
Что такое тензорные ядра?
В течение последних трех лет Nvidia производит графические чипы с дополнительными ядрами, помимо обычных, используемых для шейдеров. Эти загадочные блоки, известные как тензорные ядра, можно найти в тысячах настольных ПК, ноутбуках, рабочих станциях и дата-центрах по всему миру. Но что они собой представляют и для чего используются? Нужны ли они вообще в наших видеокартах?
Сегодня мы объясним, что такое тензор и как тензорные ядра применяются в мире графики и глубокого обучения.
Немного математики
Чтобы понять, что делают тензорные ядра и для чего они используются, нам сперва нужно выяснить, что такое тензоры. Любые микропроцессоры, независимо от типа, выполняют математические операции над числами (сложение, умножение и т.д.).
Иногда эти числа нужно сгруппировать, так как они имеют неразрывную связь друг с другом. Например, когда чип обрабатывает данные для рендеринга, он может иметь дело с одиночными целочисленными значениями (такими как +2 или +115) для коэффициента масштабирования, либо же с группой чисел с плавающей точкой (+0,1, -0,5, + 0.6) для определения координат какой-то точки в трехмерном пространстве. В последнем случае для определения местоположения точки требуются все три части данных.

Источник: techspot.com
Простейший тип тензора не имеет измерений и состоит из одного значения – это то же, что и скалярная величина. По мере увеличения количества измерений, появляются другие распространенные математические структуры:
- 1 измерение = вектор
- § 2 измерения = матрица
Строго говоря, скаляр – это тензор 0 x 0, вектор – 1 x 0, а матрица – 1 x 1, но для простоты мы рассмотрим только матричную структуру в контексте наших тензорных ядер в графическом процессоре.
Одна из важнейших математических операций, выполняемых с матрицами – это умножение. Давайте посмотрим, как умножаются две матрицы 4 х 4:
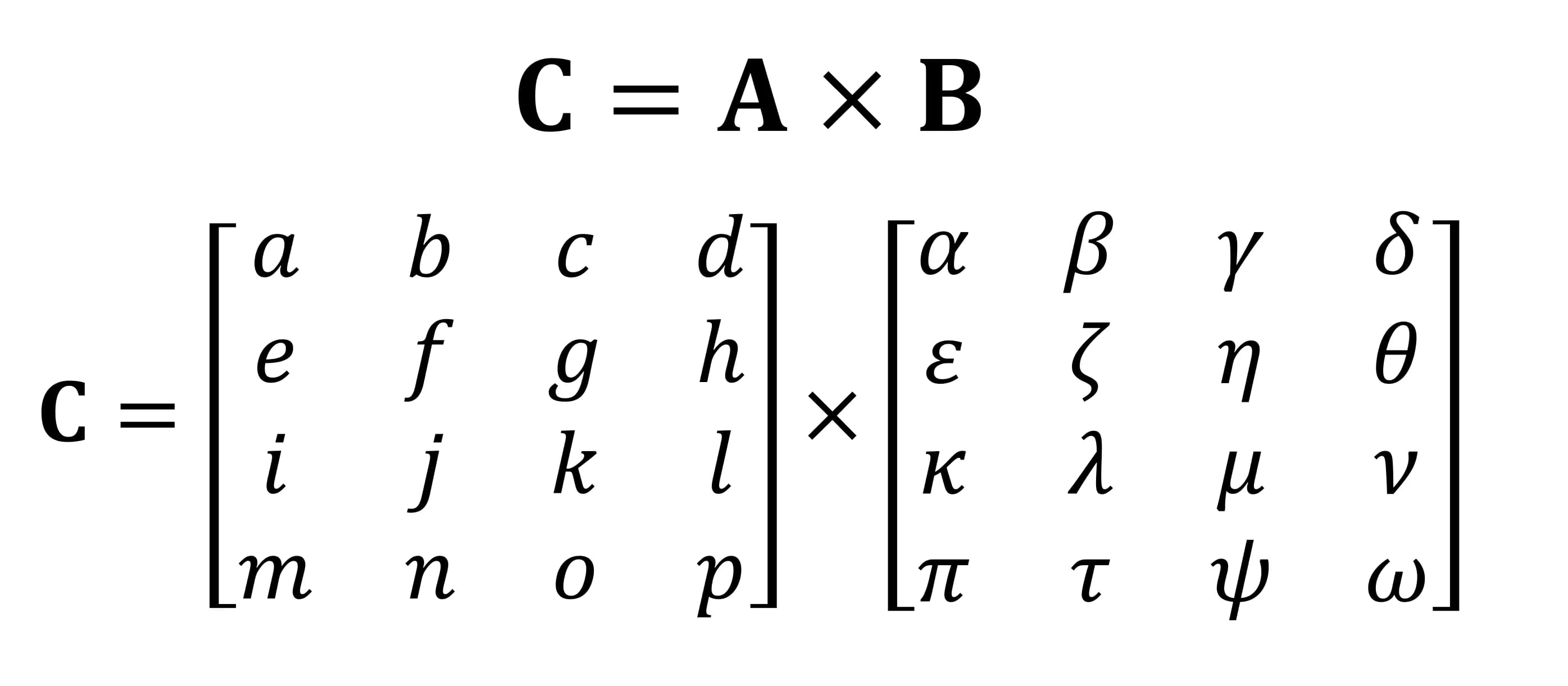
Источник: techspot.com
Результатом умножения всегда будет матрица с числом строк, равным числом строк в первой матрице, и числом столбцов, равным числу столбцов во второй. Итак, умножаем этих два массива:

Источник: techspot.com
Вам явно не хватит пальцев на руках и ногах, чтобы всё это посчитать
Как видите, «простое» вычисление произведения матриц состоит из множества умножений и сложений. Поскольку любой процессор, представленный сегодня на рынке, может выполнять обе эти операции, это означает, что любой настольный компьютер, ноутбук или планшет может обрабатывать базовые тензоры.
В то же время, приведенный выше пример содержит 64 умножения и 48 сложений; каждый промежуточный результат вычислений необходимо где-то хранить, прежде чем все их окончательно сложить между собой и, в конце концов, сохранить итоговый результат вычисления тензора. Таким образом, хоть умножение матриц и является математически простым, оно ресурсоёмко – необходимо использовать множество регистров, а кэш должен справляться с большим количеством операций чтения/записи.

Intel Sandy Bridge – первая архитектура, предлагающая расширение AVX
Процессоры AMD и Intel на протяжении многих лет предлагали различные расширения: MMX, SSE, а теперь AVX – все они являются SIMD (Single Instruction Multiple Data, «одиночный поток команд, множественный поток данных»), что позволяет процессору одновременно обрабатывать множество чисел с плавающей точкой – то есть именно то, что и нужно для умножения матриц.
Но есть особый тип процессора, специально разработанный для обработки SIMD-операций – да-да, это графический процессор (GPU).
Умнее, чем просто калькулятор
В мире графики огромное количество данных необходимо в одно и то же время передавать и обрабатывать в виде векторов. Возможность GPU выполнять такую параллельную обработку делает их идеальными для вычисления тензоров, и все они сегодня поддерживают GEMM (General Matrix Multiplication, подпрограмма умножения матриц).
Это алгоритм, при котором произведение двух матриц результируется третьей матрицей. На формат матриц, количество их строк и столбцов, накладываются жёсткие ограничения.
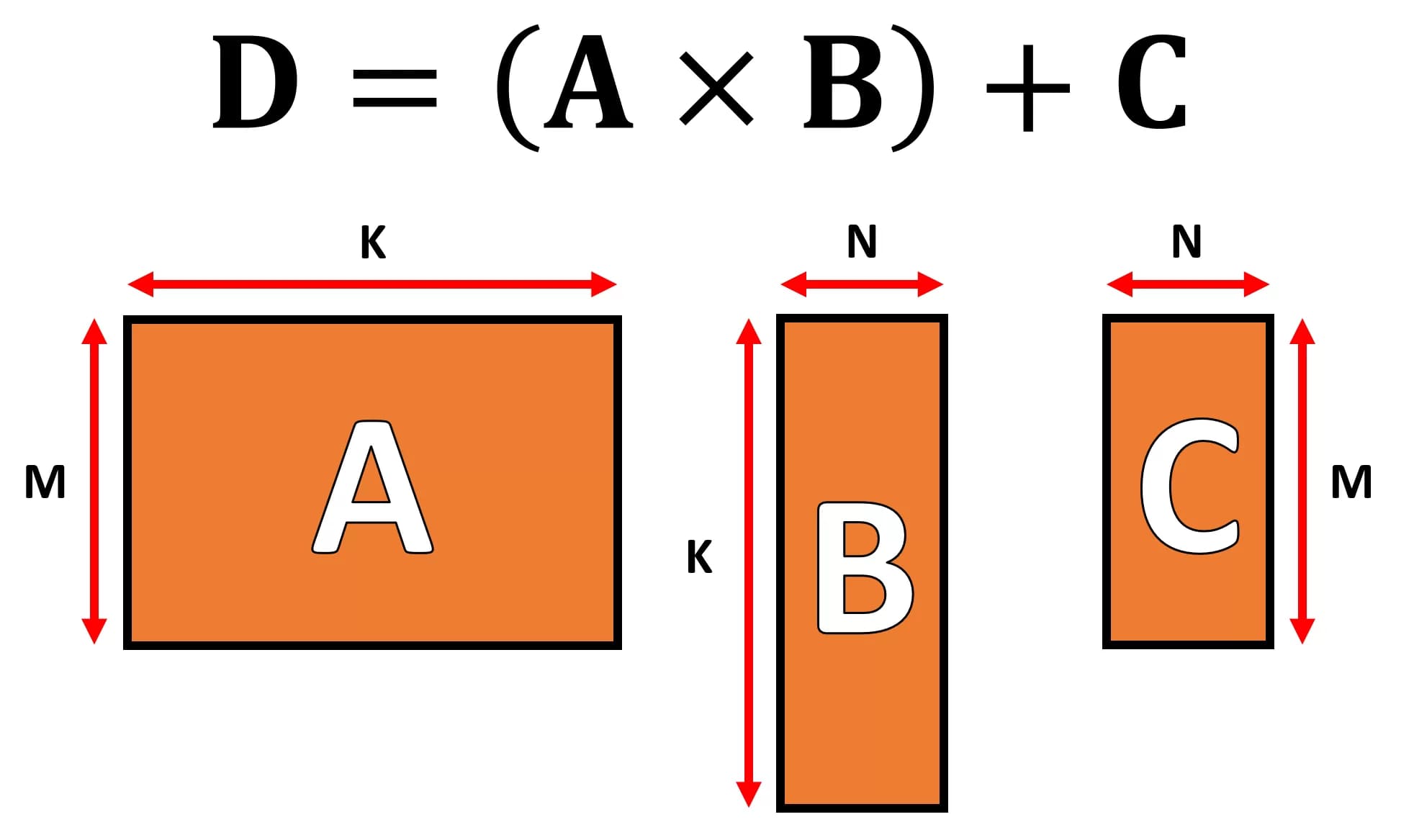
Источник: techspot.com
Требования GEMM для строк и столбцов: матрица A (MxK), матрица B (KxN), матрица C (MxN)
Алгоритмы, используемые для операций с матрицами, как правило, работают лучше, когда матрицы не очень большие и квадратные (например, массив 10 x 10 обработается легче, чем 50 x 2). Но в любом случае, лучше всего эти алгоритмы работают на специально заточенном для таких операций оборудовании.
В декабре 2017 года Nvidia выпустила видеокарту с GPU на новой архитектуре Volta. Она был ориентирована на профессиональные рынки, поэтому ни в одной из моделей GeForce этот чип
никогда не использовался. Особенностью его было то, что это был первый графический процессор, который имел ядра только для тензорных вычислений.

Видеокарта Nvidia Titan V с чипом GV100 Volta. Да, Crysis на ней пойдёт.
Заложен ли в названии архитектуры какой-то смысл – мы без понятия, но тензорные ядра в ней обрабатывали 64 GEMM за такт на матрицах 4 x 4, содержащих значения FP16 (16-битные числа с плавающей точкой) или умножение FP16 со сложением FP32. Такие тензоры очень маленькие, поэтому при обработке фактических множеств данных, ядра обрабатывают большие матрицы по частям, формируя окончательный результат.
Менее чем через год Nvidia представила архитектуру Turing. На этот раз тензорные ядра появились в потребительских моделях GeForce. Система была обновлена, и поддерживала уже больше форматов данных, такие как INT8 (8-битные целочисленные значения), но в остальном работала так же, как и Volta.

GPU Turing от Nvidia
В начале этого года в GPU для дата-центров A100 дебютировала архитектура Ampere, и на этот раз Nvidia улучшила производительность (256 GEMM за цикл вместо 64), добавила дополнительные форматы данных и возможность очень быстро обрабатывать разреженные тензоры (матрицы с большим количеством нулей).
Для программистов доступ к тензорным ядрам в любом из чипов Volta, Turing или Ampere прост: соответствующий флаг в коде сообщает API и драйверам, что вы хотите задействовать тензорные ядра; ядра должны поддерживать ваш тип данных, а размерность матриц должна быть кратна 8. При удовлетворении этих условий, всем остальным займётся оборудование.
Все это прекрасно, но насколько тензорные ядра обрабатывают GEMM лучше, чем обычные ядра GPU?
Когда Volta только появилась, портал Anandtech провёл сравнительный математический тест трёх карт: новой Volta, топовой Pascal и старой Maxwell.
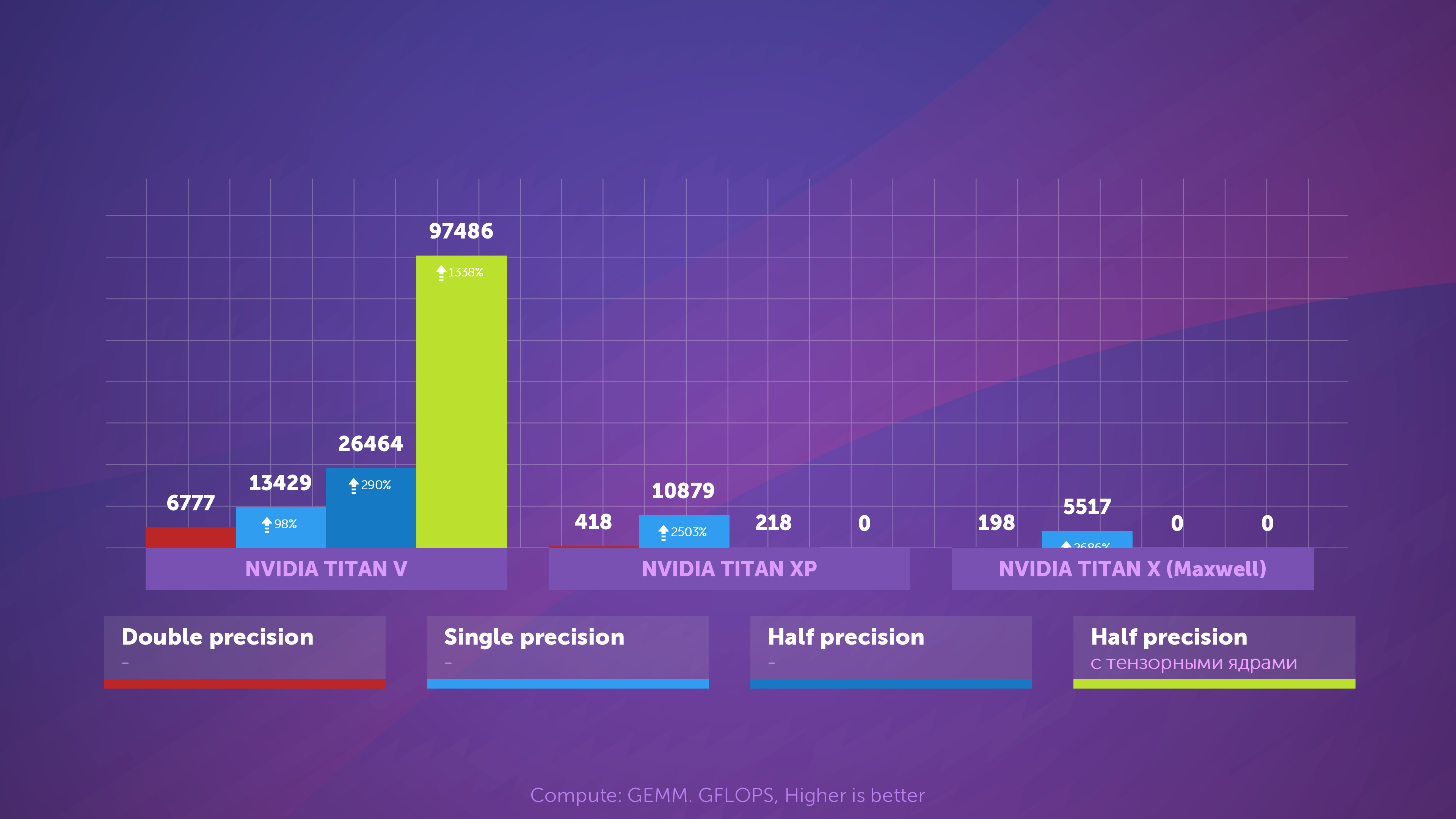
Понятие «точность» (precision) определяется количеством бит, используемых для чисел с плавающей точкой в матрицах: двойная (double) равно 64, одинарная (single) – 32 бита, и т.д. Горизонтальная шкала – шкала FLOPs, максимального количества операций с плавающей точкой в секунду (1 GEMM равен 3 FLOP).
Просто посмотрите, что получилось при использовании тензорных ядер вместо так называемых стандартных ядер CUDA! Они неоспоримо лучше справляются с подобными задачами, но в чём же их практическая польза?
Всё станет лучше с помощью математики
Тензорные вычисления крайне востребованы в физике и инженерии, с их помощью решаются различные сложные задачи в области механики жидкости, электромагнетизма или астрофизики,
но компьютеры, которые использовались для таких вычислений, обычно выполняли матричные операции с помощью больших процессорных кластеров.
Еще одна излюбленная область использования тензоров – это машинное обучение, особенно глубокое (deep machine learning). Это работа с громадными объёмами данных в гигантских массивах, называемых нейронными сетями. Связям между различными значениями данных присваивается определенный вес – число, выражающее значимость конкретной связи.
Источник: techspot.com
Поэтому, когда анализируется взаимодействие всех сотен или тысяч связей, каждый фрагмент данных в сети умножается на все возможные веса связей. Другими словами, происходит умножение двух матриц – а это классическая тензорная математика!

Чипы Google TPU 3.0 с водяным охлаждением
Именно поэтому все суперкомпьютеры для глубокого обучения оснащаются GPU, и почти всегда от Nvidia. Но некоторые компании пошли еще дальше, и создали свои собственные процессоры с тензорными ядрами. Так, например, Google в 2016 анонсировал свой первый TPU (Tensor Processing Unit, тензорный процессор), но эти чипы настолько узкоспециализированы, что кроме как выполнять операции с матрицами, больше ничего не умеют.
Тензорные ядра для обычных пользователей (GeForce RTX)
Но что, если я не астрофизик, озабоченный проблемой решения римановых многообразий, и даже не увлекаюсь экспериментами в глубинах сверхточных нейросетей? Мне какой толк от покупки GeForce RTX?
Может показаться, что вы зря потратили деньги на бесполезную функцию, поскольку тензорные ядра практически не используются для привычного рендеринга и кодирования/ декодирования видео. Однако в 2018 году Nvidia встроила тензорные ядра в свои потребительские продукты (Turing GeForce RTX), одновременно представив DLSS – Deep Learning Super Sampling.

Суть проста: кадр сперва рендерится на пониженном разрешении, а по окончании этого – разрешение увеличивается до исходного размера экрана монитора (например, сперва рендерится на 1080p, а затем изменяется до 1400p). Благодаря этому, повышается производительность, поскольку обрабатывается меньшее количество пикселов, при этом на экране всё равно получается отличная картинка.
Консоли уже многие годы практикуют нечто подобное, и многие современные PC-игры тоже обеспечивают такую возможность. В Assassin's Creed: Odyssey от Ubisoft вы можете изменить разрешение рендеринга до 50% от разрешения монитора. К сожалению, качество картинки ощутимо страдает. Вот так игра выглядит в 4K с максимальными настройками графики:

Источник: techspot.com
На высоких разрешениях текстуры выглядят намного лучше, поскольку сохраняют все мелкие детали. Но к сожалению, такое качество требует большого объёма обработки. Что произойдёт,
если игру настроить на рендеринг с разрешением 1080p (в 4 раза меньше пикселей на прорисовку), а затем увеличить до 4К с помощью шейдеров.

Источник: techspot.com
Из-за компрессии JPEG и масштабирования на сайте, разница в глаза может не броситься, но видно, что броня на персонаже и скала вдали несколько размыты. Внимательней посмотрим на увеличенный фрагмент:

Источник: techspot.com
Изображение слева отрендерено в 4K, а справа – в 1080p с последующим масштабированием до 4K. Разница становится более очевидной в движении, когда алгоритмы смягчения деталей быстро превращают всё в размытую кашу. Частично этого можно избежать с помощью повышения резкости в настройках видеокарты, но это совсем не то, чем бы нам хотелось заниматься.
Здесь и проявляет себя DLSS – Nvidia проанализировала несколько игр в первой версии этой технологии, используя разные разрешения, со сглаживанием и без него. Сгенерированные на разных режимах изображения были загружены в суперкомпьютеры компании, которые с помощью нейросетей искали наилучший вариант превращения изображения 1080p в идеальную картинку с высоким разрешением.

Источник: techspot.com
Стоит сказать, что DLSS 1.0 был не идеальным: детали часто терялись или мерцали в некоторых местах. К тому же, он не использовал тензорные ядра вашей видеокарты (это выполнялось сетью Nvidia), и каждая игра, поддерживающая DLSS, должна была быть проанализирована Nvidia для определения наилучшего алгоритма масштабирования для неё.
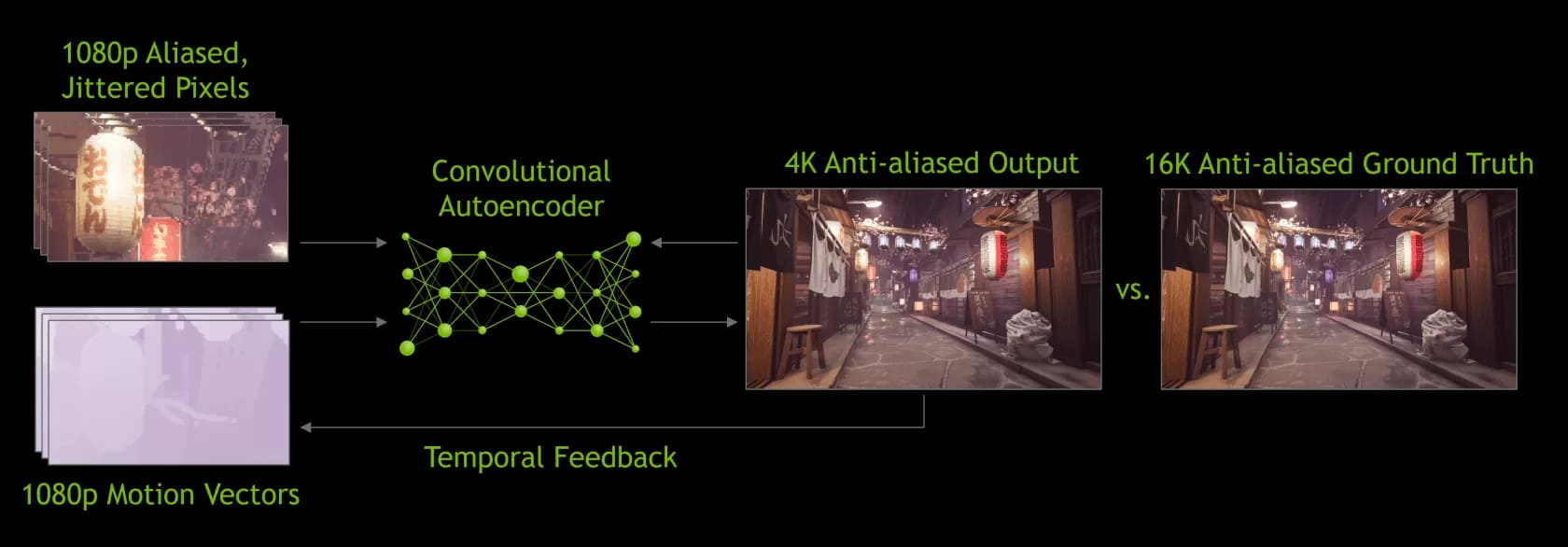
Источник: techspot.com
Когда в начале 2020 года вышла версия 2.0, в нее были внесены серьезные улучшения. Самым примечательным из них было то, что теперь суперкомпьютеры Nvidia использовались только для создания общего алгоритма масштабирования – в новой версии DLSS для обработки пикселей (тензорными ядрами вашего GPU) используются данные из отрендеренного кадра с применением нейронной модели.

Источник: techspot.com
Возможности DLSS 2.0 впечатляют, но пока что его поддерживает очень мало игр – на момент написания этой статьи их насчитывалось всего 12. Тем не менее, всё больше разработчиков стремятся реализовать его в своих проектах, и на то есть основания.
Любое масштабирование – это способ заметно повысить производительность, поэтому с полной уверенностью можно утверждать, что DLSS будет продолжать развиваться.
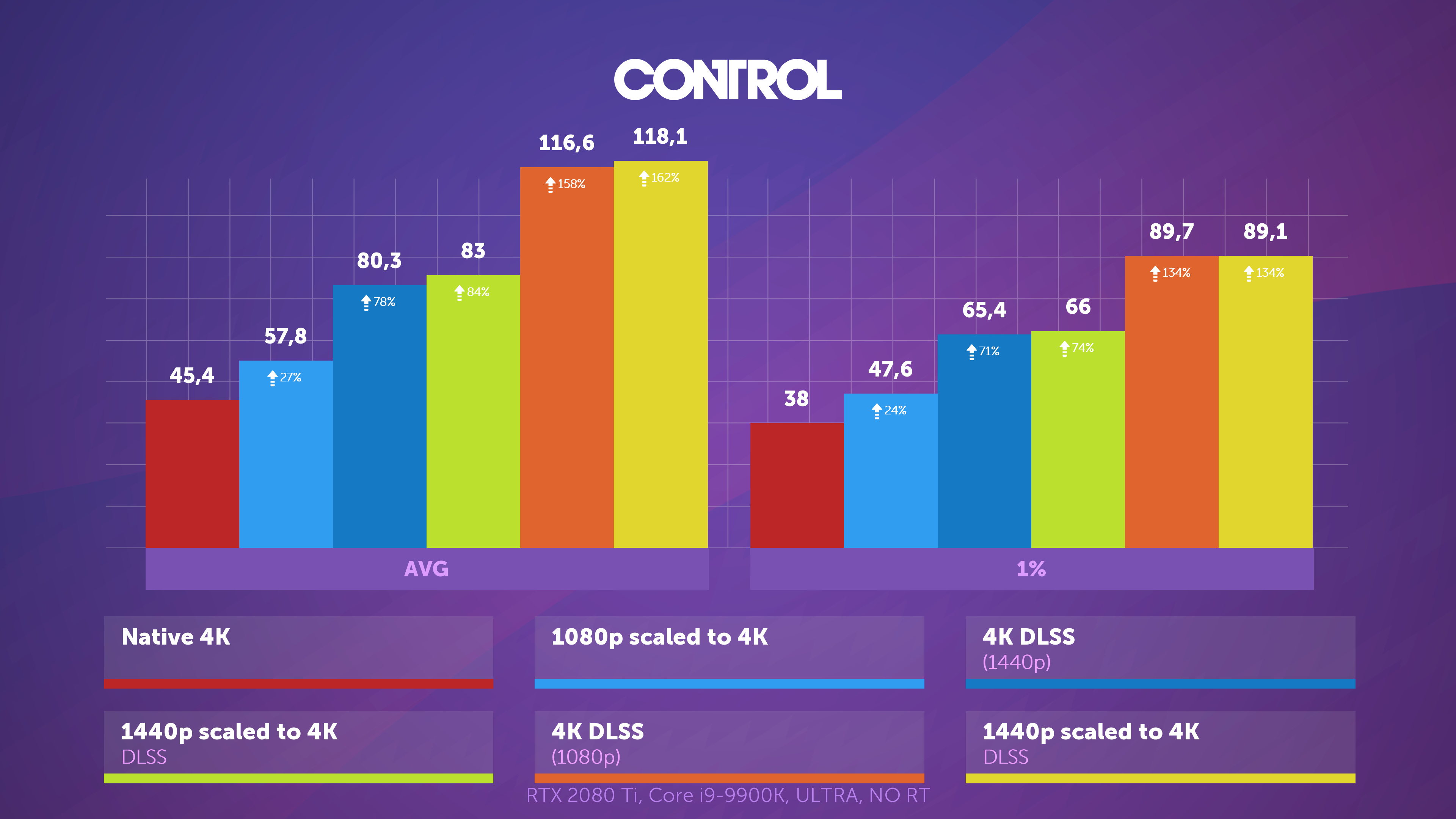
И хотя у DLSS имеются некоторые недочеты визуализации на выходе, высвободив занятые рендерингом ресурсы, разработчики могут добавлять больше эффектов или обеспечивать одинаковый уровень графики для более широкого диапазона платформ.
В частности, DLSS часто сопутствует с трассировкой лучей (ray tracing) в играх «с поддержкой RTX». Графические процессоры GeForce RTX содержат дополнительные вычислительные блоки, называемые RT-ядрами: особые логические блоки для ускорения вычислений пересечения «луч-треугольник» и обхода иерархии ограничивающих объемов (BVH, Bounding Volume Hierarchy). Эти два процесса занимают много времени для определения взаимодействия света с объектами сцены.
Поскольку трассировка лучей – процесс крайне трудоёмкий, разработчики вынуждены ограничивать число лучей и отражений в сцене, чтобы обеспечить приемлемый уровень игровой производительности. Кроме того, в результате этого процесса может появляться зернистость изображения, поэтому необходимо использовать алгоритм шумоподавления, что ещё более усложняет обработку. Ожидается, что тензорные ядра помогут повысить производительность с помощью шумоподавления на основе ИИ, но этому ещё предстоит материализоваться, поскольку большинство современных приложений по-прежнему используют для этих целей ядра CUDA. С другой стороны, имея DLSS 2.0 как перспективную технологию масштабирования, становится возможным эффективно использовать тензорные ядра для увеличения FPS после применения трассировки лучей к сцене.
Известны и другие планы относительно тензорных ядер в картах GeForce RTX, такие как улучшенная анимация персонажей или симуляция тканей. Но, как и в случае с DLSS 1.0, пройдет ещё немало времени, прежде чем появятся сотни игр, обыденно использующие специализированные матричные вычисления на GPU.
Начало весьма многообещающее
Итак, мы имеем – тензорные ядра, изящные аппаратные частицы, которые пока встречаются лишь в некоторых видеокартах потребительского уровня. Изменится ли что-то в будущем? Поскольку Nvidia уже значительно повысила производительность каждого тензорного ядра в своей новейшей архитектуре Ampere, есть большая вероятность, что мы увидим больше моделей с тензорными ядрами среднего и бюджетного ценового класса.
AMD и Intel пока вовсе не используют их в своих GPU, но возможно в будущем мы увидим их вариант реализации. У AMD есть система повышения резкости или улучшения деталей в готовых кадрах ценой небольшого снижения производительности, так что они вполне могут просто придерживаться этого пути – тем более, что разработчикам нет нужды в интеграции этой системы, она просто включается в драйверах.
Также существует мнение, что площадь кристалла GPU рациональней использовать просто под дополнительные шейдерные ядра, что Nvidia и сделала в бюджетных версиях чипов Turing. Вместо тензорных ядер в таких картах как GeForce GTX 1650 стоят дополнительные шейдеры FP16.
Пока же, если вы хотите воспользоваться всеми преимуществами сверхбыстрой GEMM-обработки, у вас есть два варианта: либо накупить себе кучу огромных многоядерных процессоров, либо купить всего один GPU с тензорными ядрами.