Что такое кэш? L1 vs L2 vs L3
В любом процессоре любого компьютера – от дешевого ноутбука до сервера в миллион долларов – есть то, что называется кэшем. И чаще всего он ещё и многоуровневый.
Должно быть, это что-то важное, иначе зачем бы это было? Но что оно делает, и зачем там несколько уровней? И что, вообще, значат всякие там множественно-ассоциативные 12-канальности?
Что же такое кэш?
Это небольшая, но очень быстрая память, которая находится рядом с логическими блоками процессора.
Но, конечно, такого определения нам недостаточно...
Представим себе идеальную волшебную систему хранения данных: бесконечно быструю, с бесконечным числом одновременных операций, и при этом обеспечивая абсолютную сохранность данных. Ничего подобного в реальности не существует, но если бы существовало, то устройство процессора было бы существенно проще.
Процессору было бы достаточно иметь только логические блоки для выполнения арифметических операций и систему для контроля передачи данных. Потому, что наша воображаемая система хранения мгновенно отправляет и получает все необходимые значения; ни один из логических блоков не задерживается в ожидании выполнения транзакции данных.
Но мы такими магическими технологиями хранения не обладаем. У нас есть лишь жесткие или твердотельные накопители, и даже лучшие из них не способны справиться с обработкой всех транзакций, необходимых для типичного процессора.
«Слон Мироздания» в мире хранения данных. Источник:
techspot.com
Причина в том, что современные процессоры невероятно быстры – им требуется всего один такт, чтобы сложить два 64-битных целых числа, а для процессора, работающего на частоте 4 ГГц, это занимает всего 0,00000000025 секунды (четверть наносекунды).
В то время как вращающимся жестким дискам требуются тысячи наносекунд только для того, чтобы найти данные на внутренних дисках, не говоря уже об их передаче. Твердотельные накопители работают быстрее, но и им требуются десятки или сотни наносекунд.
Понятно, что такие накопители нельзя встроить внутрь процессора, а это означает, что между ними будет физическое разделение и, следовательно, понадобится больше времени на перемещение данных, что еще больше усугубляет ситуацию.
К сожалению, мир хранения данных стоит скорее на «Великой Черепахе». Источник: techspot.com
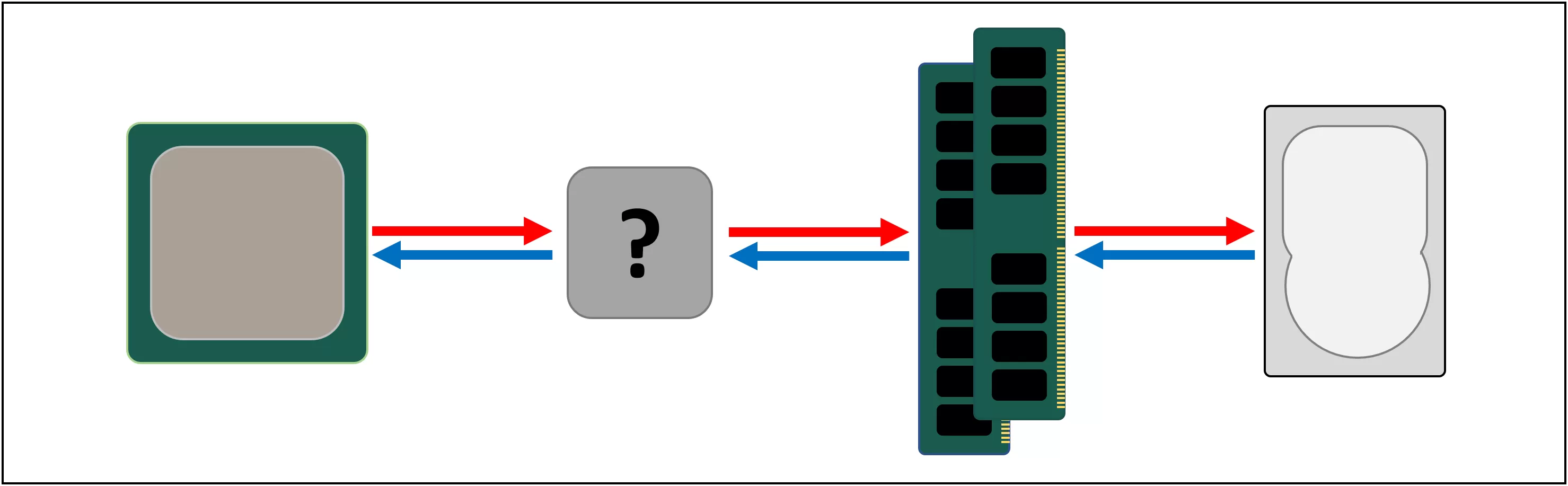
Итак, нам нужна еще одна система хранения данных, которая находилась бы между процессором и основным хранилищем. Она должна быть быстрее, чем диск, уметь обрабатывать большое количество транзакций одновременно и быть в непосредственной близости к процессору.
Что ж, у нас уже есть такая штука, и она называется RAM. Во всех компьютерах она используется как раз для этой цели.
Почти всегда это – DRAM (динамическая память с произвольным доступом), и она способна совершать обмен данными намного быстрее любого диска.
Источник: techspot.com
Однако, значительно превосходя в скорости, DRAM столь же значительно уступает в объёме хранимых данных.
Самые большие на сегодня чипы DDR4 (производства Micron, одного из немногих производителей DRAM) уступают самым большим по объёму жестким дискам примерно в 4000 раз.
Поэтому, увеличив скорость обмена данными, встала другая задача: с помощью аппаратных и программных решений определить, какие данные следует поместить в ограниченный объём DRAM, для оперативного пользования процессором.
Но по крайней мере, DRAM можно встроить в корпус процессора (встраиваемая DRAM, eDRAM). Однако процессоры относительно небольшие, поэтому особо внутри них не развернёшься.

10 Мб DRAM чип слева от графического процессора Xbox 360. Источник:
CPU Grave Yard
Подавляющее большинство модулей DRAM располагается на материнской плате рядом с процессором, и это всегда ближайший к процессору компонент в компьютерной системе. И всё равно это недостаточно быстро...
Опять же, для поиска данных DRAM требуется время около 100 наносекунд, но по крайней мере она может передавать миллиарды бит данных в секунду. Похоже, нам понадобится еще одна промежуточная память, между блоками процессора и DRAM.
Встречайте: SRAM (статическая память с произвольным доступом). В то время как DRAM использует микроскопические конденсаторы для хранения данных в виде электрического заряда, SRAM для той же цели использует транзисторы, работающие почти с той же скоростью, что и логические блоки в процессоре (примерно в 10 раз быстрее, чем DRAM).
Источник: techspot.com
Конечно, у SRAM есть недостаток, и опять же, речь об объёме.
Транзисторная память занимает намного больше физического места, чем DRAM: чип SRAM размером с чип DDR4 4 Гб будет иметь объём менее 100 Мб. Но поскольку технологически SRAM основана на том же процессе, что и процессор, то её можно встроить прямо внутрь него, в непосредственной близости к его логическим блокам.
Каждая такая дополнительная система памяти на пути к сверхбыстрым узлам процессора отличается повышенной скоростью в ущерб её объёму. Можно добавить больше таких систем, каждая из которых будет быстрее, но меньше.
И вот теперь мы можем дать более внятное определение, что такое кэш: это несколько модулей SRAM, расположенных внутри процессора. Они обеспечивают максимальную загрузку логических блоков, выполняя обмен данными на сверхвысоких скоростях. Этого достаточно? Отлично, потому что с этого момента все станет намного сложнее!
Кэш – это как многоуровневая парковка
Как мы выяснили, кэш необходим, потому что системы хранения данных неидеальны и не способны удовлетворить соответствующие требования логических блоков в процессоре. Современные CPU и GPU содержат массив блоков SRAM, которые внутренне организованы в иерархию – последовательность кэшей, упорядоченных следующим образом:
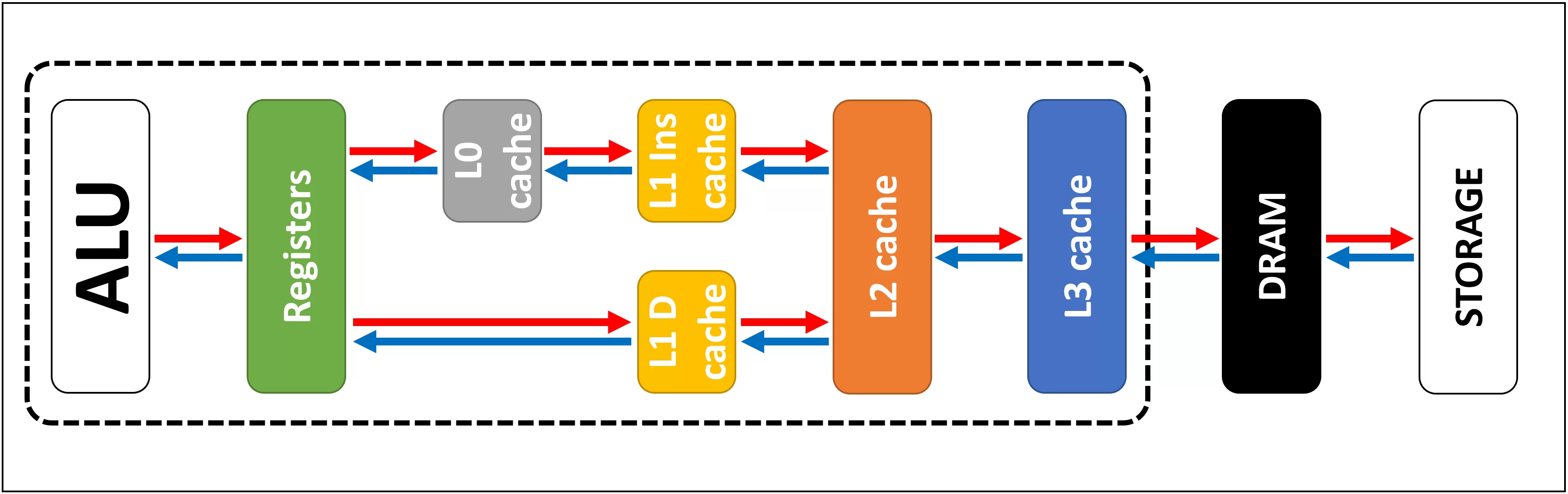
Источник: techspot.com
На этой схеме область процессора выделена черным пунктирным прямоугольником. Блоки ALU (арифметико-логическое устройство) находятся в крайнем левом углу; это те самые структуры, которые и делают процессор – процессором, выполняя математические вычисления. Ближайшим к ALU уровнем памяти являются регистры (они сгруппированы в файл регистров) – но технически они кэшем не являются.
Каждый из них содержит одно число, например 64-битное целое; само значение может быть фрагментом каких-то данных, кодом определенной инструкции, либо же ссылкой на адрес других данных.
Файл регистров в процессоре настольного компьютера довольно мал – например, в Intel Core i9-9900KF их на каждое ядро по два банка: один для целых чисел, содержащий 180 64-битных регистров, другой – для векторов (небольших массивов чисел), имеющий 168 256-битных регистров. Таким образом, общий файл регистров для каждого ядра чуть меньше 7 Кб. Для сравнения, размер файла регистров в потоковых мультипроцессорах (графических эквивалентах ядер CPU) в NVIDIA GeForce RTX 2080 Ti равен 256 Кб.
Регистры – это SRAM-память, как и кэш, но работающие на той же скорости, что и обслуживаемые ими ALU, вводя и выводя данные за один такт. Но они не предназначены для хранения большого количества данных (а только одного их фрагмента), поэтому поблизости всегда есть несколько блоков памяти побольше: это кэш уровня 1, L1 (Level 1).
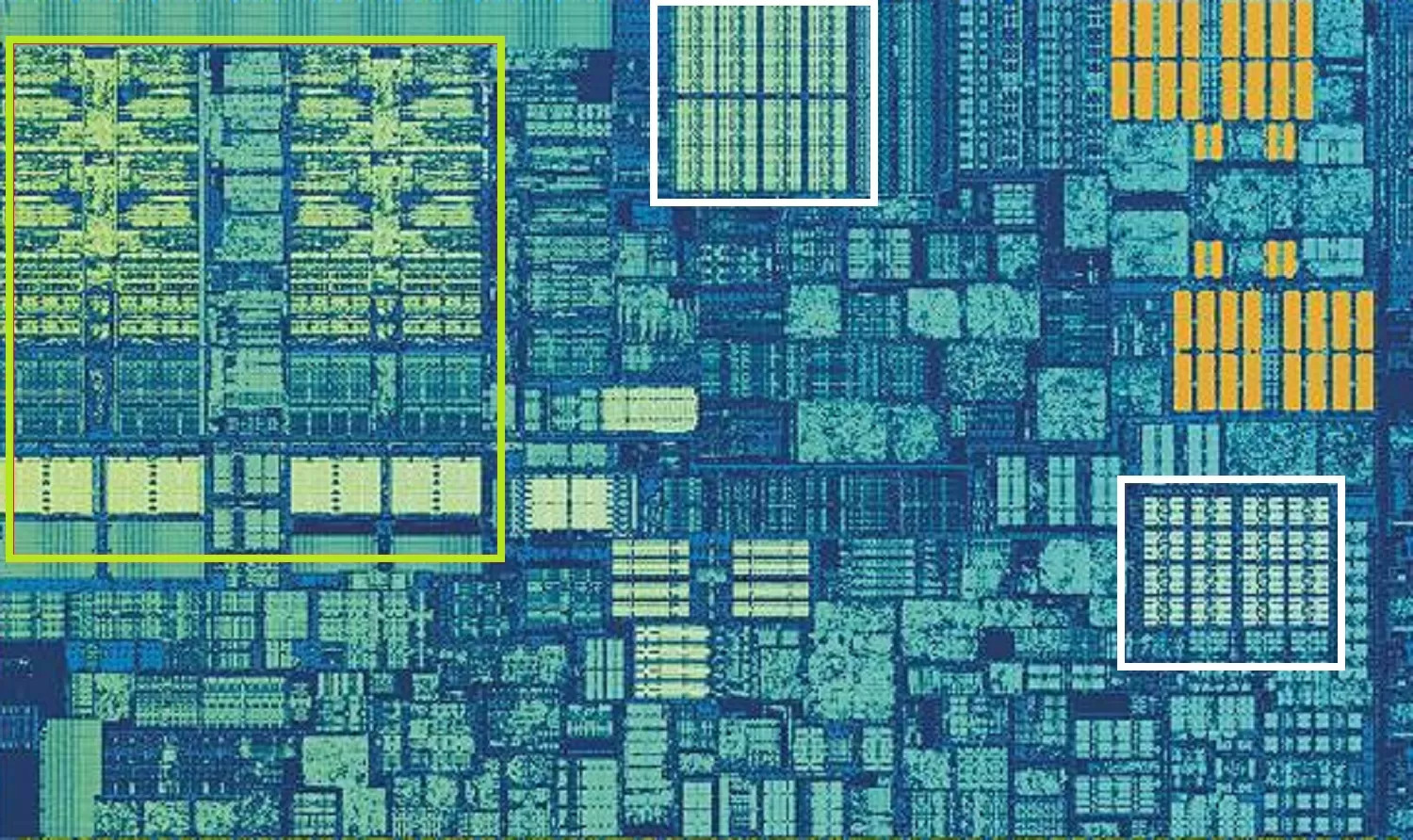
Процессор Intel Skylake, увеличенное изображение одного из ядер. Источник:
Wikichip
На фото крупным планом показано ядро процессора Intel Skylake для PC.
Зелёным прямоугольником слева выделены ALU и файлы регистров. В центре вверху белым прямоугольником показан кэш данных 1 уровня (L1 D cache). Его объём небольшой, всего 32 Кб, но, как и регистры, он находится очень близко к логическим блокам и работает с той же скоростью, что и они.
Второй белый прямоугольник – это кэш инструкций 1 уровня (L1 Ins cache), также размером 32 Кб. Как следует из названия, здесь хранятся различные команды, готовые к разделению на более мелкие – так называемые микрооперации (обычно обозначаемые как μops) для выполнения ALU. Для них также есть свой кэш – так сказать, кэш нулевого уровня (L0 cache), поскольку он меньше (всего на 1500 операций) и ближе, чем кэши L1.
Вы можете спросить: а почему эти блоки SRAM такие маленькие? Почему бы не увеличить их размер до мегабайта хотя бы? Во-первых, основные логические блоки процессора занимают в чипе такое же пространство, как и кэши данных и инструкций вместе взятые, поэтому увеличение размеров последних приведет и к существенному увеличению общего размера кристалла.
А во-вторых (и в-главных), причина, по которой они хранят всего несколько килобайт, заключается в том, что время, необходимое для поиска и извлечения данных, увеличивается по мере увеличения объёма памяти. Кэш L1 должен быть очень быстрым, поэтому необходим компромисс между размером и скоростью – в лучшем случае требуется около 5 тактовых циклов (чуть больше для значений с плавающей точкой), чтобы предоставить данные из этого кэша, готовые к использованию.
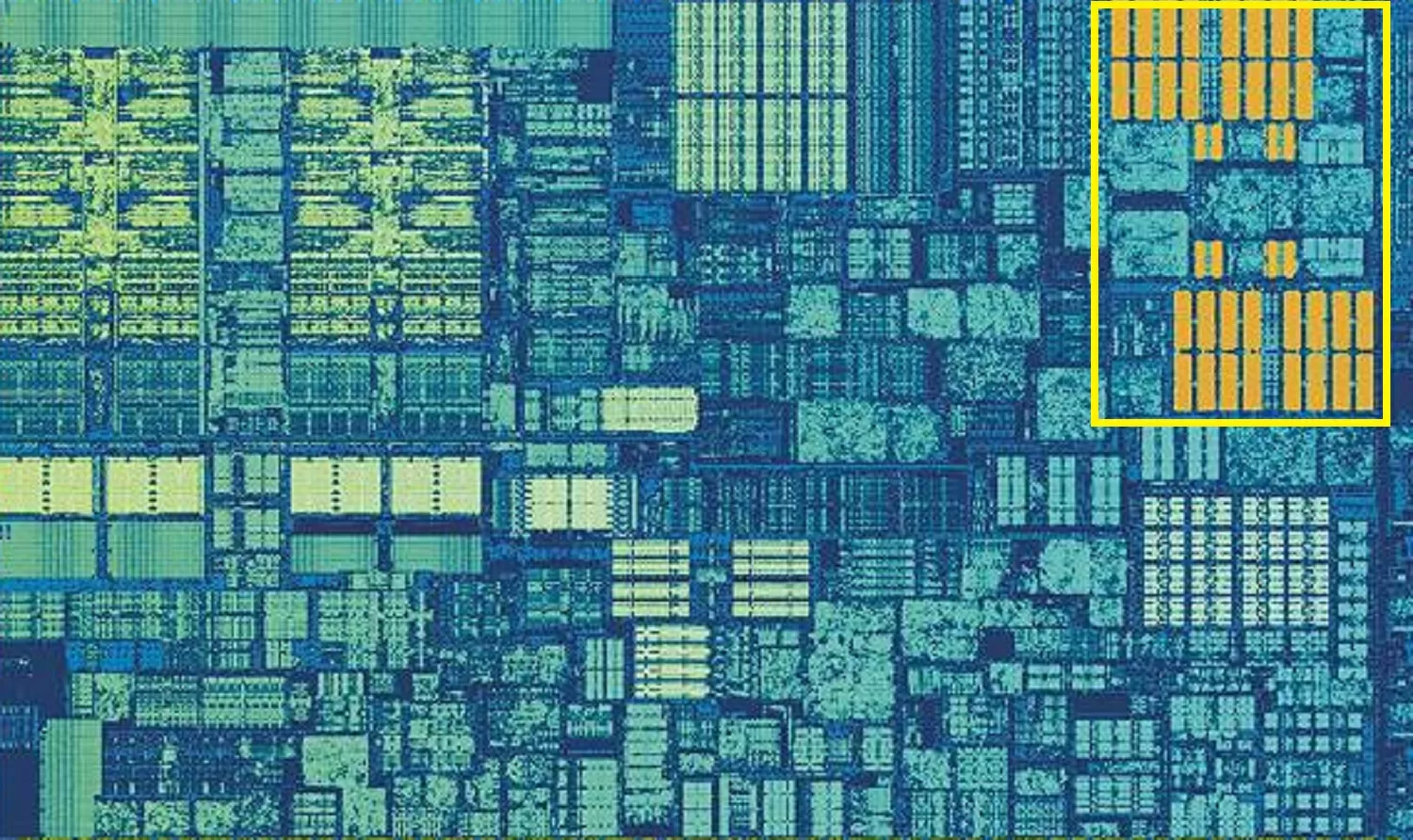
Кэш L2 в Skylake: 256 Кбайт удовольствия SRAM
Но если бы это был единственный кэш внутри процессора, то производительность последнего резко упала бы. Вот почему все процессоры имеют другой уровень памяти, встроенный в ядра: кэш 2 уровня, L2 (Level 2 cache). Это общее хранилище для инструкций и данных.
Его размер всегда несколько больше, чем L1: к примеру, в процессорах AMD Zen 2 устанавливается до 512 Кб памяти L2, поэтому кэши более низкого уровня обеспечиваются должным образом. Но за этот дополнительный размер приходится платить: на поиск и передачу данных из этого кэша уходит примерно вдвое больше времени по сравнению с L1.
Возвращаясь в прошлое, во времена оригинального Intel Pentium, кэш-память 2 уровня представляла собой отдельную микросхему – либо на небольшой съёмной плате расширения по подобию RAM DIMM, либо встроенную в материнскую плату. Затем кэш L2 переехал в сам корпус процессора, и в конечном итоге был интегрирован в кристалл, что стало причиной появления Pentium III и AMD K6-III.
За этим развитием вскоре последовал другой уровень кэш-памяти, предназначенный для поддержки более низких уровней, и это было связано с появлением многоядерных чипов.

Intel Kaby Lake. Источник:
Wikichip
На этой макрофотографии чипа Intel Kaby Lake мы видим его 4 ядра слева от центра (интегрированный GPU почти полностью занимает половину кристалла справа от центра). Каждое
ядро имеет свой собственный «личный» набор кэшей L1 и L2 (белые и желтый прямоугольники), но кроме этого имеет ещё и третий банк блоков SRAM (выделены красным).
Несмотря на то, что кэш 3 уровня (Level 3 cache) непосредственно окружает каждое ядро, он является общим для всех ядер – любое из ядер может свободно получать доступ к содержимому L3 другого ядра. Этот кэш-уровень намного больше (от 2 до 32 Мб), но и намного медленнее – в среднем на 30 циклов, особенно если ядру необходимо использовать данные, которые находятся в дальнем блоке кэша.
Ниже мы видим строение ядра в архитектуре AMD Zen 2: кэши данных и инструкций L1 (белым) объемом 32 Кб, L2 (жёлтым) – 512 Кб, и огромный блок кэша L3 (красным) размером 4 Мб.

Увеличенное изображение ядра процессора AMD Zen 2. Источник:
Fritzchens
Fritz
Постойте! Как 32 Кб могут занимать больше физического пространства, чем 512 Кб? Если L1 хранит так мало данных, почему он пропорционально значительно больше, чем кэши L2 и L3?
Больше, чем просто число
Кэш повышает производительность за счет ускорения передачи данных в логические блоки и хранения наготове часто используемых инструкций и данных. Информация, хранящаяся в кэше, делится на две части: сами данные и информация о том, где они изначально находились (в системной памяти или на носителе) – этот адрес называется тегом кэша.
Когда процессор выполняет операцию, которая собирается прочитать/записать данные из/в память, он начинает с проверки тегов в кэше L1. Если затребованные данные там присутствуют (cache hit, «кэш-попадание»), к ним можно сразу получить доступ напрямую. «Кэш-промах» (cache miss) происходит, когда кэш самого низкого уровня не содержит запрашиваемый тег.
В последнем случае, в кэше L1 создается новый тег, и соответствующие узлы архитектуры процессора начинают перебирать другие уровни кэша (вплоть до основного накопителя, если нужно), чтобы найти данные для затребованного тега. Но чтобы освободить место в кэше L1 для этого нового тега, нужно что-то оттуда выгрузить в L2.
В результате данные почти постоянно перемещаются и перемешиваются за считанные такты. Единственный способ управлять этим всем – оснастить сложной структурой обслуживания SRAM. Иными словами: если бы в ядре процессора был бы только один ALU, то кэш L1 был бы намного проще, но поскольку их десятки (многие из которых жонглируют двумя потоками инструкций), кэшу требуется сразу несколько подключений для поддержания кэшированных данных в движении.
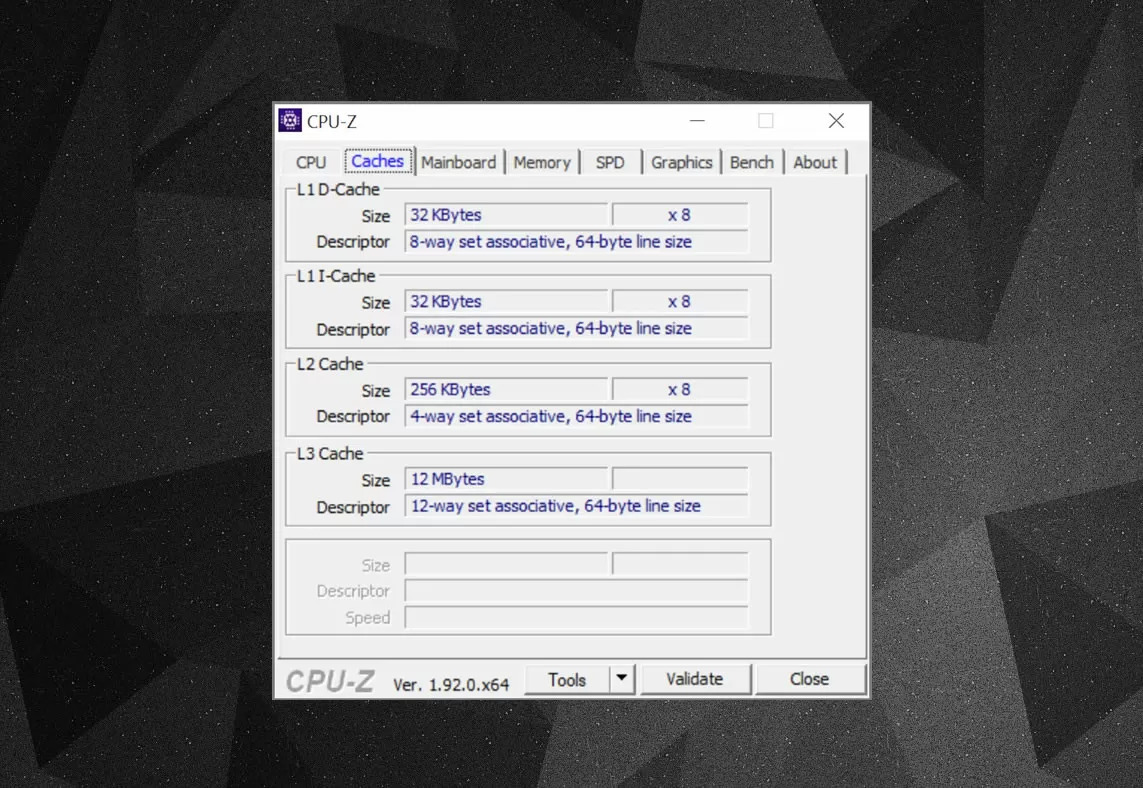
С помощью бесплатных утилит типа CPU-Z можно получить информацию о кэше в вашем процессоре. Что же мы там видим? Важным элементом является параметр ассоциативности (set associative) – он определяет, как именно блоки данных из системной памяти копируются в кэш.
В приведенном выше примере представлена информация о кэше процессора Intel Core i7-9700KF. Каждый из кэшей L1 разделен на 64 маленьких блока, называемых сэтами (set, “набор”), и каждый из них далее делится на кэш-линии (cache lines), размером 64 байта. «Set associative»
(множественно- или наборно-ассоциативный) означает, что блок данных из RAM отображается на кэш-линии одного конкретного сэта, а не где угодно.
«8-way» – означает 8-канальный, то есть каждый один блок может быть ассоциирован с восемью кэш-линиями в сэте. Чем выше уровень ассоциативности (т.е. чем больше каналов), тем выше количество кэш-попаданий при поиске процессором данных, и ниже негативный эффект от кэш-промахов. Недостатком является то, что это усложняет систему, увеличивает энергопотребление, а также может снизить производительность, поскольку обрабатывается больше кэш-линий на каждый блок данных.

Инклюзивный кэш L1+L2, жертвенный кэш L3, политика отложенной записи (write-back policies), ECC (корректор ошибок). Источник:
Fritzchens Fritz
Ещё одним аспектом организации кэша является то, как именно данные распределяются по разным уровням. Соответствующие правила устанавливаются так называемой политикой инклюзивности (inclusion policy). Например, процессоры Intel Core имеют полностью инклюзивный кэш L1+L3. Это означает, что одни и те же данные, например, в L1, могут находиться и в L3. Может показаться, что это лишь трата столь ценного пространства кэша, но преимущество состоит в том, что если процессор получает кэш-промах при поиске тега в низком уровне, ему не нужно искать его в более высоком уровне.
В тех же процессорах кэш L2 является не-инклюзивным: любые хранящиеся в нем данные не копируются на какой-либо другой уровень. Это экономит место, но приводит к тому, что системе памяти чипа приходится выполнять поиск по L3 (который всегда намного больше), чтобы найти требуемый тег. Подобным образом устроены и жертвенные кэши (victim cache), но они используются для хранения информации, вытесняемой с более низкого уровня – например, процессоры AMD Zen 2 используют L3 в качестве кэша жертв, который просто хранит данные, вытесненные из L2.
Существуют и другие политики для организации кеширования, например, регламентирующие запись данных в кэш и RAM. Это так называемые политики записи (write policies), и большинство современных процессоров используют кэши с отложенной записью (write-back); это означает, что когда данные записываются на уровень кэша, происходит задержка перед тем, как копия этих данных отправляется в RAM. По большей части эта пауза длится до тех пор, пока данные в кэше не будут замещены новыми данными – и только тогда происходит запись вытесняемых данных в RAM.

Видеокарта Nvidia GA100, оснащенная 20 Мб кэш-памяти L1 и 40 Мб L2.
При выборе объема, типа и политик кэш-памяти, разработчики процессоров стараются найти оптимальный баланс между повышением производительности процессора и увеличением необходимой площади кристалла с неминуемым усложнением системы. Если бы было возможно просто взять и сделать 1000-канальные полностью ассоциативные 20-мегабайтные кэши L1, и при этом их размер не был бы размером с Манхэттэн (и не потребляли бы такую же мощность), то у нас всех уже были бы компьютеры с такими процессорами!
За последние десять лет кэш L1 претерпел мало изменений, в то время как L3 продолжает увеличиваться. Десять лет назад, покупая Intel i7-980X за 999 долларов, вы получали 12 Мб L3. Сегодня же кэшем L3 объёмом 64 Мб снабжены процессоры стоимостью вдвое дешевле.
Итак, кэш – это абсолютно необходимые и совершенно потрясающие технологии. В данной статье мы не рассматривали другие типы кэшей в CPU и GPU (например, буфер ассоциативной трансляции – TLB, или текстурные кэши), но поскольку все они следуют той же логике и структуре уровней, как мы описали здесь, то вам, скорее всего, уже будет не так сложно разобраться с ними.
По материала techspot.com