Почему GPU - это новые Короли Кэша? Обосновано.

TL; DR: Почему GPU нарастили так много кэша?
Низкоуровневые кэши данных увеличились в размерах, потому что теперь GPU используют не только в графических, но и разных других приложениях. Для расширения своих возможностей в области вычислений общего назначения графические чипы требуют большего кэша. Это гарантирует, что ни одно математическое ядро не будет простаивать в ожидании данных.
Объем высокоуровневой кэш-памяти существенно увеличился, что позволило компенсировать снижение производительности DRAM по сравнению с ростом производительности процессора. Солидные L2 или L3 сокращают просадки кэш-памяти. Это также позволяет предотвратить бездействие ядер и минимизировать потребность в широких шинах памяти.
Кроме того, улучшения в техниках рендеринга, особенно трассировки лучей, предъявляют огромные требования к иерархии кэша GPU. Большие кэши последнего уровня играют важную роль в поддержании игровой производительности при использовании этих техник.
Кэш-курс 101
Чтобы рассмотреть тему кэша в полном объёме, сначала надо понять, что это такое и в чём его значимость. Всем процессорам требуется память для хранения обрабатываемых чисел и результатов вычислений. Им также нужны конкретные инструкции по задачам, например, какие вычисления выполнять. Данные инструкции хранятся и передаются в числовом виде.
Эту память обычно называют RAM ((Random Access Memmory) ОЗУ (оперативное запоминающее устройство). Каждое электронное устройство с процессором оснащено оперативной памятью. В течение нескольких десятилетий компьютеры использовали DRAM (буква «D» означает динамическое) в качестве временного хранилища данных, а дисковые накопители служили долгосрочным хранилищем.
С момента своего изобретения DRAM претерпела потрясающие улучшения, становясь со временем экспоненциально быстрее. То же самое касается и хранилищ данных, где когда-то доминировавшие, но медленные жёсткие диски были заменены на быстрые твёрдотельные накопители. Тем не менее, несмотря на эти достижения, оба типа памяти все еще чрезвычайно медленные по сравнению с тем, как быстро базовый процессор может выполнять один расчет.

В то время как чип может добавить два числа за несколько наносекунд, извлечение этих значений или сохранение результата может занять от сотен до тысяч наносекунд — даже при самой быстрой доступной памяти. Если бы не было способа обойти это, то ПК не были бы намного лучше, чем в 1970-х, даже если они имеют гораздо более высокую тактовую частоту.
К счастью, есть SRAM (Static RAM, статичная оперативная память), чтобы преодолеть этот разрыв. SRAM состоит из тех же транзисторов, что и процессоры, выполняющие вычисления. Это означает, что SRAM может быть интегрирована непосредственно в чип и работать со скоростью чипа. Его близость к логическим устройствам сокращает время извлечения или хранения данных до десятков наносекунд.
Недостатком SRAM является то, что расположение транзисторов, необходимых для одного бита памяти, наряду с другими необходимыми схемами занимает значительное пространство. Используя современные технологии производства, 64 МБ SRAM было бы примерно эквивалентно 2 ГБ DRAM.

Именно поэтому современные процессоры включают в себя различные блоки SRAM — некоторые из них мизерные, содержат только несколько бит, в то время как другие содержат несколько МБ. Эти более крупные блоки обходят медлительность DRAM, значительно повышая производительность чипа.
Эти типы памяти имеют разные названия в зависимости от их использования, но наиболее распространенным является «кэш». И здесь дискуссия становится немного сложнее.
Приветствуем иерархию!
Логические блоки внутри ядер процессора обычно работают с небольшими порциями данных. Получаемые инструкции и обрабатываемые ими числа редко превышают объём в 64 бита. Следовательно, самые маленькие блоки памяти SRAM, хранящие эти значения, имеют одинаковый размер и называются «регистрами».
Чтобы данные устройства не зависли, ожидая следующего набора команд или данных, микросхемы обычно получают эту информацию заранее и сохраняют часто выдаваемые. Данные размещаются в двух различных наборах SRAM, обычно называемых Level 1 Instruction и Level 1 Data Cache. Как следует из названий, каждый из них имеет определенный тип данных, которые он содержит. Несмотря на их важность, они не экспансивны. Например, современные процессоры AMD для настольных компьютеров выделяют 32 КБ для каждого.
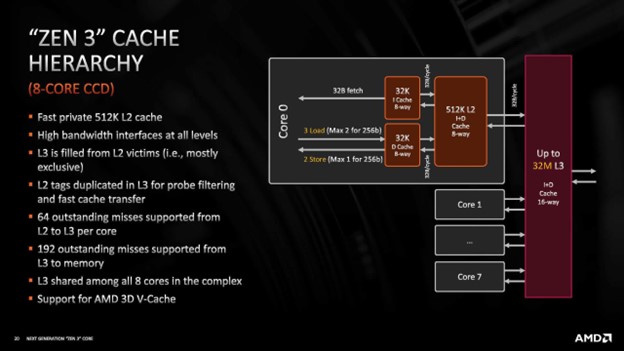
Несмотря на небольшой размер, этих кэшей вполне достаточно для хранения большого количества команд и данных, благодаря чему ядра не простаивают в режиме ожидания. Однако для поддержания данного потока данных доступность кэша должна быть непрерывна. Когда для ядра требуется определенное значение, отсутствующее в кэш-памяти 1 уровня (L1), кэш-память 2 уровня (L2) становится критичной.
L2 кэш представляет собой гораздо более крупный блок, в котором хранится разнообразный набор данных. Запомним, что одно ядро имеет несколько логических каналов. Без кэша L2, L1 кэш был бы быстро переполнен. Современные процессоры имеют несколько ядер, что приводит к появлению еще одного уровня кэш-памяти, обслуживающего все ядра: кэш L3. Она еще более обширна и занимает несколько МБ. Для справки: некоторые процессоры даже имели четвёртый уровень.

На рисунке выше изображено P-ядро одного из процессоров Intel Raptor Lake. Множество сеток в бледно-голубой пунктирной зоне является соединением регистров и различных кэшей. Однако, по существу, кэш L1 расположен в центре ядра, в то время как L2 преимущественно в правой части.
Последний уровень кэш-памяти в процессорах часто выступает в качестве первого порта вызова для данных, поступающих из системной DRAM, прежде чем они будут переданы дальше, но это не всегда так. Это та часть кэша, которая имеет тенденцию становиться очень сложной, но она также имеет решающее значение для понимания того, почему CPU и GPU имеют очень разные схемы расположения кэша.
Способ использования всей системы блоков SRAM известен как иерархия кэша чипа, и он сильно различается в зависимости от таких факторов, как покоение архитектуры и на какой сектор ориентирован чип. Но для CPU есть некоторые аспекты, которые всегда одинаковы, одним из которых является согласованность иерархии.
Данные в кэше могут быть скопированы из DRAM системы. Если ядро изменяет их, обязательно одновременно обновляется версия DRAM. В результате структуры кэша CPU обладают механизмами, обеспечивающими точность и своевременное обновление данных. Эта замысловатая конструкция усложняет процессор, а для процессоров сложность выражается в транзисторах, а следовательно, и в пространстве.
Вот почему первые несколько уровней кэш-памяти не очень большие - не только потому, что память SRAM занимает достаточно места, но и из-за всех дополнительных систем, необходимых для сохранения ее последовательности. Однако это нужно не каждому процессору, и есть один очень специфический тип, который вообще её не использует.
Ядра поверх кэша. Метод GPU
Современные графические чипы, в плане внутреннего устройства и функциональности, начали свой путь в 2007 году. Тогда Nvidia и ATI выпустили свои унифицированные шейдерные GPU, но существенные перемены у ATI случились пятью годами позднее.
В 2012 году AMD (которая поглотила к тому времени ATI) обнародовала свою архитектуру Graphics Core Next (GCN). Её дизайн применяют и сегодня, хотя он претерпел значительные изменения и превратился в такие формы, как RDNA и CDNA. Наглядно различия в кэше между CPU и GPU можно рассмотреть на примере GCN.

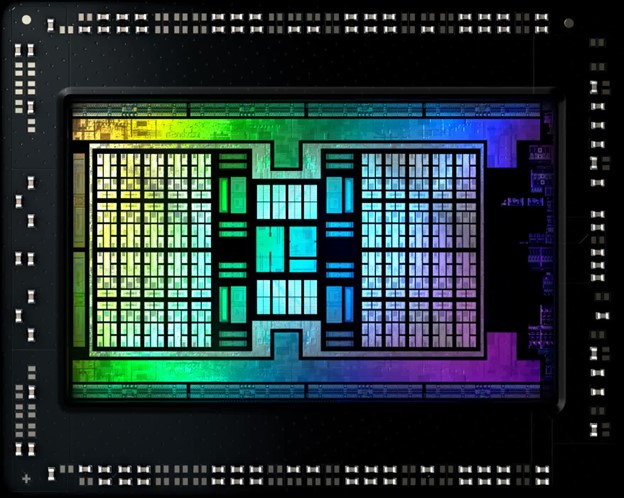
Возвращаясь в 2017 год, сравним AMD-шные CPU Ryzen 7 1800X (вверху) с GPU Radeon RX Vega 64. В первом находятся 8 ядер, каждое из которых содержит 8 магистралей. Четыре из этих магистралей выполняют стандартные математические операции, две специализируются на обширных вычислениях с плавающей запятой, а две последних контролируют управление данными. Иерархия кэша процессора структурирована следующим образом: 64 КБ инструкций L1, 32 КБ данных L1, 512 КБ L2 и 16 МБ L3.
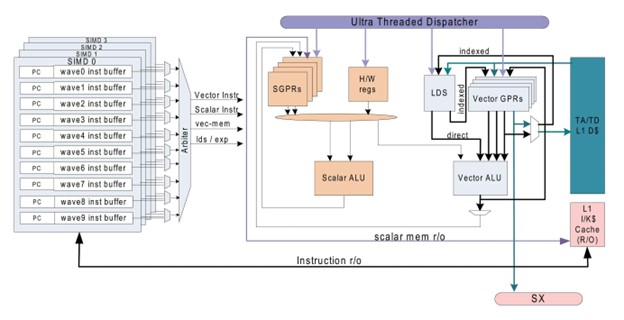
GPU Vega 64 имеет 4 блока обработки. Каждый из данных блоков содержит 64 магистрали, чаще называемых вычислительными блоками (CU). Кроме того, каждый CU вмещает четыре набора по 16 логических блоков. Каждый CU обладает 16 КБ кэша данных L1 и 64 КБ оперативной памяти, которые, по существу, функционируют как кэш без механизмов когерентности (AMD называет это Local Data Share).
Кроме того, есть еще два кэша (16 КБ инструкций L1 и 32 КБ данных L1), которые обслуживают группы из четырех CU. GPU Vega также может похвастаться 4 МБ кэш-памяти L2, расположенной в двух полосах: одна в основании, а другая ближе к верхней части изображения ниже.

Этот конкретный GPU в два раза превышает размер чипа Ryzen с точки зрения площади матрицы. Однако его кэш занимает значительно меньше места, чем кэш CPU. Почему этот GPU поддерживает минимальный кэш, особенно в сегменте L2, по сравнению с CPU?
Учитывая значительно большее количество «ядер» по сравнению с чипом Ryzen, можно было бы ожидать, что при общем количестве математических блоков в 4096 для поддержания стабильной подачи данных потребуется значительный объём кэша. Однако рабочие нагрузки CPU и GPU существенно различаются.
В то время как чип Ryzen может управлять до 16 потоков одновременно и обрабатывать 16 различных команд, процессор Vega может обрабатывать большее количество потоков, но его CU обычно выполняют идентичные инструкции.
Более того, математические блоки внутри каждого CU синхронно выполняют идентичные вычисления в течение цикла. Такое единообразие классифицирует их как устройства SIMT (single instruction, multiple threads -одна инструкция, несколько потоков). GPU работают последовательно, редко отклоняясь к альтернативным маршрутам обработки.
Если провести параллель, то CPU обрабатывает разнообразный набор инструкций, обеспечивая при этом согласованность данных. GPU, напротив, постоянно выполняет аналогичные задачи, устраняя необходимость в согласованности данных и постоянно перезапуская свои операции.
Поскольку задача рендеринга 3D-графики состоит в основном из повторяющихся математических операций, GPU не обязательно должен быть таким же сложным, как CPU. Вместо этого GPU предназначены для массовой параллельной обработки тысяч точек данных одновременно. Вот почему у них меньшего размера кэши, но гораздо больше ядер по сравнению с CPU.
Однако если это так, то почему новейшие видеокарты AMD и Nvidia имеют огромный объем кэша, даже в бюджетных моделях? Radeon RX 7600 содержит всего 2 МБ L2, но также несёт 32 МБ L3; GeForce RTX 4060 от Nvidia не имеет L3, но идёт с 24 МБ L2.
А когда дело доходит до передовых продуктов, цифры становятся гигантскими: GeForce RTX 4090 может похвастаться 72 МБ L2, а чип AMD Navi 21 (на картинке ниже) в картах Radeon RX 6800/6900 — со 128 МБ L3!
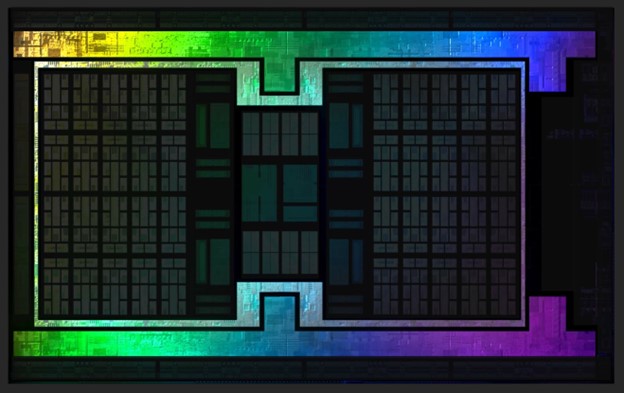
Здесь есть что раскрыть. Например, почему AMD так долго держала кэши такими маленькими, но затем внезапно увеличила их размер и добавила огромное количество L3 для пущей убедительности?
Почему Nvidia так сильно увеличила размеры L1, но сохранила L2 относительно небольшим только для того, чтобы скопировать AMD и свести с ума L2 кэш?
"G" в графическом процессоре — это уже не просто графика
Есть много причин для этой трансформации, но для Nvidia этот сдвиг был вызван изменениями в использовании её GPU. Хотя они и называются графическими процессорами, данные чипы были созданы для гораздо большего, чем просто отображение впечатляющих изображений на экранах.
Хотя подавляющее большинство GPU превосходно справляются с этой функцией, чипы вышли за рамки рендеринга. Теперь они несут математические нагрузки при обработке данных и научных алгоритмах в широком спектре дисциплин, включая инженерное дело, физику, химию, биологию, медицину, экономику и географию. Причина? Потому что они исключительно хороши в выполнении одних и тех же вычислений с тысячами точек данных одновременно.
Хотя CPU также могут выполнять эту функцию, для определенных задач один GPU может быть столь же эффективным, как несколько CPU. Поскольку GPU от Nvidia становятся более универсальными, количество логических блоков внутри чипа и их рабочие скорости демонстрируют экспоненциальный рост.

Дебют Nvidia в сфере серьезных вычислений общего назначения ознаменовался выпуском Tesla C870 в 2007 году. Архитектура этой карты, имеющая всего два уровня в иерархии кэша, гарантировала, что кэши L1 были достаточно обширными для непрерывной передачи данных всем устройствам. Этому способствовала еще более быстрая VRAM. Кэш L2 также увеличился в размерах, хотя и не так, как мы видим сейчас.
Первые GPU Nvidia с унифицированными шейдерами обходились всего 16 КБ данных L1 (и небольшим объемом для инструкций и других значений), но за пару лет этот объем подскочил до 64 КБ. В двух последних архитектурах чипы GeForce имели 128 КБ L1, а процессоры серверного уровня — еще больше.
Кэш L1 в тех первых чипах должен был обслуживать всего 10 логических блоков (8 общего назначения + 2 блока специальных функции). К моменту появления архитектуры Pascal (примерно в ту же эпоху, что и AMD RX Vega 64) размер кэша вырос до 96 КБ для более чем 150 логических блоков.
Разумеется, этот кэш получает данные из L2, и поскольку количество кластеров этих устройств увеличивалось с каждым поколением, увеличивался и объем кэша L2. Однако с 2012 года объем L2 на логический кластер (более известный как потоковый мультипроцессор, SM) остался относительно неизменным — порядка 70–130 МБ. Исключением, конечно, является новейшая архитектура Ada Lovelace.

В течение многих лет основное внимание AMD уделялось CPU, а графический отдел был относительно небольшим – с точки зрения персонала и бюджета. Однако в качестве основного дизайна GCN работал очень хорошо, найдя применение в ПК, консолях, ноутбуках, рабочих станциях и серверах.
Хотя, возможно, это не всегда был самый быстрый GPU, который можно было купить, графические процессоры AMD были более чем добротными, и структура кэша этих чипов, похоже, не нуждалась в серьезном обновлении. Но, в то время как CPU и GPU росли семимильными шагами, была еще одна часть головоломки, которую оказалось гораздо труднее улучшить.
DRAM натягивает свои каблучки
Преемницей GCN стала архитектура RDNA 2019 года, для которой AMD все перестроила так, чтобы их новые GPU использовали три уровня кэша, сохраняя при этом их относительно небольшой размер. Затем (для своего следующего проекта RDNA 2) AMD использовала свой опыт в разработке кэша CPU, чтобы внедрить в матрицу четвертый уровень кэша – тот, который был намного больше, чем всё, что было в GPU до этого момента.
Но зачем вносить такие изменения, особенно если эти чипы были в первую очередь предназначены для игр, а кэши GCN за прошедшие годы претерпели минимальные изменения?
Причины наглядно:
Размер и сложность чипа. Хотя включение большего количества уровней кэша усложняет конструкцию чипа, оно предотвращает чрезмерное увеличение площади чипа. Меньший размер чипа означает, что из одной кремниевой пластины можно изготовить больше единиц, что делает их производство более рентабельным.

Скорость памяти в сравнении со скоростью процессора.
Скорость процессора постоянно растет на протяжении многих лет, но DRAM не соответствует этим темпам. Например, в Radeon RX Vega 64 AMD использовала память с высокой пропускной способностью (HBM) для повышения скорости передачи данных между VRAM и GPU. Эти модули, показанные выше слева от основной матрицы GPU, по сути, представляют собой несколько матриц DRAM, сложенных вместе, что позволяет считывать или записывать больше данных за цикл. Однако HBM ощутимо дорогой. В идеале видеокарты должны иметь достаточно памяти, множество шин, работающих на высоких скоростях. Но из-за конструкции DRAM её производительность не могла быть повышена до уровня CPU или GPU.
Когда данные, необходимые для вычислений, отсутствуют в кэшах (что обычно называют «потерей кэша»), их необходимо извлечь из VRAM. Поскольку этот процесс медленнее, чем извлечение из кэша, ожидание данных, хранящихся в DRAM, просто приводит к остановке потока, которому они нужны. Такой сценарий часто развивается даже с современными графическими чипами.
На самом деле это происходит постоянно, даже с новейшими графическими чипами, но по мере того, как они становились всё более мощными, потери в кэше становились существенным ограничением производительности при высоких разрешениях.
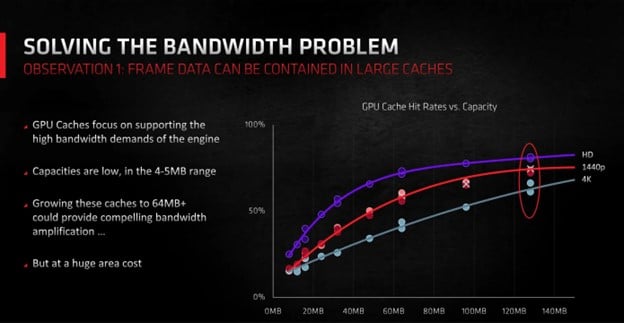
В GPU кэши последнего уровня структурированы таким образом, что интерфейс каждого модуля VRAM имеет свой выделенный фрагмент SRAM. Остальной процессор задействует систему перекрестных соединений для доступа к любому модулю. В GCN и первых разработках RDNA AMD обычно использовала фрагменты L3 размером 256 или 512 КБ. Но с появлением RDNA 2 этот показатель вырос до впечатляющих 16–32 МБ на фрагмент.
Это улучшение не только существенно снизила задержки потоков, вызванные чтением DRAM, но также уменьшила потребность в сверхширокой шине памяти. Более широкая шина требует более обширного периметра матицы GPU для размещения всех интерфейсов памяти.
В то время как массивные кэши могут быть громоздкими и медленными из-за присущих им больших задержек, дизайн AMD был противоположным: огромный кэш L3 позволял чипам RDNA 2 иметь производительность, эквивалентную той, которая была бы у них с более широкими шинами памяти, и всё это при удержании под контролем размеров матрицы.
Nvidia последовала этому примеру, выпустив последнее поколение Ada Lovelace. По тем же причинам предыдущий дизайн Ampere имел максимальный размер кэша L2 6 МБ в своем крупнейшем GPU потребительского уровня, но в новом дизайне он был значительно увеличен. Полная матрица AD102, урезанная версия которой используется в RTX 4090, содержит 96 МБ кэш-памяти второго уровня.

Что касается того, почему они просто не выбрали другой уровень кэша и не сделали его чрезвычайно большим, возможно, это связано с отсутствием такого же уровня знаний в этой области, как у AMD, или с нежеланием создать впечатление, что они напрямую копируют конкурента.
Если посмотреть на матрицу, показанную выше, то весь этот кэш L2 на самом деле не занимает много места на ней.
Помимо роста количества вычислений общего назначения на GPU, есть еще одна причина, по которой кэш последнего уровня теперь настолько велик, и она напрямую связана с последней горячей темой в рендеринге: трассировкой лучей.
Большая графика требует больших данных
Не вдаваясь сильно в детали самого процесса, трассировка лучей, используемая в современных играх, например, включает в себя выполнение казалось бы достаточно простых алгоритмов - провести линию от положения камеры в трехмерном мире через один пиксель кадра и проследить ее путь в пространстве. Когда она взаимодействует с объектом, проверить, что это такое и видим ли он, а затем решить, каким цветом сделать пиксель.
За этим стоит нечто большее, но в своей основе процесс такой. Одним из аспектов, которые делают трассировку лучей столь требовательной, является проверка объектов. Определение всех деталей объекта, которого достиг луч, является колоссальной задачей, поэтому для ускорения процедуры используется так называемая иерархия ограничивающих объёмов (сокращенно BVH).
Это можно представить как большую базу данных всех объектов, которые используются в 3D-сцене: каждая запись не только предоставляет информацию о том, чем является структура, но и как она связана с другими объектами. Чрезвычайно упрощенный пример:
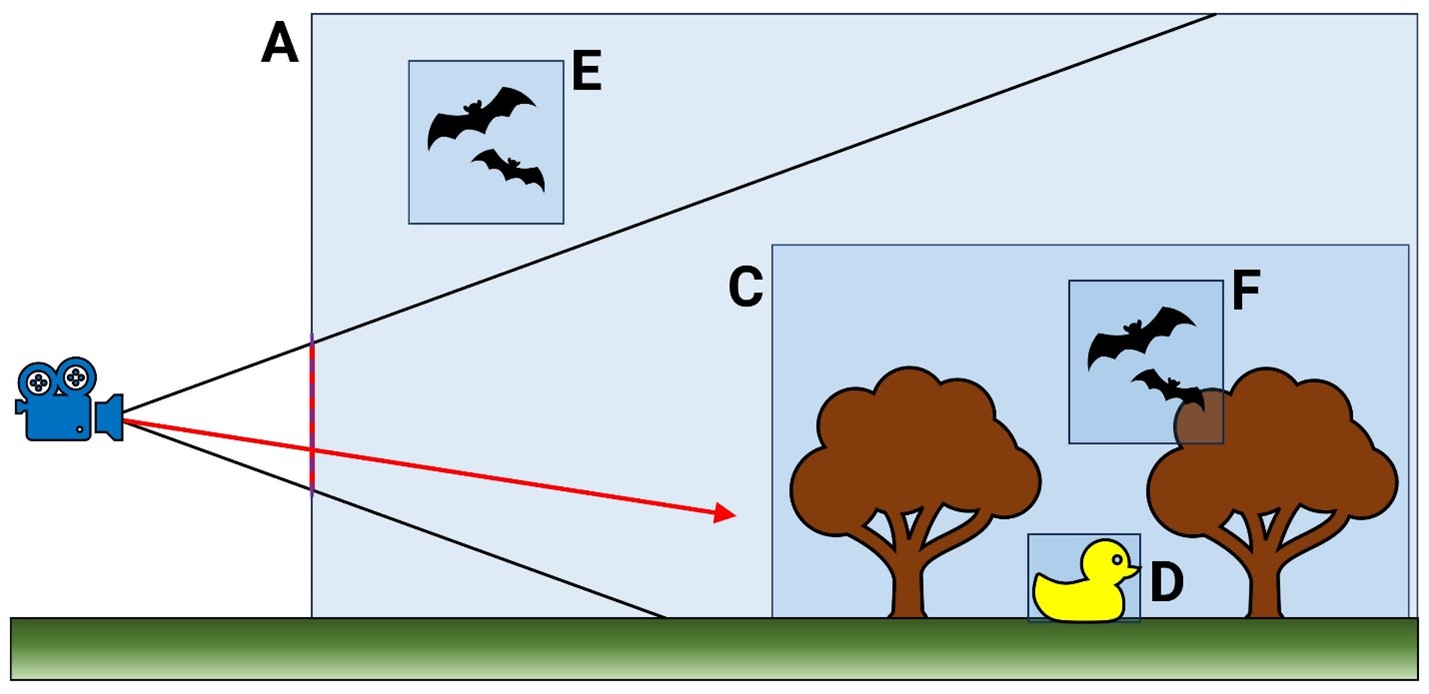
Вершина иерархии начинается с объёма A. Все остальное содержится внутри него, но обратите внимание, что объём E находится за пределами объёма C, который сам содержит D и F. Когда в эту сцену попадает луч (красная стрелка), происходит процесс обхода иерархии, проверяющий через какие объёмы проходит путь луча.
Однако BVH устроен как дерево и обход должен идти только по ветвям, где проверка приводит к попаданию. Поэтому объём Е можно сразу отбросить, так как он не является частью С, через которую явно пройдет луч. Конечно, сущность BVH в современной игре гораздо сложнее.

Для изображения выше из Cyberpunk 2077 приостановили рендеринг игры в середине кадра, чтобы показать, как любая конкретная сцена строится посредством увеличения слоев треугольников.
Теперь попробуйте представить, как вы отслеживаете линию от своего глаза через пиксель на мониторе, а затем пытаетесь точно определить, какой треугольник (треугольники) пересечется с лучом. Вот почему использование BVH так важно и значительно ускоряет весь процесс.
В этой игре, как и во многих других, которые используют трассировку лучей для освещения всей сцены, BVH включает в себя несколько баз данных двух типов — структуры ускорения верхнего уровня (TLAS) и структуры ускорения нижнего уровня (BLAS).
Первая, по сути, представляет собой обширный обзор всего мира, а не только той маленькой его части, на которую мы смотрим. На ПК с видеокартой Nvidia это выглядит примерно так:
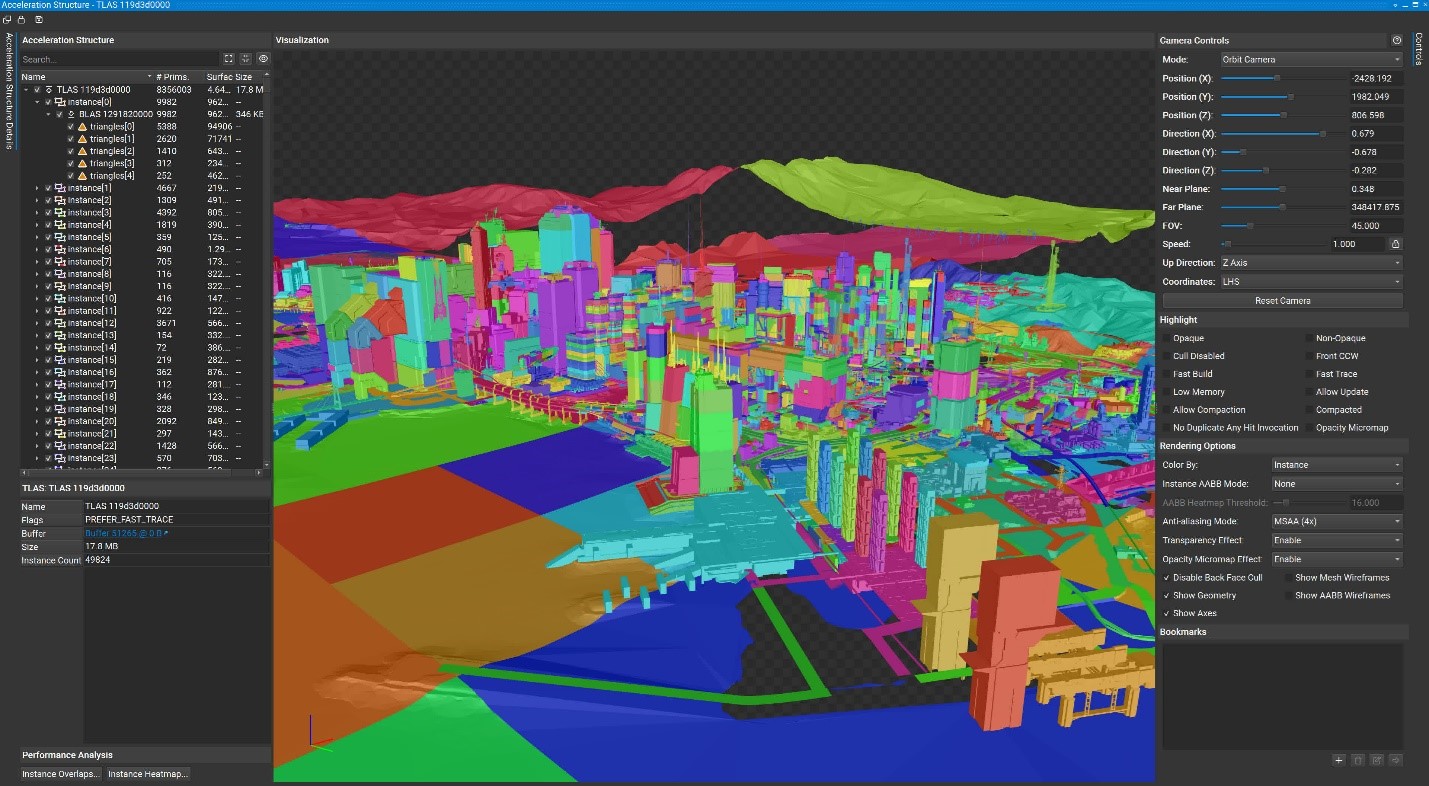
На увеличенном масштабе проще рассмотреть содержимое TLAS, но, как вы можете видеть, он очень большой - почти 18 МБ. Обратите внимание на список разделов, каждый из которых содержит по крайней мере один BLAS. В игре используются только две структуры TLAS (вторая намного меньше), но в общей сложности существует несколько тысяч BLAS.
На изображении ниже представлен элемент одежды, который мог бы носить персонаж из игры. Может показаться нелепым, но такой большой объём BLAS никогда не будет проверен или использован в цветообразующей сцене рендеринга, если этот конкретный BLAS не находится в более крупной родительской структуре, лежащей на пути луча.

В представленных кадрах Cyberpunk 2077 используется в общей сложности 11 360 BLAS, занимающих гораздо больше памяти, чем TLAS. Однако, поскольку GPU теперь имеют большой объем кэша, имеется достаточно места для хранения последнего в этой SRAM и передачи многих соответствующих BLAS из VRAM, что значительно ускоряет процесс трассировки лучей.
Так называемый Святой Грааль рендеринга по-прежнему доступен только тем, у кого лучшие видеокарты, и даже в этом случае используются дополнительные технологии (такие как масштабирование изображения и генерация кадров), чтобы довести общую производительность до играбельного уровня.
BVH, тысячи ядер и выделенные блоки трассировки лучей в GPU делают все это возможным, но чудовищные кэши обеспечивают столь необходимый импульс всему перечисленному.
Претенденты на корону
Как только минует еще несколько поколений архитектур GPU, графические чипы с массивными кэшами L2 или L3 станут нормой, а не уникальным аргументом в пользу нового дизайна. GPU будут по-прежнему использоваться в широких сценариях общего назначения, а трассировка лучей становиться все более распространенной в играх, DRAM по-прежнему будет отставать от развития процессорных технологий.
Тем не менее, GPU не добьются успеха, когда дело доходит до упаковки в SRAM. На самом деле сейчас из этого правила есть несколько исключений.
Мы не говорим о линейке процессоров AMD Ryzen X3D, хотя Ryzen 9 7950X3D оснащен ошеломляющими 128 МБ кэша L3 (самый большой процессор Intel потребительского класса, Core i9-13900K, обходится всего 36 МБ). Тем не менее, это по-прежнему продукт AMD, особенно его последние разработки в серии серверных процессоров EPYC 9000.

EPYC 9684X стоимостью 14 756 долларов (см. выше) состоит из 13 микросхем, в двенадцати из которых размещены ядра процессора и кэш. Каждый из них содержит 8 ядер и 64 МБ фрагмент 3D V-кэша AMD поверх встроенной микросхемы 32 МБ кэша L3. В совокупности это ошеломляющие 1152 МБ кэша последнего уровня! Даже 16-ядерная версия (9174F) может похвастаться 256 МБ памяти, хотя это все равно не то, что можно назвать дешевым — 3840 долларов.
Конечно, такие процессоры не предназначены для использования простыми смертными и их игровыми ПК, а физический размер, цена и показатель энергопотребления настолько велики, что ничего подобного мы не увидим ещё многие годы в обычном процессоре домашнего ПК.
Частично это связано с тем, что в отличии от полупроводниковых схем, используемых в логических устройствах, с каждым новым технологическим узлом (методом изготовления микросхем) становится все сложнее уменьшать размер SRAM. Процессоры AMD EPYC имеют такой большой объем кэш-памяти просто потому, что под охладителем находится множество микросхем.
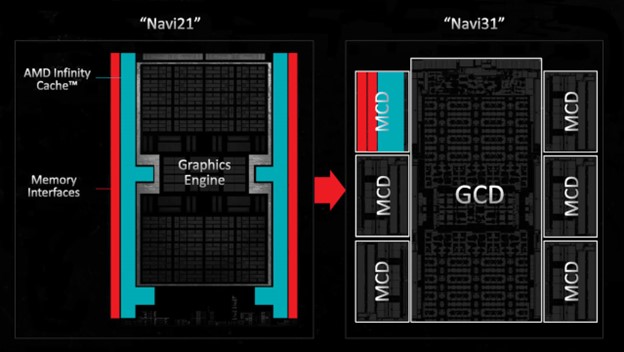
В какой-то момент в будущем все GPU, вероятно, пойдут по аналогичному пути, и топовые модели AMD Radeon 9000 уже делают это, при этом интерфейсы памяти и связанные с ними фрагменты кэша L3 размещаются в отдельных микросхемах по отношению к основной матрице процессора.
Однако преимущества от использования все более крупных кэшей уменьшаются, поэтому не ждите, что GPU будут повсюду иметь кэш объемом в гигабайты. Но даже в этом случае недавние изменения весьма примечательны.
Двадцать лет назад графические чипы имели очень мало кэша, всего несколько КБ SRAM тут и там. Теперь вы можете пойти и менее чем за 400 долларов купить видеокарту с таким большим объемом кэша, что в нее можно было бы поместить весь оригинальный Doom дважды!
Графические процессоры действительно являются королями кэша.