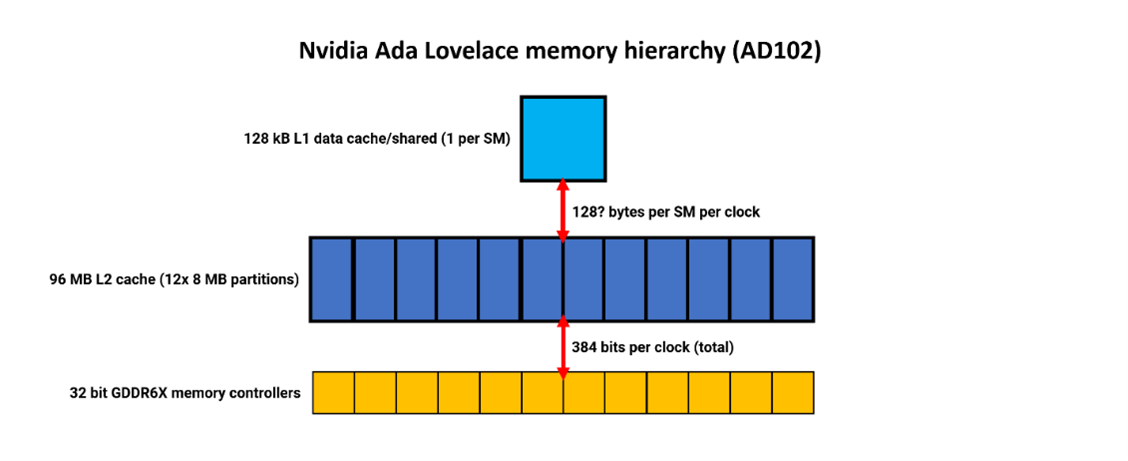
Nvidia сохранила ту же структуру памяти, что и в Ampere: каждый SM имеет 128 кбайт кэша, который выполняет функции хранилища данных L1, общей памяти и текстурного кэша. Объем памяти для разных ролей распределяется динамически. О каких-либо изменениях в пропускной способности L1 пока ничего не сообщается, но в Ampere она составляла 128 байт за такт на каждый SM. Nvidia никогда не уточняла, является ли этот показатель суммарным, объединяющим чтение и запись, или только для одного направления. Если Ada хотя бы равна Ampere, то общая пропускная способность L1 для всех SM вместе взятых составляет огромные 18 Кбайт за такт – намного больше, чем у RDNA 2 и Alchemist.
Однако следует еще раз подчеркнуть, что эти чипы нельзя сравнивать напрямую, поскольку чип Intel был создан и продавался как продукт среднего класса, а AMD ясно дала понять, что Navi 31 никогда не предназначался для конкуренции с AD102 от Nvidia. Его конкурентом является AD103, который существенно меньше AD102.
Наибольшее изменение в иерархии памяти заключается в том, что кэш-память L2 увеличилась до 96 Мбайт в полном корпусе AD102 - в 16 раз больше, чем у предшественника GA102. Как и в системе Intel, L2 разделен на разделы и работает в паре с 32-разрядным контроллером памяти GDDR6X, что обеспечивает ширину шины DRAM до 384 бит.
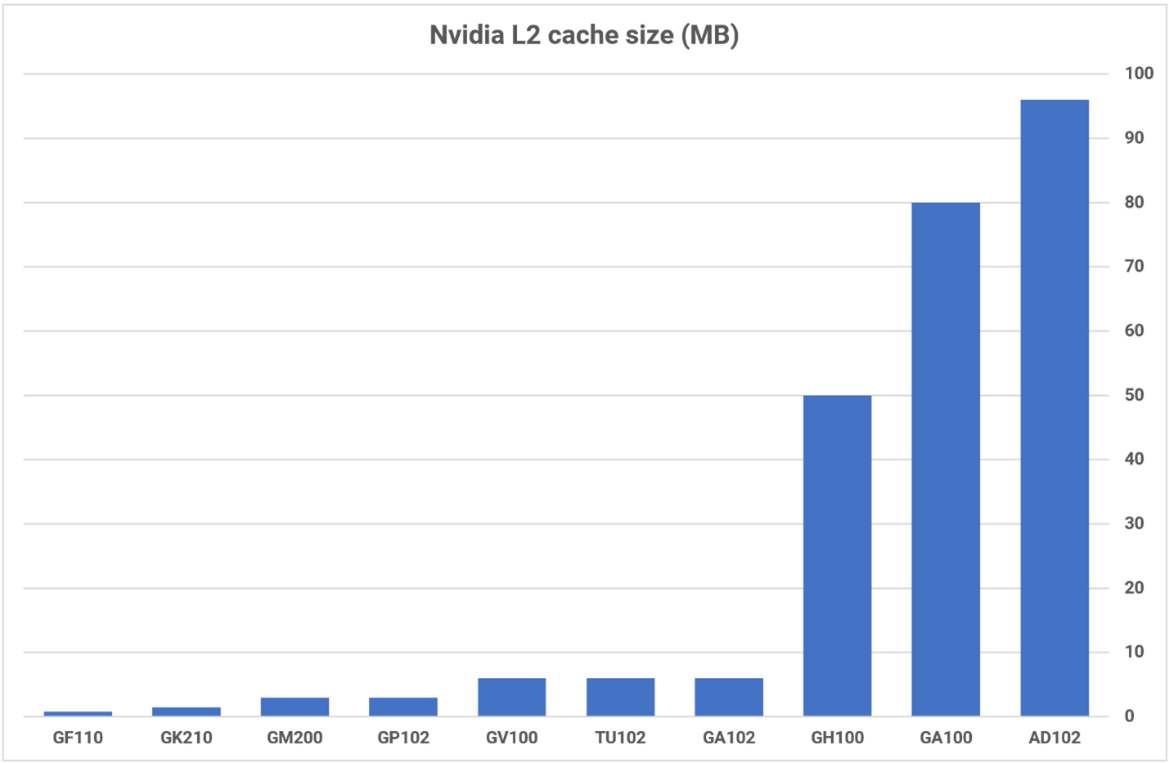
Кэш-память большего объёма обычно имеет большие задержки, чем у меньшего объёма, но, благодаря увеличению тактовой частоты и некоторым улучшениям в шинах, кэш Ada Lovelace производительнее, чем у Ampere. Если мы сравним все три системы, Intel и Nvidia используют один и тот же подход к кэшу L1 — его можно использовать как кэш данных только для чтения или как общую вычислительную память. В последнем случае графические процессоры должны быть явно проинструктированы через программное обеспечение на использование этого формата, и данные сохраняются только до тех пор, пока активны использующие их потоки. Это усложняет систему, но дает полезный прирост производительности вычислений.
В RDNA 3 кэш данных L1 и общая память разделены на два векторных кэша L0 емкостью 32 кБ и локальный ресурс данных емкостью 128 кБ. То, что AMD называет кэшем L1, на самом деле является общей ступенькой для данных, доступных только для чтения, между группой из четырех DCU и кэшем L2. Хотя пропускная способность кэш-памяти не столь высока, как у Nvidia, многоуровневый подход помогает противостоять этому, особенно когда DCU используются не полностью.

Огромные системы кэш-памяти в масштабах всего процессора, как правило, не самые лучшие для GPU, поэтому в предыдущих архитектурах мы не видели ничего больше 4 или 6 Мбайт, но причина, по которой AMD, Intel и Nvidia имеют значительные объемы на последнем уровне, заключается в том, чтобы противостоять относительному отсутствию роста скорости DRAM. Добавление большого количества контроллеров памяти в GPU может обеспечить большую пропускную способность, но за счет увеличения размеров корпуса и производственных накладных расходов, а альтернативные варианты, такие как HBM3, гораздо дороже в использовании. Нам еще предстоит увидеть, насколько хороша в итоге окажется система AMD, но их четырехуровневый подход в RDNA 2 показал хорошие результаты в борьбе с Ampere, и он существенно лучше, чем у Intel. Однако с учетом того, что Ada содержит значительно больше L2, конкуренция уже не столь однозначна.
Упаковка микросхем и технологические узлы: разные способы построения энергоснабжения
AMD, Intel и Nvidia объединяет одна общая черта - все они используют TSMC для производства своих GPU. AMD использует два разных узла для GCD и MCD в Navi 31, причем для первого используется узел N5, а для второго - N6 (улучшенная версия N7). Intel также использует N6 для всех своих чипов Alchemist. В Ampere компания Nvidia использовала старый 8-нм техпроцесс Samsung, но в Ada она вернулась к TSMC и ее техпроцессу N4, который является вариантом N5. N4 имеет самую высокую плотность транзисторов и лучшее соотношение производительности и энергопотребления среди всех техпроцессов, но когда AMD представила RDNA 3, она подчеркнула, что заметное увеличение плотности наблюдается только в логических схемах.
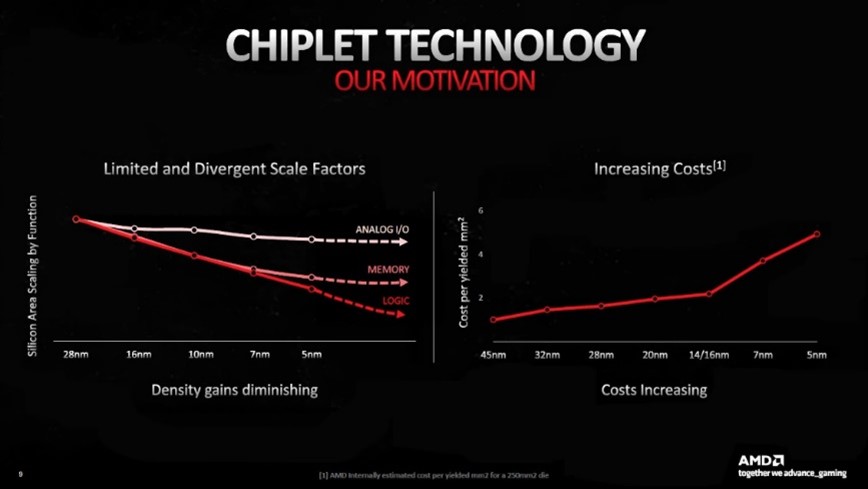
SRAM (используется для кэша) и аналоговые системы (используются для памяти, системы и других сигнальных цепей) сократились относительно незначительно. В сочетании с ростом цен на пластину для новых технологических узлов AMD приняла решение использовать немного более старый и более дешевый N6 для изготовления MCD, поскольку эти чиплеты в основном представляют собой SRAM и устройства ввода-вывода. Что касается размеров матрицы, то площадь GCD на 42% меньше, чем у Navi 21, и составляет 300 мм2. Площадь каждого MCD составляет всего 37 мм2, так что суммарно Navi 31 занимает примерно такую же площадь, как и его предшественник. AMD сообщила только общее количество транзисторов для всех чипсетов, но при 58 миллиардах новый GPU является "самым большим" потребительским графическим процессором в истории.
Для соединения каждого MCD с GCD компания AMD использует так называемые высокопроизводительные фанауты - плотно упакованные трассы, занимающие очень мало места. Infinity Links - собственная система межсоединений и сигнализации AMD - работает на скорости до 9,2 Гбит/с, а поскольку ширина канала каждого MCD составляет 384 бита, пропускная способность соединения MCD с GCD достигает 883 ГБ/с (в двунаправленном режиме). Это эквивалентно пропускной способности глобальной памяти видеокарты высокого класса, причем только для одного MCD. При использовании всех шести в Navi 31 суммарная пропускная способность L2-MCD достигает 5,3 ТБ/с.
Использование сложных ответвлений означает, что стоимость корпуса матрицы по сравнению с традиционным монолитным чипом будет выше, но процесс масштабируется — разные SKU могут использовать один и тот же GCD, но разное количество MCD. Меньшие размеры отдельных матриц микросхем должны повысить производительность пластин, но нет никаких указаний на то, предусмотрела ли AMD какой-либо резерв в конструкции MCD.

Если нет, значит любую микросхему, имеющую дефекты в SRAM, не позволяющие использовать эту часть массива памяти, придется отсортировывать для SKU младшей модели или не использовать вовсе. AMD пока анонсировала только две видеокарты RDNA 3 (Radeon RX 7900 XT и XTX), но в обеих моделях MCD имеют по 16 Мбайт кэш-памяти каждая. Если карты Radeon следующего поколения будут иметь 256-битную шину памяти и, скажем, 64 Мбайт кэш-памяти L3, то им также придется использовать «идеальные» 16 Мбайт матрицы. Однако, поскольку они настолько малы по площади, одна 300-миллиметровая пластина потенциально может дать более 1500 MCD. Даже если 50% из них придется выбросить, этого все равно будет достаточно для изготовления 125 комплектов Navi 31.
Пройдет некоторое время, прежде чем мы сможем сказать, насколько на самом деле экономически эффективна конструкция AMD, но компания полностью привержена использованию этого подхода сейчас и в будущем, но только для более крупных графических процессоров. Бюджетные модели RNDA 3 с гораздо меньшим объемом кэша будут по-прежнему использовать монолитный метод изготовления, поскольку такой способ производства более экономически эффективен. Площадь процессора Intel ACM-G10 составляет 406 мм2, общее количество транзисторов - 21,7 млрд. штук, что по количеству компонентов и площади матрицы находится где-то между Navi 21 от AMD и GA104 от Nvidia.

Это делает процессор довольно крупным, поэтому выбор Intel сектора рынка для GPU кажется несколько странным. Графическая карта Arc A770, использующая полный корпус ACM-G10, противопоставляется GeForce RTX 3060 от Nvidia - видеокарте, в которой используется чип вдвое меньшего размера и количества транзисторов, чем в Intel.
Так почему же он такой большой? Вероятных причин две: 16 Мбайт кэша L2 и очень большое количество матричных блоков в каждом XEC. Решение использовать первое логично, поскольку оно снижает нагрузку на глобальную пропускную способность памяти, но второе можно легко считать чрезмерным для сектора, в котором он продается. RTX 3060 имеет 112 ядер Tensor, тогда как A770 имеет 512 блоков XMX. Еще один странный выбор Intel — использование TSMC N6 для производства матриц Alchemist, а не собственных мощностей. В официальном заявлении по этому поводу упоминаются такие факторы, как стоимость, производственные мощности и рабочая частота чипа. Это говорит о том, что аналогичные производственные мощности Intel (с использованием переименованного узла Intel 7) не смогли бы удовлетворить ожидаемый спрос, поскольку большую часть мощностей занимают процессоры Alder и Raptor Lake.
Они бы сравнили относительное падение производительности процессоров и то, как это повлияло бы на доходы, с тем, что они получили бы от Alchemist. Короче говоря, лучше было заплатить TSMC за производство новых графических процессоров.
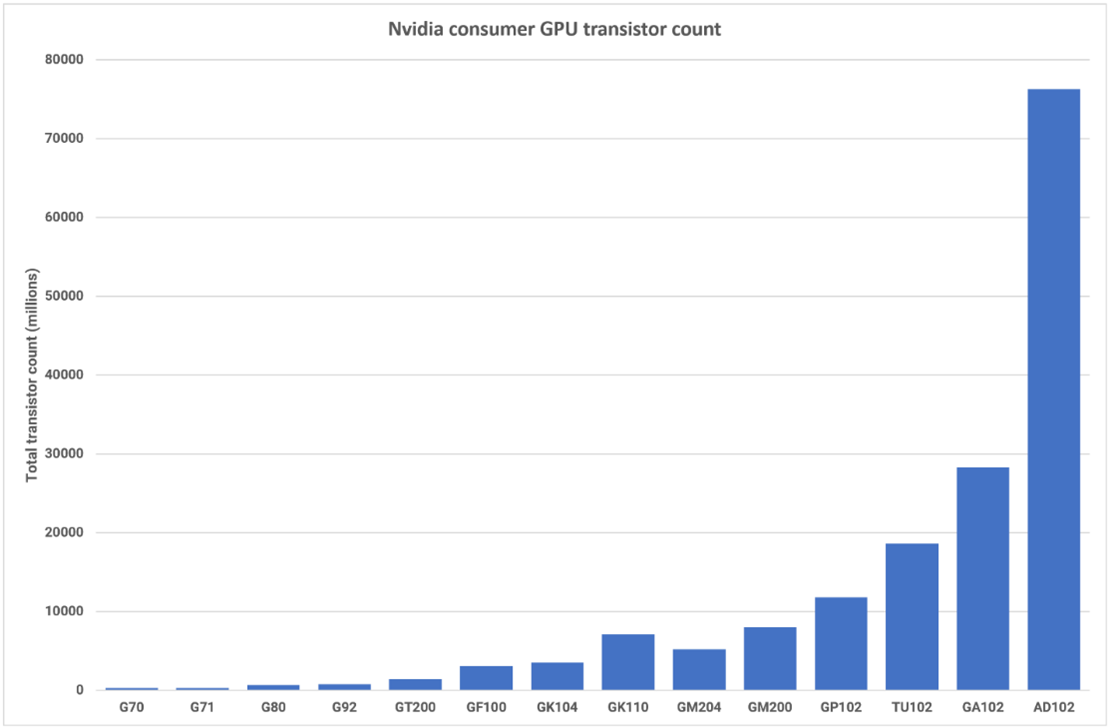
Там, где AMD использовала свой опыт работы с несколькими чипами и разработала новые технологии для производства больших графических процессоров RDNA 3, Nvidia придерживалась монолитной конструкции для линейки Ada. Компания, производящая графические процессоры, имеет значительный опыт в создании чрезвычайно больших процессоров, хотя AD102 с площадью 608 мм2 не является физически самым большим чипом, который она выпустила (эта честь принадлежит GA100 с площадью 826 мм2). Однако, имея 76,3 миллиарда транзисторов, Nvidia значительно опередила по количеству компонентов любой графический процессор потребительского уровня, наблюдавшийся до сих пор.

GA102, используемый в GeForce RTX 3080 и выше, кажется легким по сравнению с ним — всего 26,8 миллиардов. Это увеличение на 187% привело к увеличению количества SM на 71% и увеличению объема кэша L2 на 1500%.
Такому большому и сложному чипу всегда будет сложно достичь идеального выхода пластин, поэтому предыдущие топовые графические процессоры Nvidia породили множество SKU. Обычно при запуске новой архитектуры в первую очередь анонсируется профессиональная линейка видеокарт (например, A-серия, Tesla и т. д.). Когда был анонсирован Ampere, GA102 при запуске появился в двух картах потребительского уровня и в конечном итоге нашел свое применение в 14 различных продуктах. На данный момент Nvidia решила использовать AD102 только в двух видеокартах: GeForce RTX 4090 и RTX 6000.
В RTX 4090 используются матрицы, находящиеся на лучшем завершении процесса объединения, с отключенными 16 SM и 24 Мбайт кэш-памяти L2, тогда как у RTX 6000 отключены только два SM. Возникает вопрос: где остальные кубики?
Поскольку других продуктов, использующих AD102, нет, нам остается предположить, что Nvidia накапливает их, возможно, для корпоративных клиентов.
GeForce RTX 4080 использует AD103, который при площади 379 мм2 и 45,9 млрд. транзисторов совсем не похож на своего старшего брата - гораздо меньшая площадь (80 SMs, 64 Мбайт кэша L2) должна обеспечить гораздо более высокую производительность.
RTX 4070 также использует более компактный AD104, и хотя Nvidia планировала выпустить множество других GPU на архитектуре Ada, она не хотела выпускать их раньше времени. Вместо этого пришлось ждать несколько месяцев, пока видеокарты на базе архитектуры Ampere освободят полки магазинов.
Учитывая значительный прирост вычислительных возможностей AD102 и 103, несколько озадачивает тот факт, что профессиональных карт на архитектуре Ada так мало - сектор всегда жаждет большей вычислительной мощности.

Суперзвездные диджеи: Дисплей и медиа-движки
Когда речь заходит о медиа- и дисплейных движках графических процессоров, маркетинговый подход к ним часто отходит на второй план по сравнению с такими аспектами, как возможности DirectX 12 или количество транзисторов. Однако с учетом того, что индустрия потокового воспроизведения игр приносит миллиардные доходы, мы начинаем видеть, что разработка и продвижение новых функций отображения информации становится все более актуальной.
В RDNA 3 компания AMD обновила ряд компонентов, наиболее заметным из которых является поддержка DisplayPort 2.1 и HDMI 2.1a. Учитывая, что VESA, организация, контролирующая спецификацию DisplayPort, анонсировала версию 2.1 только в конце 2022 года, для производителя GPU столь быстрое внедрение системы было необычным шагом.

Самый быстрый режим передачи данных DP, который поддерживает новый дисплейный механизм, - UHBR13.5, обеспечивающий максимальную скорость передачи данных по 4 каналам 54 Гбит/с. Этого достаточно для разрешения 4K при частоте обновления 144 Гц без какого-либо сжатия на стандартных таймингах.
При использовании DSC (Display Stream Compression) соединения DP2.1 позволяют передавать изображение с частотой до 4K@480 Гц или 8K@165 Гц, что является заметным улучшением по сравнению с DP1.4a, используемым в RDNA 2.
В архитектуре Intel Alchemist реализован дисплейный движок с выходами DP 2.0 (UHBR10, 40 Гбит/с) и HDMI 2.1, хотя не все видеокарты серии Arc, использующие этот чип, могут задействовать максимальные возможности. Хотя ACM-G10 не ориентирован на игры с высоким разрешением, использование новейших спецификаций подключения дисплея позволяет использовать мониторы для киберспорта (например, 1080p, 360 Гц) без какого-либо сжатия. Возможно, чип и не сможет обеспечить такую высокую частоту кадров в подобных играх, но, по крайней мере, движок дисплея сможет.

Поддержка AMD и Intel быстрых режимов передачи данных в DP и HDMI - это то, чего можно ожидать от совершенно новых архитектур, поэтому несколько нелепо, что Nvidia решила не делать этого в случае с Ada Lovelace. AD102, при всех своих транзисторах (почти столько же, сколько у Navi 31 и ACM-G10 вместе взятых), имеет только дисплейный движок с выходами DP1.4a и HDMI 2.1. При наличии DSC первый достаточно хорош, скажем, для 4K@144 Гц, но когда конкуренты поддерживают его без компрессии, это явное упущение. Медиа-движки в графических процессорах отвечают за кодирование и декодирование видеопотоков, и все три производителя имеют обширные наборы функций в своих новейших архитектурах.
В RDNA 3 компания AMD добавила полное одновременное кодирование/декодирование формата AV1 (в предыдущей версии RDNA 2 он был только декодирован). Информации о новых медиадвижках немного, кроме того, что они могут обрабатывать два потока H.264/H.265 одновременно, а максимальная частота для AV1 составляет 8K@60 Гц. AMD также вскользь упомянула о видеодекодере 'AI Enhanced', но более подробной информации не предоставила.
ACM-G10 от Intel обладает схожим набором возможностей, кодирование/декодирование доступно для AV1, H.264 и H.265, но, как и в случае с RDNA 3, подробности весьма скудны. Некоторые ранние испытания первых чипов Alchemist в настольных видеокартах Arc позволяют предположить, что мультимедийные движки, по крайней мере, не уступают тем, что предлагали AMD и Nvidia в своих предыдущих архитектурах.
Ada Lovelace следует примеру кодирования и декодирования AV1, и Nvidia утверждает, что новая система на 40% эффективнее при кодировании, чем H.264 - якобы при использовании нового формата качество видео на 40% выше. Топовые видеокарты серии GeForce RTX 40 будут оснащаться графическими процессорами с двумя кодерами NVENC, что позволит кодировать 8K HDR с частотой 60 Гц или улучшить распараллеливание экспорта видео, когда каждый кодер работает с половиной кадра одновременно.
При наличии более подробной информации о системах можно было бы провести более точное сравнение, но поскольку мультимедийные движки все еще считаются "плохими родственниками" движков рендеринга и вычислений, нам придется подождать, пока на полках магазинов появятся карты с новейшими архитектурами от каждого производителя.
Что ждет GPU дальше?
Уже давно на рынке настольных GPU присутствуют три производителя, и очевидно, что у каждого из них свой подход к разработке графических процессоров, хотя Intel и Nvidia придерживаются схожего подхода. Для них Ada и Alchemist - это своего рода "универсал", которые можно использовать для любых игровых, научных, мультимедийных и информационных нагрузок. Упор на матричные и тензорные вычисления в ACM-G10 и нежелание полностью менять компоновку GPU говорит о том, что Intel больше склоняется к науке и данным, а не к играм, но это вполне объяснимо, учитывая потенциальный рост этих секторов. В последних трех архитектурах Nvidia сосредоточилась на улучшении того, что уже было хорошо, и уменьшении различных "узких мест" в общей конструкции, таких как внутренняя пропускная способность и задержки. Но если Ada является естественным усовершенствованием Ampere, которому Nvidia следует уже несколько лет, то AD102 выделяется как эволюционная странность, если взглянуть на масштаб количества транзисторов.
Разница по сравнению с GA102 просто поразительна, но этот колоссальный скачок порождает ряд вопросов. Первый из них заключается в том, был ли AD103 лучшим выбором для Nvidia, если бы она использовала его в своих потребительских продуктах высшего класса вместо AD102?
Производительность AD103, используемого в RTX 4080, заметно выше, чем у RTX 3090, а 64 Мбайт кэш-памяти L2, как и у его старшего брата, помогают компенсировать относительно узкую 256-битную ширину глобальной шины памяти. При площади 379 мм2 она меньше, чем GA104, используемая в GeForce RTX 3070, поэтому ее производство будет гораздо выгоднее, чем производство AD102. Кроме того, в нем установлено столько же SM, сколько и в GA102, а этот чип в итоге нашел свое место в 15 различных продуктах.
Другой вопрос, который стоит задать, - куда дальше пойдет Nvidia в плане архитектуры и производства? Сможет ли она достичь аналогичного уровня масштабирования, оставаясь при этом монолитным чипом?
Выбор AMD в пользу RDNA 3 показывает потенциальный путь, по которому могут пойти конкуренты. Выделив в отдельные чипсеты те части корпуса, которые хуже всего масштабируются (в новых технологических узлах), AMD смогла успешно продолжить большой скачок в области производства и дизайна, сделанный между RDNA и RDNA 2.
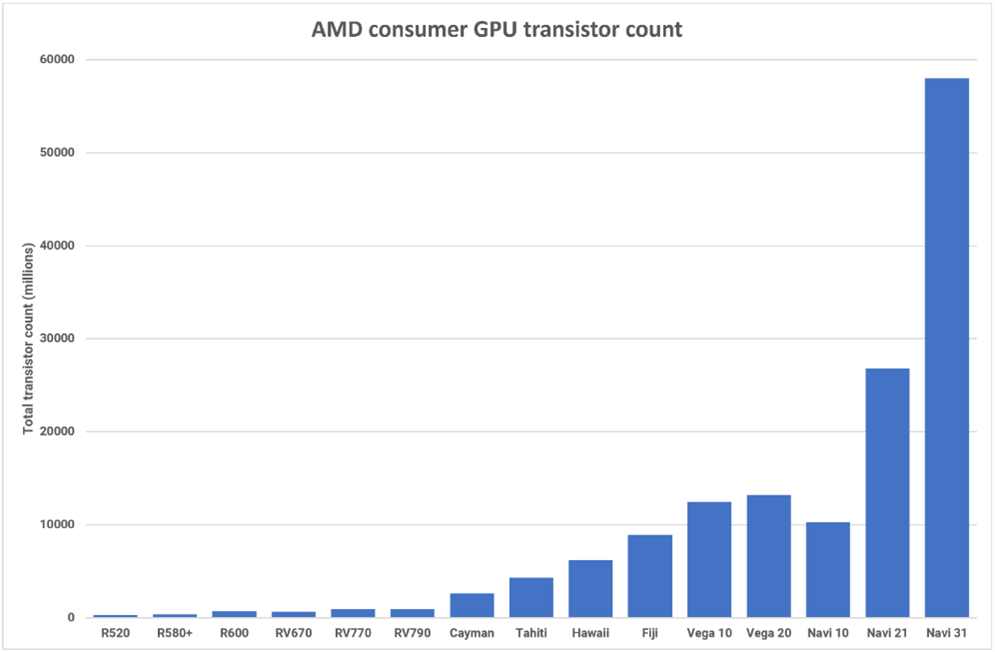
Несмотря на то, что AMD Navi 31 не такой большой, как AD102 от Nvidia, он по-прежнему содержит 58 миллиардов кремниевых транзисторов – более чем в два раза больше, чем в Navi 21, и более чем в 5 раз больше, чем в исходном графическом процессоре RDNA, Navi 10 (хотя он не подразумевался как яркий продукт).
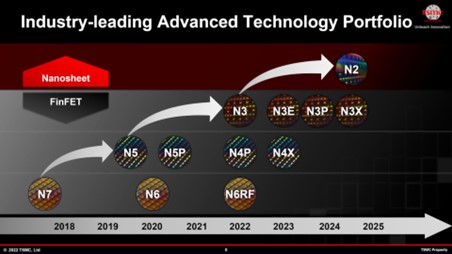
Достижения AMD и Nvidia не были изолированы друг от друга. Столь значительное увеличение количества транзисторов графического процессора возможно только из-за жесткой конкуренции между TSMC и Samsung за звание ведущего производителя полупроводниковых устройств. Оба работают над улучшением плотности транзисторов в логических схемах, продолжая при этом снижать энергопотребление. У TSMC есть четкий план действий по доработке текущих узлов и следующих основных процессов.
Будет ли Nvidia копировать опыт AMD и переходить на чиплеты в преемнике Ada, пока неясно, но ближайшие год-два, вероятно, станут решающими. Если RDNA 3 окажется финансово успешным, будь то по доходам или общему количеству поставленных устройств, то есть большая вероятность, что Nvidia последует этому примеру.
Однако первым чипом с архитектурой Ampere стал GA100 - графический процессор для центров обработки данных площадью 829 мм2 и с 54,2 млрд. транзисторов. Он был изготовлен компанией TSMC на узле N7 (таком же, как RDNA и большая часть линейки RDNA 2). Использование узла N4 для производства AD102 позволило Nvidia создать GPU с почти вдвое большей плотностью транзисторов, чем у предшественника.
Графические процессоры по-прежнему являются одним из самых выдающихся инженерных достижений в настольных ПК.
Будет ли это достижимо с использованием N2 для следующей архитектуры? Возможно, но значительный рост кэша (который очень плохо масштабируется) предполагает, что даже если TSMC достигнет выдающихся показателей со своими будущими узлами, держать под контролем размеры графических процессоров будет все труднее.
Intel уже использует чиплеты, но только со своим огромным графическим процессором для центров обработки данных Ponte Vecchio. Состоящий из 47 различных плиток, некоторые из которых изготовлены TSMC, а другие — самой Intel, его параметры достаточно высоки. Например, благодаря более чем 100 миллиардам транзисторов в полной конфигурации с двумя графическими процессорами AMD Navi 31 выглядит стройнее. Это, конечно, не какой-либо настольный ПК и, строго говоря, не «просто» графический процессор — это процессор для центров обработки данных с упором на матричные и тензорные рабочие нагрузки.

Учитывая, что архитектура Xe-HPG рассчитана как минимум на две ревизии, прежде чем перейти к «Xe Next», мы вполне можем увидеть использование тайлинга в потребительских видеокартах Intel.
Однако на данный момент Ada и Alchemist будут использовать традиционные монолитные матрицы, в то время как AMD использует совмещение систем микросхем для карт верхнего и среднего уровня, а также одиночные матрицы для своих бюджетных моделей.
К концу десятилетия мы можем увидеть почти все виды графических процессоров, построенных из множества различных плиток и чиплетов, изготовленных с использованием различных технологических узлов. Графические процессоры по-прежнему остаются одним из самых выдающихся инженерных достижений настольных ПК: количество транзисторов не показывает никаких признаков замедления роста, а о вычислительных возможностях средней видеокарты сегодня можно было только мечтать около 10 лет назад.
Что тут добавить: да будет новая битва процессорных архитекторов!